
Crawl budget is the number of URLs Googlebot can and wants to crawl on a given website. Efficient use of your crawl budget is one of the key factors in improving your visibility on Google.
If your pages don’t get crawled, they won’t be indexed and shown in search results.
Why does crawl budget exist?
The World Wide Web is virtually infinite, but Google’s resources are limited. Crawling the web and picking the valuable pages is one of Google’s major challenges.
On top of that, some websites have servers that can’t handle extensive crawling.
What this means for you is that Google won’t visit every page on your website by default. Googlebot can only crawl the URLs it considers to be important enough.
Why doesn’t Google just visit every page on the web?
- Google has limited resources. There is a lot of spam on the web, so Google needs to develop mechanisms that let it avoid visiting low-quality pages. Google prioritizes crawling the most important pages.
- Googlebot is designed to be a good citizen of the web. It limits crawling to avoid crashing your server. For Google, it’s better to skip or delay visiting some of your URLs rather than crash your website’s server.
What’s the risk?
If Googlebot spends resources on crawling low-quality pages on your domain, you risk your more valuable pages not getting crawled often enough. To mitigate this, you can optimize your crawl budget.

How crawling and indexing works
To understand the crawl budget, we have to learn how Google crawls a particular website. This process is determined by three factors:
- Crawl rate limit – how many URLs Google CAN crawl.
- Scheduling – which URLs should be crawled and when.
- Crawl demand – how many URLs Google wants to crawl.
CRAWL RATE LIMIT
Crawl rate is the number of “parallel connections Googlebot may use to crawl the site, as well as the time it has to wait between the fetches.”
Since the Webmaster Central Blog states that “Googlebot is designed to be a good citizen of the web,” Googlebot has to consider your server’s capacity, making sure that it wouldn’t overload it while crawling your website.
Google will adjust the crawl rate to your server’s response. The slower it gets, the lower the crawl rate.

SCHEDULING
The complexity of the crawling process requires Googlebot to create a list of addresses that it intends to visit. Then the requests to the enlisted URLs are queued. This list isn’t random. The whole process is called scheduling, and to prioritize the valuable URLs, Google uses a sophisticated mechanism called crawl demand.
According to the “Method and Apparatus for Managing a backlog of pending URL crawls” patent, every URL gets assigned a crawling priority.
CRAWL DEMAND
This factor determines which pages (and how many of them) Google wants to visit during a single crawl. If Googlebot considers a certain URL important enough, it will place it higher in the schedule.
The importance of a given URL is decided based on:
- Popularity – URLs that often get shared and linked on the Internet will be considered more important, thus will have a bigger chance of being crawled by Googlebot. According to Google’s “Minimizing visibility of stale content in web searching including revising web crawl intervals of documents” patent, the URL’s popularity is a combination of two factors: view rate and PageRank.
- Staleness – Generally speaking, fresh content has a higher priority over the pages that haven’t changed much over the years.
We have seen many examples of how important new pages are for Google, and how adding them can directly influence the crawl budget. For example, one client’s website suffered from a bug that caused a massive increase in the number of URLs. It went up from about 250K to more than 4.5 million in just one second. Shortly, this massive appearance of new pages led to a vast increase in crawl demand.
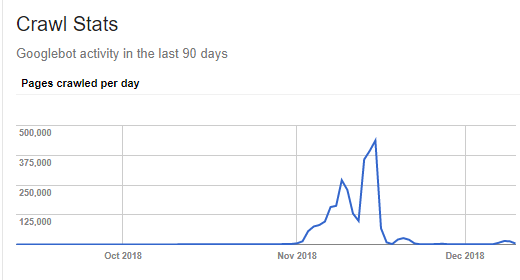
However, it’s worth noting that the impact of new content on the crawl budget was only temporary. Right after all of the new URLs had been visited, the number of pages crawled per day returned to its previous state, even more rapidly than how it increased.
What probably happened in this particular case is that initially, Google saw that there were tons of new URLs to crawl, so it increased the crawl demand. Then, Google realized those new pages were low-quality pages and decided to stop visiting them.

Why the crawl budget is so important
A while back, an intense discussion took place under a tweet where John Mueller from Google stated: “IMO crawl-budget is over-rated. Most sites never need to worry about this.” And if you read the Webmaster Central Blog post that I mentioned before, you probably came across the following statement:

Of course, as an SEO specialist, I can agree that crawl rate optimization is primarily beneficial for large websites (such as big eCommerce shops). From our experience at Onely, if a website contains more than 100K URLs, it’s almost certain that it will suffer from serious crawling issues, and we usually include crawl budget optimization within our technical SEO services for such websites. If you own a large website, you certainly should pay attention to your crawl budget.
If you have a smaller website…
In many cases, you can get away with not caring about the crawl budget. The problem is, you won’t be aware of the situation unless you actually start investigating the matter.
Even if a website seems small at first glance, it might, in fact, contain tens of thousands of URLs. Using faceted navigation can easily transform 100 pages into 10000 unique URLs.
Bugs in the content management system may produce interesting results, too. I’ve recently come across a website that consisted mostly of homepage duplicates and copies of the offer pages. All because a custom-built CMS didn’t have a solution to dealing with non-existing URLs.
Considering all the above, you should definitely evaluate your website’s crawl budget to make sure there aren’t any issues.
Get insights on how the bots are crawling your website
In order to optimize your website’s crawl budget, you need to identify what issues are affecting it. There are several ways you can get some insights on what Googlebot is actually crawling within your website.
GOOGLE SEARCH CONSOLE
GSC is an essential tool for every SEO specialist. It gives you tons of useful information regarding the status of your website within Google. And in 2019, the new version of GSC rolled out of beta. The updated tool offers a lot of useful functions that were described in Tomek Rudzki’s article about the new GSC.
Here are some of the GSC features that can give you valuable information about your crawl budget:
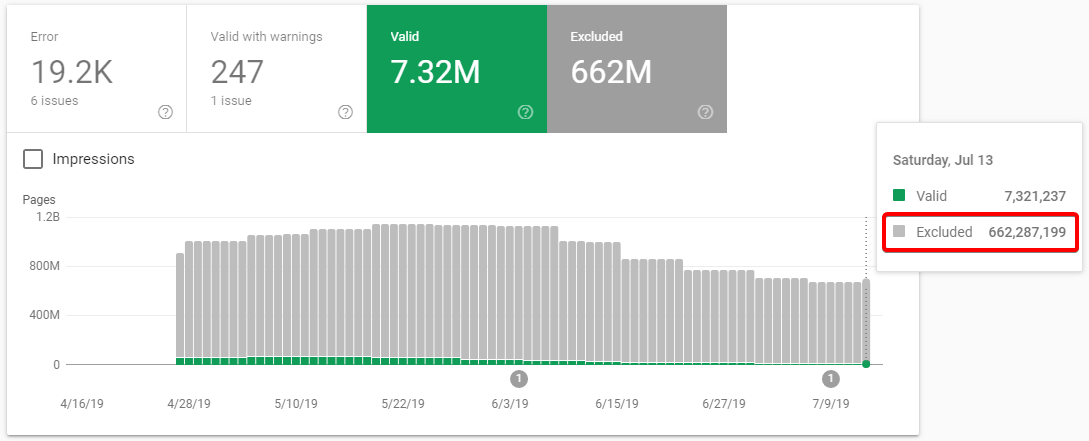
- The Coverage section in Overview will show you a number of indexed pages in the form of a graph. See the huge rise on the screenshot below? Such a rapid increase in the number of indexed URLs should make you suspicious.
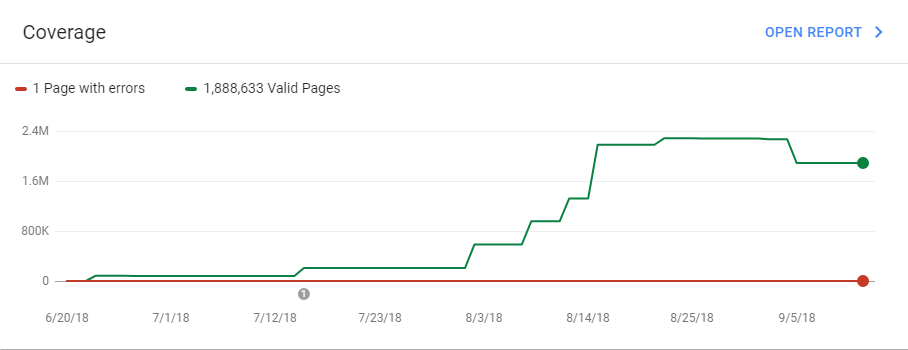
- The Index Coverage report will tell you which parts of the website were visited by Googlebot. This includes both the indexed URLs and the pages excluded from the index (due to canonical or noindex meta tags, or other reasons).
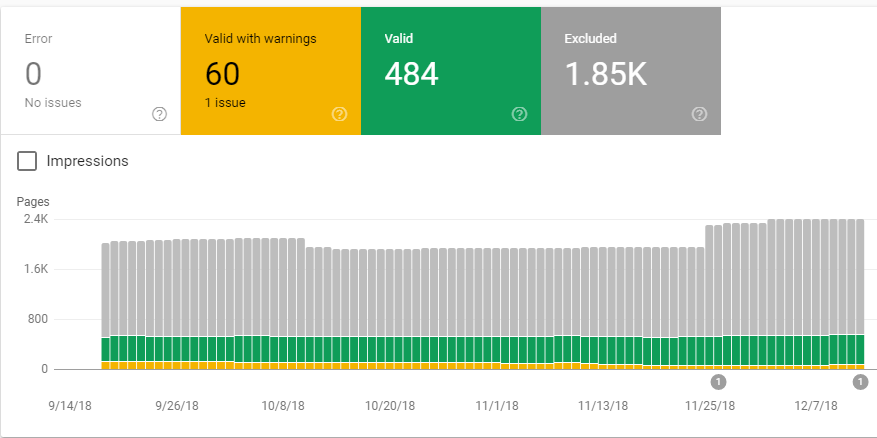
- Crawl > Crawl stats (to access this feature, you need to navigate to the old version of the GSC) will show you how the number of pages crawled per day is changing over time. An abnormal increase in the crawled URLs can be caused by a sudden rise of a crawl demand (e.g., thousands of new URLs suddenly appeared).
SERVER LOGS ANALYSIS
Server log files contain entries regarding every visitor to your website, including Googlebot. By analyzing your server logs, you can find the exact information on what was actually crawled by Google (all JS, CSS, images, and other resources included). If, instead of crawling your valuable content Googlebot wanders astray, log file analysis will tell you about it so that you can react accordingly.
To get a representative sample, you need to extract at least three weeks’ worth of log data (preferably more). Log files can get really big, so you should use an appropriate tool to process them.
Fortunately, such dedicated software exists:
- SEO Log File Analyser by Screaming Frog
- Many SEO crawlers, such as Deepcrawl, Botify, JetOctopus have dedicated modules for server log analysis.
Another option is to use Splunk. It’s expensive, but you can download the trial version for free with no restriction to the file sizes or the number of entries. The trial should be enough for a single SEO project. If you decide to choose this tool, you should definitely check out our article on how to perform a server log analysis in Splunk, and learn to do it like a pro.
How to identify the correct user agent?
Since the log files contain entries of every visitor, you need to be able to extract only the data concerning the Googlebot. But how?
If your idea was to decide based on its user-agent string, I’m afraid that it’s the wrong answer.
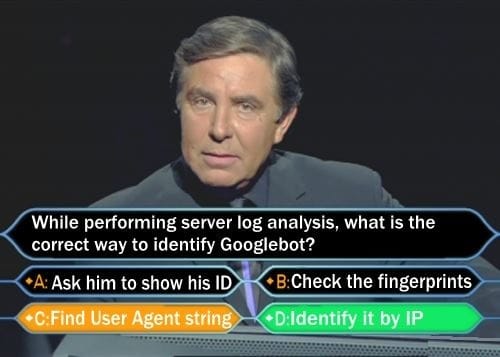
Since everyone can pretend to be Googlebot (by simply changing the UA string in Chrome Developer Tools), the best approach would be to filter Googlebot by IP. We wrote an entire article about identifying different crawlers. But, to make the long story short, the IPs of Googlebot generally begin with: “66.249”.
WHAT SHOULD YOU LOOK FOR DURING SERVER LOG ANALYSIS?
There is a number of aspects you should investigate while performing a server log analysis:
- Status codes. Healthy logs should consist mostly of status 200s and 301s (304s can also appear if you’re using a cache policy). If any other status codes appear in considerably large numbers, it’s time to worry. You should look for 404, 401, and 403 pages, as well as 5xx errors. The latter might indicate serious performance-related issues with your server. A large number of 5xx errors are a clear indication for Google that your server can’t handle Googlebot’s crawling requests. Consequently, the crawling process will be throttled, and Googlebot might not crawl all the pages of your website.
- Most frequently crawled parts of your website. You should check which directories and pages get the largest number of visits. Ideally, bots should primarily crawl the parts where your most valuable content is. For example, if you have an eCommerce website, you want it to visit the product and category pages. It’s common that Googlebot is visiting many low-quality URLs which add little value to your domain.
- URL parameters. By investigating the server logs, you can easily identify all the URL parameters that are being used on your website. That will allow you to configure the bot behavior in GSC. Parameters that don’t change the content of a page (such as sorting by price, popularity, etc.) can be blocked from crawling in your Google Search Console.
How to optimize the Crawl Budget
ROBOTS.TXT
The easiest way to optimize the bot’s budget is by simply excluding certain sections of your website from being crawled by Google using the robots.txt file. If you’re not sure what robots.txt is, I strongly recommend checking the official Google documentation about robots.txt. You can also read this ultimate guide on the subject.
For example, during the log analysis of one of our clients, we found out that instead of crawling the service offer, the bot eagerly spent its time visiting irrelevant calendar pages. “Disallow: /profile-calendar” in robots.txt solved the issue.
Things to keep in mind:
- The Disallow: directive in robots.txt won’t stop the page from being indexed. It will only block access to a certain page from internal links. However, if the bot crawls the URL accessing it from an external source (before it can check the robots directives), the page still might get indexed. If you wish for a certain page not to appear in the Google index, you should use the meta robots tags.
- You should never disallow paths of resources (such as CSS and JS) that are essential for the page to properly render. The bot has to be able to see the full content of your pages.
- After you create a robots.txt file, remember to submit it to Google via Google Search Console.
- While disallowing and allowing certain directories and paths, it’s easy to mess things up and block a necessary URL by accident. Therefore you should use a dedicated tool to check your set of directives.
SITEMAP.XML
According to Gary Illyes from Google, sitemap XML is the 2nd best way for Google to discover pages (number one being, obviously, links). It’s not a huge discovery, as we all know that a properly created sitemap.xml file will serve as feedback for Googlebot. It can find all the important pages of your website there, as well as notice recent changes. Hence it’s essential to keep your sitemaps fresh and free of bugs.
A single sitemap file shouldn’t contain more than 50000 URLs. If the number of unique, indexable pages on your website is bigger, you should create a sitemap index that would contain the links to multiple sitemap files. As you can see in the following example:
- www.iloveonely.com/sitemap_index.xml
- www.iloveonely.com/sitemap_1.xml
- www.iloveonely.com/sitemap_2.xml
- www.iloveonely.com/sitemap_3.xml
A proper sitemap should contain:
- URLs returning an HTTP status code 200;
- URLs having meta robots tags: index, follow; (or other indexable URLs that, for some reason, don’t have these tags specified)
- Canonical pages (in other words, NOT canonicalized to a different page)
Based on Google patents, it may also be beneficial to use additional parameters in your sitemaps, such as:
- Change frequency.
- Priority.
- Last modification date.
You can point Google to your sitemap by using the Google Search Console. It’s also considered good practice to place a link to your sitemap in the robots.txt file, like so: “Sitemap: http://www.iloveonely.com/sitemap_index.xml”
Here’s what you can do now: Still unsure of dropping us a line? Reach out for crawl budget optimization services to optimize the crawling of your website.NEXT STEPS

Common issues affecting the crawl budget and how to solve them
JS AND CSS FILES
Every resource that Googlebot needs to fetch to render your page counts toward your crawl budget.
To mitigate this, ensure these resources can be cached by Google. Avoid using cache-busting URLs (those that change frequently).
You can also use advanced techniques that reduce the negative impact of your scripts, such as code splitting. This way, you can ship Google only the necessary code, which leads to a less resource-consuming rendering process.
POOR SERVER PERFORMANCE
As previously stated, the crawl rate is adjusted to your server capabilities. Poor website performance can result in the server being easily overloaded, and a decreasing number of visits received from Googlebot as a consequence. We observe a direct correlation between the number of pages crawled per day and the time spent downloading a page.
INTERNAL REDIRECTS
Every time a bot encounters a redirected URL, it has to send one additional request just to get to the final URL. At first glance this might not seem like a big deal, but think about it this way: if you have 500 redirects, it’s actually 1000 pages to crawl.
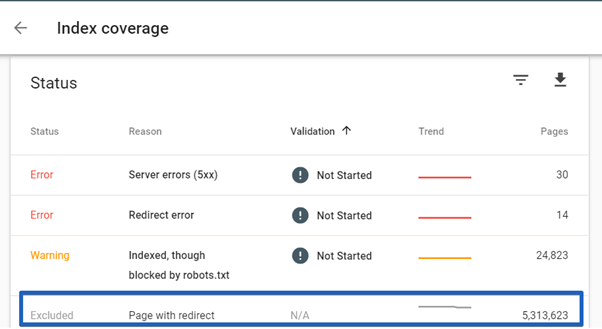
And 5313623 redirects is actually 10627246 pages to crawl
And that’s only in the case of single redirects. Sometimes we find longer redirect chains, such as the one you can see below:
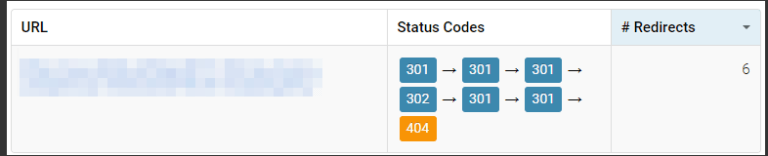
As you can see, there are six (!) redirects involved, and the end result is a 404 error page. The funny thing is that Google probably won’t get to this 404 page, as it follows up to five redirects on a single URL.
In other words, it means that your redirect eventually doesn’t work and is reported as “Redirect error” in Google Search Console.
You cannot avoid having redirected URLs pointing to your website from the outside sources (in fact, you should use a 301 to make sure your content is still accessible if the link isn’t up to date), but you have to make sure that after entering your website, the bot won’t encounter any redirected internal URLs.
How to take care of internal redirects
- Perform a full crawl of your website with one of the many tools such as Ryte, DeepCrawl, SiteBulb, or Screaming Frog. Never used crawlers before? Then you should definitely visit our Beginners Guide To Crawling (and if you’re struggling with which crawler to choose, please read The Ultimate Guide to SEO Crawlers).
- After the crawl, identify the redirected URLs that the tool encountered, as well as the source page where the given link is placed. In Screaming Frog, you can use Bulk Export > Response Codes > Redirections (3XX) Inlinks for redirects, and Redirect & Canonical Chains report to find redirect chains (and check out this link if you wish to learn how to export such data in Sitebulb):
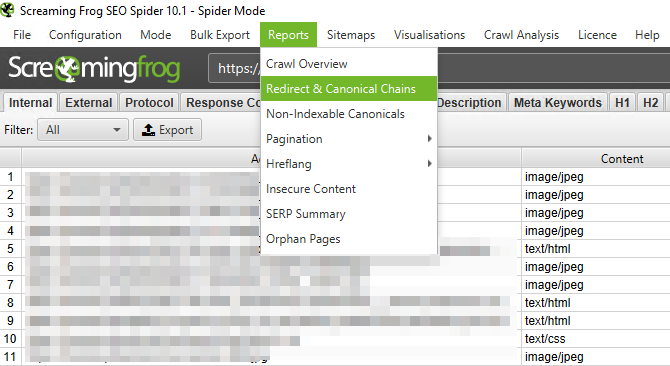
- Update the links found on the source pages so that they all point to the destination URLs (HTTP status code 200) directly.
BAD INFORMATION ARCHITECTURE
A well-thought, logical structure of the website is a very important element of SEO. Therefore, it’s when you may take advantage of our information architecture services.
Also, here’s a list of fairly common IA issues that can have a huge impact on the crawl budget.
Duplicate pages
Having content copied over a number of pages not only results in a duplicate content issue, but it can also negatively impact crawling, as duplicate pages take space in the crawling schedule. There are several categories of duplicate content that are worth addressing:
Unnecessary non-canonicals using canonical links isn’t a bad thing by itself. In fact, it is recommended by Google as a way of dealing with duplicate content. However, you have to keep in mind that every canonicalized page is problematic (why crawl a duplicate when the bot might spend this time visiting a more valuable page?). Additionally, while visiting a duplicate, the bot needs to compare it to the canonical page and make sure it actually is duplicate content. This results in yet another unnecessary set of requests sent to the server.

Which John Malkovich is canonical?
Therefore you should always ask yourself the following questions to see if the duplicate page is really necessary:
- Does it improve navigation?
- Does it serve any actual purpose?
- Would replacing it with the canonical page create any issues?
If all the answers are no, then maybe you should consider removing the duplicate page and replacing all the internal links with those pointing to the canonical one. In such a case, you should also remember to redirect (by using the HTTP status code 301) the URL of the removed page to the original.
You should only leave duplicate, non-canonical pages in your website’s architecture if they’re absolutely necessary. Similar principles apply to noindexed pages, as a large number of them can also affect the crawl budget.
Then there are random duplicates. Sometimes you might not even be aware that your website contains a number of duplicate pages. This might be the result of a bug, misimplementation, or it might simply be caused by the way a CMS handles URLs.
This can easily be identified by typing site:yourdomainname.com in Google search and digging in the index. Or just go to your GSC>Coverage>Excluded and look for duplicate content.
If the number of pages you find is surprising to you, you first need to figure out why they are there. Then, several actions must be taken:
- Deindex duplicates by placing noindex, follow meta tags in the code. Don’t block them in robots.txt yet, as this would prevent the bot from revisiting and deindexing the pages.
- Only after all the problematic pages have been deindexed should you block the appropriate path in robots.txt.
- After that, you should remove the pages in question from the website, and redirect deleted URLs to the canonical version.
If you have duplicates that have never been indexed or didn’t get any links from outside sources, you can simply remove them and use status code 410, instead of redirects.
Google Search Console notified you about indexing problems due to duplicate content? Read our guides and fix:
- the “Duplicate, Google chose different canonical than user” status,
- the “Duplicate without user-selected canonical” status.
Infinite space
Remember that calendar issue I mentioned earlier? That calendar had a unique URL assigned to every month. And on every month page, there were just two links: the first pointed to the previous month’s page and another linked to the next. You could browse back to the dark ages (if you had the patience), or book a service for April 1st, 2100. As a result, Googlebot could be trapped in an infinite crawling process simply by following the link to the next month. This is a perfect example of infinite space.

Book our service for August 2682! Better do it now, while you still can.
If your website currently contains infinite spaces, you should first consider if you really need such pages. If not, after removing them, make them return HTTP status code 410. If those infinite spaces are necessary, you have to make sure that the bot won’t be able to crawl or index the pages:
- Place the noindex tag in the HTML code;
- If none of the pages were indexed, you can block the infinite spaces in robots.txt. If some pages were already indexed, first you have to wait before Google removes the pages from the index. Only then should you block the path in robots.txt.
POOR INTERNAL LINKING
Internal links create paths used by Googlebot to navigate your website, and a well-developed linking structure will ensure an efficient crawling of your valuable content. On the other hand, a lack of internal links can result in Google being reluctant to crawl certain sections of the website.
While designing your internal link structure, you should avoid these common pitfalls:
- Linking to “Not found (404)” error pages – you don’t want to send Googlebot to non-existing pages.
- Orphan pages – pages that are present in the sitemap, but haven’t been linked to internally. Googlebot might decide not to visit them that often.
- Pages with a long click path – make sure your most important content is available no further than three clicks from your strongest page (which, in most cases, will be the homepage). We already know that for Google, the place of a given page within the website’s architecture is far less important than the click path.
- Spammy links – often placed in the footer section or at the bottom of the page, dozens of links having keywords stuffed in the anchor text. Such links will be largely ignored by Googlebot and won’t add any value to your pages.
Visualizing the structure of internal links can help you identify the areas you can potentially improve. You can learn how to do it using Gephi. However, some popular SEO crawlers such as Screaming Frog, SiteBulb, and Website Auditor also enable such features.
While improving your internal link structure, you should follow these best practices:
- Your most important pages should get the largest number of internal links.
- Link to related topics (in the case of articles) or related products/categories (in an eCommerce store). Let your content be discovered; Make sure those links really connect related content – to satisfy both users and Googlebot.
- Contextual links inside articles add value for both users and search engines (Googlebot will use anchor texts to better understand the website’s structure);
- Don’t over-optimize – the anchor text should be natural and informative, don’t stuff it with unnecessary keywords.
- Don’t just stuff the page with links – make sure they add the actual value for users.
You may also benefit from reading our post about developing navigation on your website.
BUGS IN THE SITEMAP/LACK OF XML SITEMAP
If your website currently doesn’t have an XML sitemap, you should definitely build one according to the guidelines I described earlier in the article, and send it to Google via GSC. Since it will help Googlebot in discovering new content and scheduling the crawl, you have to be sure that all your unique, indexable pages are listed in the file. Also, you should always keep your sitemap fresh.
The best way to see if your sitemap is properly structured is to use an SEO crawler. Most available tools (including Screaming Frog, SiteBulb, Ryte, Deepcrawl) will give you the option to analyze sitemaps while performing a full crawl.
Wrapping up
After a long journey, we have finally reached the end. I hope that at this point, you have a good understanding of the crawling process. All the information you got from this article can be used while working on your website. If you keep to the best practices, you will ensure efficient crawling, no matter how many URLs your website has. And remember, the larger your website is, the more important the crawl budget becomes.

Hi! I’m Bartosz, founder and Head of Innovation @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with your organic growth – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!







