A lot of small website owners would like to see their website ranking highly on Google, but outside of making a cool looking website, having it hosted, and using social media, they might leave the rest to chance. And when they read about SEO, it can often feel like trying to translate the Necronomicon (which, by the way, you’re not supposed to do!). The reality is, learning about how search engines see your website and then using this information to optimize your website is actually easier – and cheaper – than you might think.
SEO and P-Lettered Animals
Before I started working with digital content at Onely, I never even heard of SEO (Search Engine Optimization). Initially, I thought it was the secret person who really ran a large company, but it seemed weird to have a whole industry devoted to people who are supposed to be working in secret.
And my relationship with Google was pretty much the same as the average online user: I have been actively allowing it to destroy the formation of any long term memory by asking Google the typical questions we all ask in our daily lives: What are the best places to eat? Can you scream at a koala bear? How old are my kids?
Now I know that despite Google’s inherent simplicity, search engines are incredibly complicated tools, so much so that the SEO industry was created to pretend to understand it. Google was even nice enough to play along and try to make it look easy for all of the people pretending to understand it by giving their complicated algorithms cute names like Panda (AKA Brand Plummeter) and Penguin (AKA Life is Meaningless). And now you have an entire industry of seemingly intelligent people running around and saying P-lettered animals a lot and then other industries giving them large amounts of money.
With all of these big words and animals being thrown around, you can see why the average internet user like myself would not know anything about SEO. So it should come as no surprise that I didn’t know anything about crawlers either.
What is a Crawler?
A crawler is a program that visits websites and indexes them for search engines. All search engines utilize crawlers, sometimes referred to as bots or spiders. The crawlers travel the web one link at a time to form a catalog that helps us navigate the internet.
But crawlers aren’t something exclusively used by search engines. You can use one to crawl your own website.
Why Should I Crawl My Website?
By using a crawler, you’re given a glimpse of whether or not Google and other search engines can crawl AND index your website. This isn’t a facsimile of how search engines see your website, but rather a detailed impression that you can use to look under the hood of your own website so that it can perform better for search engines.
It’s important to remember: if Google can’t crawl your website, that means it’s not going to rank, and no one will be able to find it. So remember the old Buddhist proverb: If a website is not crawled by Google, does it exist?

The answer, by the way, is no.
Consider this. You own a small business, and you’ve put together a small website. You might have hired someone to do this, but more often than not, people are turning to CMSs (Content Management Systems) like WordPress to build their own sites (Fun fact: 30% of websites are now powered by WordPress).
Because building your own website is now easier than ever, a lot of the more technical aspects of web design tend to be forgotten in the pursuit of making something cool. So you, this hypothetical small business owner, have designed an incredible website, and you put it online for the whole world to see. It’s only a matter of time before the big bucks start rolling in.
However, you may have neglected some basic SEO aspects that would make Google’s ability to crawl your website difficult to impossible. And this isn’t your fault. How are you supposed to know about any of this? Google had always worked for you when you asked it questions (my kids are 5 years old, by the way! Thanks, Google!), so naturally, it should work for others when they need your services.
Sadly, it doesn’t work that way. Imagine that you’ve built the coolest store in the entire world filled with the coolest things to sell – in the middle of the woods. You’ve turned on the lights and opened the doors, and you’re ready for business. But because you didn’t put any signs up anywhere to guide people to your store, the only customers you’ll get is the occasional bear that accidentally wanders in.
You wouldn’t make this kind of mistake in real life, so there’s no reason to do it online.

Understanding SEO and how search engines work is closer than you might think. And by crawling your website, you can reverse engineer some things that will make it easier for your website to stand out from the crowd.
Let’s Get Crawling…
In the interest of content science, I am going to crawl my own personal website for the very first time and write about it. For the purposes of this article, I will be using Ryte.com.
Ryte, which labels itself as “Website Quality Assurance Software,” is essentially a crawler that you can use to peek under the hood of your own website.
It is a paid tool offering comprehensive services through monthly paid plans. However, they offer a free version – which is great, because this will help me to overlook the fact that they misspelled right. How embarrassing!
Since I’m approaching this as a beginner with a small website/business, we will be using the free version of Ryte, which should be more than enough to get us started (especially if you have a small website).
Getting it Ryte
Go to Ryte.com and look for Register for free on the upper right hand side.
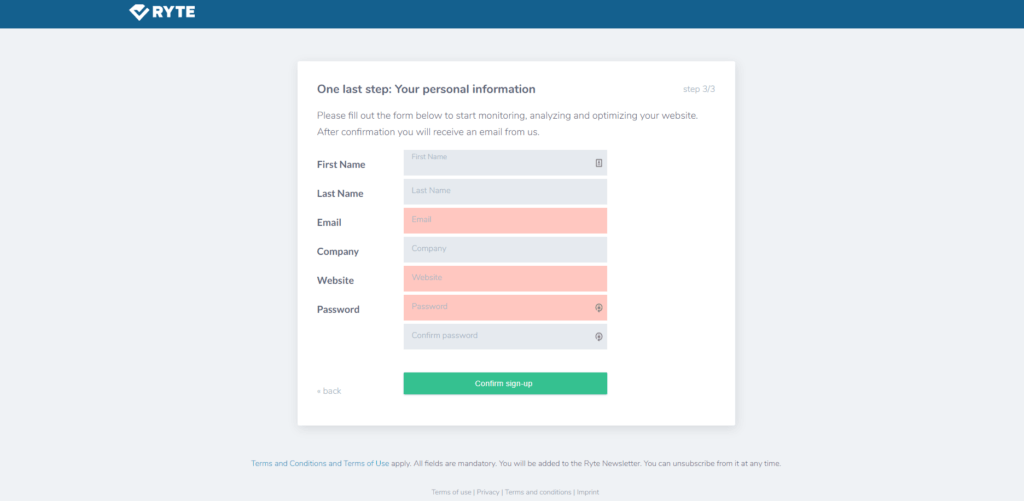
You need to answer some questions, and then you’ll get to this page asking for the basics, like your name, email, etc.:
After you’ve confirmed your email address and everyone agrees that you are who you say you are, we can start your analysis.
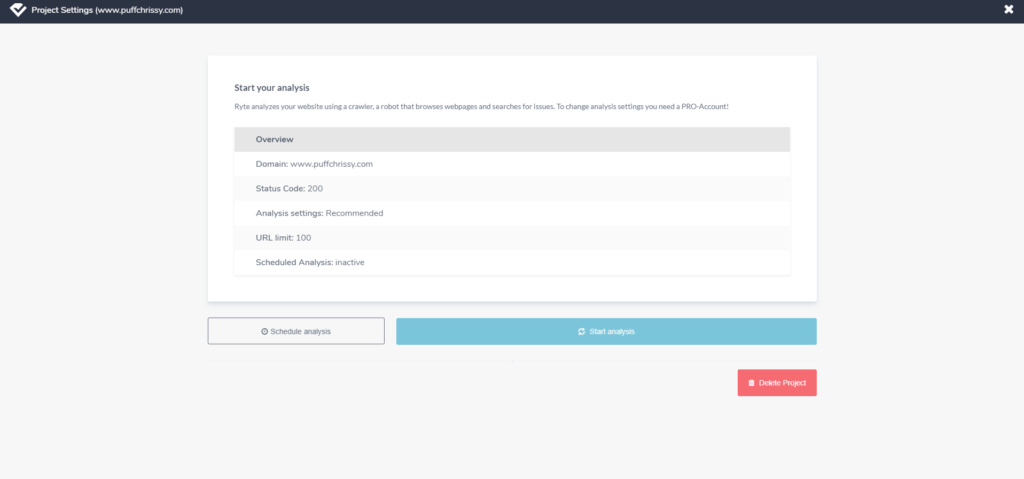
A little warning is necessary here: Once you click Start analysis, depending on the size of your website, it might take a while. In some cases, it could take hours. Ryte is savvy enough to send you an email when the analysis is complete. In my case, it took about 20 minutes.
As a reminder, this is the free version, so Ryte is only crawling a maximum of 100 pages. This is good news for those with much smaller sites with less than 100 pages. For comparison, with the paid version, it took Ryte about a day to crawl my entire website.
PROJECT DASHBOARD
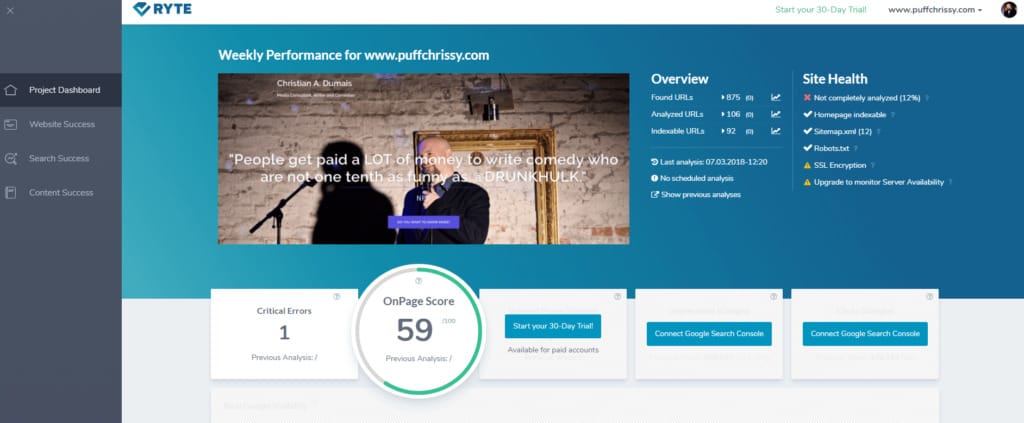
My OnPage score is 59%. If this were a test grade in the United States, I would probably have to take my website home and have my parents sign it. Luckily I’m writing this in Poland, so a 59% would be considered a satisfactory test grade. Either way, there’s definitely lots of room for improvement.
Of interest, here is the score for the paid version, which you’ll note – despite the number of critical errors – is comparable:
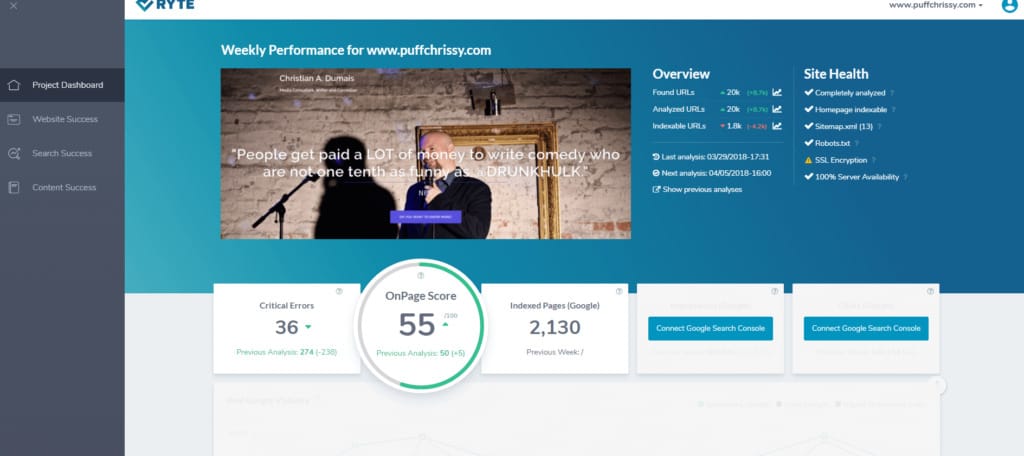
WEBSITE SUCCESS
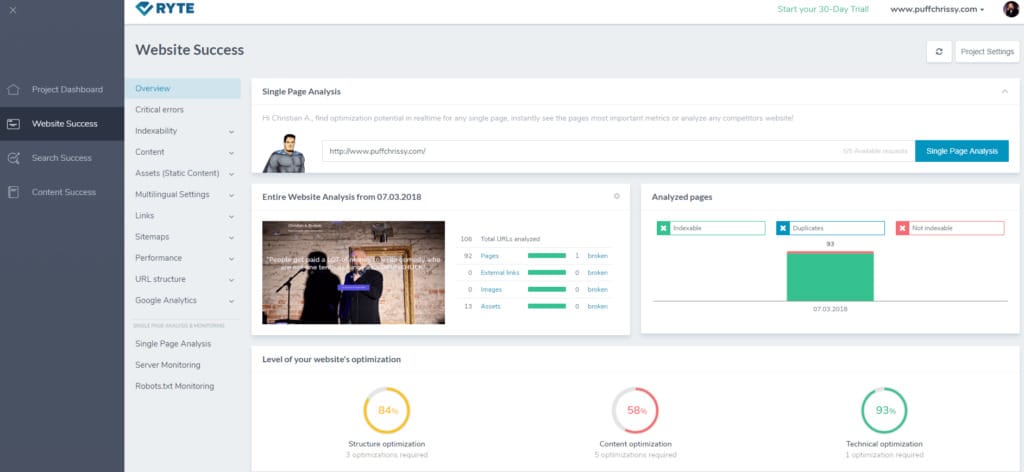
This page gives me a lot more information. The first thing you notice is that Structure optimization is at 84% (yay!), Content optimization is at 58% (boo!), and Technical optimization is at 93% (yay!). Man, this section is a roller coaster of emotion.
Looking upward, we can see Entire Website Analysis. Even though Ryte only crawled 100 pages of my website, this snapshot should give me a good indication about what I need to do regardless.
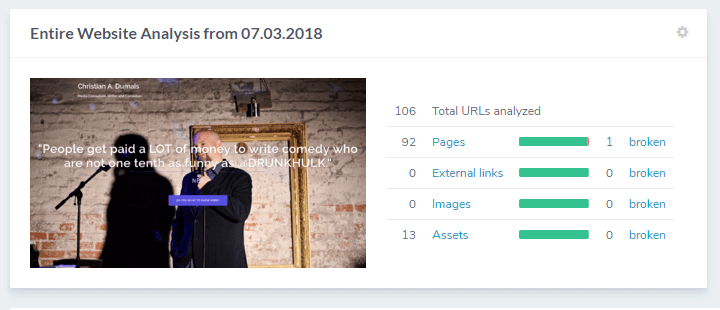
In this case, there was one broken page out of the 92 pages it crawled (better a broken page than a broken heart, amirite?).
Let’s click broken to get more information.
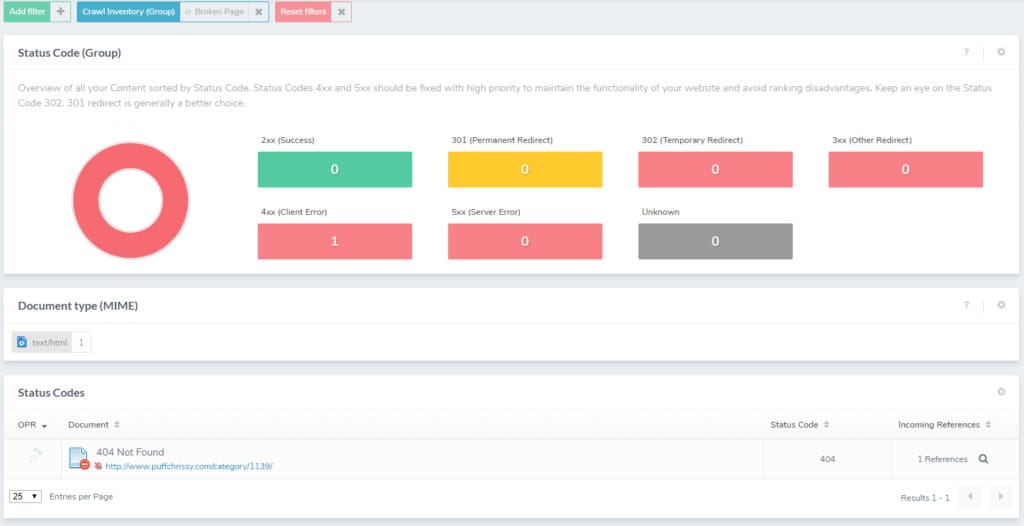
This page shows the exact broken page, which gives me a lot of information to work with.
Recently, I restructured my entire website from a blog-centric site to one that actively promotes my work. Because of this, the blog is no longer used; however, I kept all the old posts anyway. I also discontinued the main menu, so now crawlers have no way of directly accessing the blog posts.
It’s important to remember, as clever and smart as Googlebot appears, it is still a machine that only knows how to go from one link to the next, and if you don’t lay out the path for it (like a menu or breadcrumbs), it will eventually give up on your website.
On top of that, when the site was just a blog, I reconfigured the permalinks from http://www.puffchrissy.com/%category%/?p=123 to http://www.puffchrissy.com/%postname%. And this created a mess that I’m just now discovering; hence, the example Ryte provided for me.
To fix this problem, I simply had to go through my posts and redirect the “Not found (404)” pages to the updated link. But now that I know this problem exists, I can seek out similar links with outdated permalinks on my website. I was able to find over 50 more such examples of 404s, and I’m sure there are even more.
Going back to the previous page, we can see this:
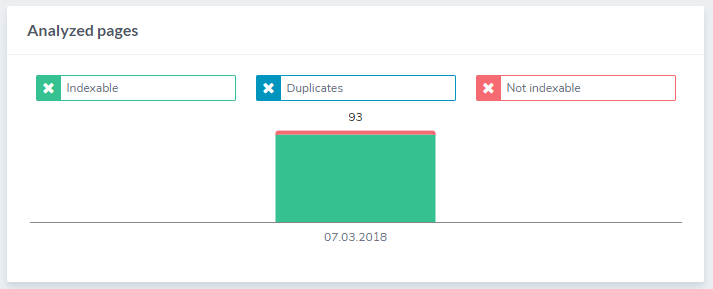
This gives me a visualization of which of the analyzed pages were Indexable, Duplicates, and Not indexable. This tells me what I already knew from before, but the good news here is that there are no duplicates.
Now let’s scroll down and look at some more problems.
As you can see, anything with a green check-marked box on the right hand side is a good thing, while the blue boxes with a minus sign is considered bad.
The first category that is immediately noticeable is “Indexable pages with long click path”. I have 91 issues (that’s enough to open my own newsstand!) that need to be resolved. When I click it, it lists all 91 URLs.
What does “Indexable pages with long click path” mean? Well, Ryte is telling me that the amount of clicks it takes for the user to get to the cited examples from the home page is too great, as you want the distance (amount of clicks) to be as minimal as possible. It’s supposed to be as the crow flies for users and bots.
Another thing I noticed by looking at all those old blog links is how long some of those URLs are. Back in the day, I didn’t think twice about titles or how they looked as links, so a link like http://www.puffchrissy.com/category/sample-of-%e2%80%9con-being-velma-less%e2%80%9d-from-empty-rooms-lonely-countries/ didn’t bother me.
Now when I look at this link, I’m horrified in the same way I am when I reflect on my fashion choices in the 90s.
This particular page had an excerpt from one of my short stories, “On Being Velma-less” from my book Empty Rooms Lonely Countries (shameless plug!).
Clearly, I need to go back and edit these links to a more manageable length. I might also consider optimizing my website archives.
I’m changing the category so that instead of the generic category, it reads erlc, this way, I can remove empty-rooms-lonely-countries from the link. In the end, the address will simply be http://www.puffchrissy.com/erlc/on-being-velma-less/. That’s so much better. And while our eyes can appreciate it, Googlebot will find it a lot easier to digest too.
Other SEO issues that my site needs to address include Indexable pages with more than one H1 tag (who knew that those headers mattered?), Indexable pages without a unique meta title, Indexable pages with less than 300 words (crawlers just don’t care for haikus!), and Indexable pages without Twitter Preview Image; all of which I could have avoided if I had installed the Yoast SEO plugin into my WordPress site, which would have at least warned me about these things.
Website Success also has a handy menu on the left where you can look at Critical errors in more detail by categories like Indexability, Content, Links, Performance, and more.
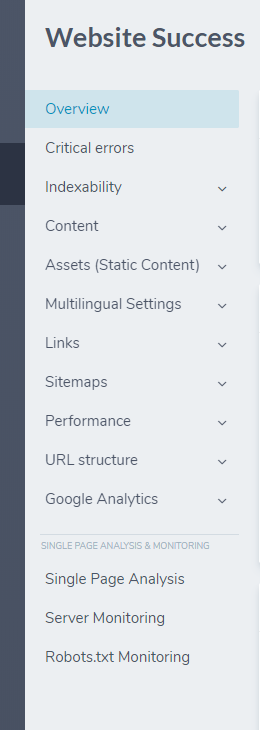
Luckily for me, I didn’t have any significant problems here. I had no Duplicate Content. My Load Time was fast. My File Sizes are small. It even told me that I look handsome while I’m sleeping, which is kind of weird, but okay, thanks, Ryte.
And just when I was beginning to feel pretty good about myself, I clicked Single Page Analysis.
For the free service, you have the ability to analyze five specific pages from your website. I decided to start with my website’s homepage:
It wasn’t too bad…but not great either.
My primary errors were:
- URLs with SSL do not redirect correctly
- There are too many main Headlines
- Some images do not have an Alt Attribute
While these are serious errors, it could have been much worse.
My secondary issues (warnings) included:
- There are too many JavaScript files embedded
- Remove inline CSS
- There are too many CSS files embedded
- Move inline JavaScript to a central script file
- Check the language settings
- Some images lack width or height attributes
Despite the 3 issues and 12 warnings, I got off pretty easy, all things considered. I still have some work ahead of me, but it’s nice to have some concrete information to get me started in the right direction.
SEARCH SUCCESS
This section, unfortunately, requires you to have a paid account. That said, it wouldn’t hurt for you to access Google Search Console to get some of the information offered here.
Speaking of Google Search Console, you can link to and access it on the Project Dashboard.
CONTENT SUCCESS
In this section, you can create a Content Optimization Report.
The section “analyzes terms that are used often within the top ranking results in Google to a given Keyword.” It does this by utilizing TF*IDF. Now sharp-eyed readers who frequent our site already know about this algorithm, as it was wonderfully explained by Bartosz Goralewicz in his article about TF*IDF algorithm:
Gather words. Write your content. Run a TF*IDF report for your words and get their weights. The higher the numerical weight value, the rarer the term. The smaller the weight, the more common the term. Compare all the terms with high TF*IDF weights with respect to their search volumes on the web. Select those with higher search volumes and lower competition. Work smart.
Bartosz goes on to explain how this section of Ryte works in detail. And once you get your head around it, it opens up a whole new world of possibilities for your website and its ability to draw in specific customers.
WRAPPING UP
While there are other crawlers to choose from, I chose Ryte because of its accessibility and affordability, especially for small website owners like myself. And while the free version of Ryte doesn’t give me the whole picture that the paid service would certainly provide, it’s enough for me to form a plan of action for my website moving forward, which was more than I had before I started writing this.
While SEO might seem impenetrable for newbies, you might be surprised by how much you can do on your own and on the cheap. And by embracing the more basic aspects of SEO, it can provide you with a different perspective of your website – one that you might never have considered – to help you shape it into a bright shiny beacon that will attract the attention of bots and customers alike.
We will gladly dispel all your doubts and concerns, so if there’s a need, don’t hesitate to check Onely’s technical SEO services.