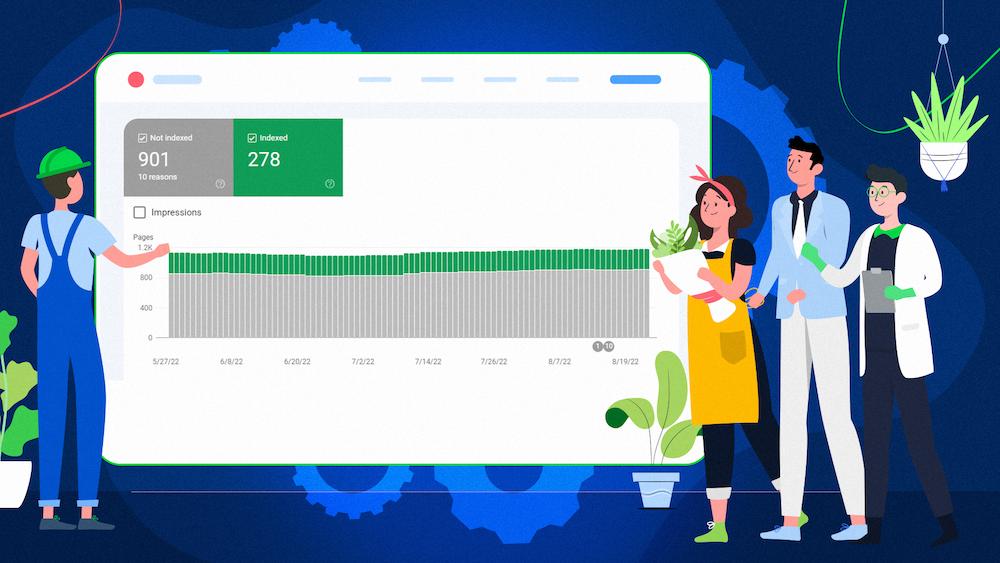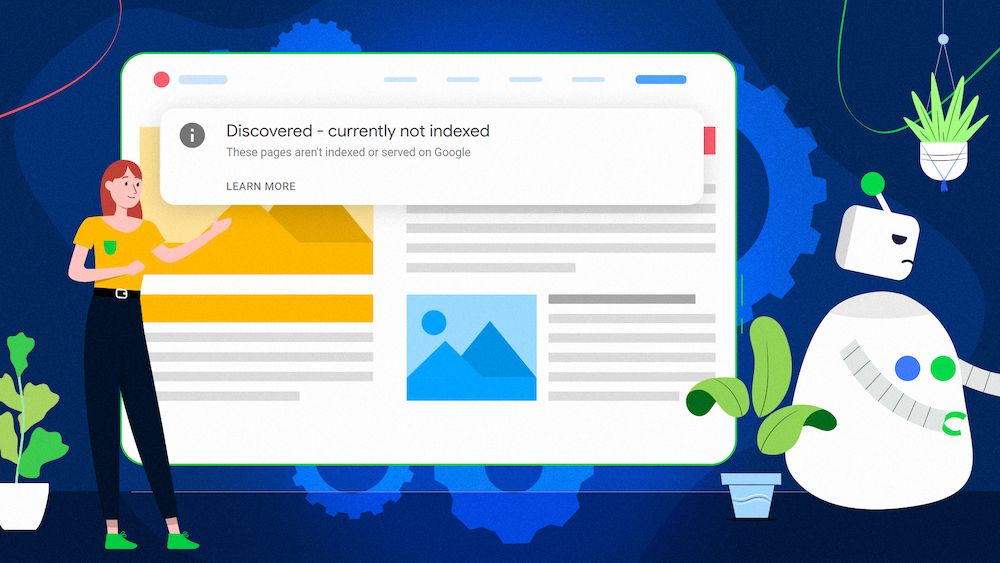
“Discovered – currently not indexed” is a Google Search Console status. It means Google knows about a given page but didn’t crawl it, and it’s currently not indexed.
There are three causes for “Discovered – currently not indexed” URLs: content quality, internal linking, and crawl budget.
Each issue has different solutions. Let’s take a look at them.
What does the “Discovered ‐ currently not indexed” status mean?
“Discovered ‐ currently not indexed” means two things. One, Google has found your page. Two, Google has not currently crawled and indexed your page.
Google’s Search Console help page mentions the reason why:
This doesn’t mean your content will never get crawled and indexed. As Google’s documentation states, it’s possible that Google will return to crawl your page later without any action on your end.

However, Google rescheduling the crawl is only one of several possible reasons for this problem.
Let’s explore each possible cause for “Discovered ‐ currently not indexed” and how to address them to improve your SEO.
7 solutions for “Discovered – currently not indexed” URLs
1. Fix content quality issues
Google cannot crawl and index everything on the web. Each site must meet a quality standard to be in the running. Google will focus on crawling pages of higher quality and may skip crawling low-quality pages altogether.
So, if your content isn’t crawled and indexed, you may need to address its quality.
This doesn’t just apply to pages reported as “Discovered ‐ currently not indexed”; it could also be about the quality of the whole site. John Mueller from Google mentioned that “Discovered ‐ currently not indexed” could be caused by a site-wide content quality issue.

You can’t know exactly how Google rates the quality of your website. But there are several things that you can do to start addressing this issue.
- Go through the Quality Rater Guidelines.
- Ensure each affected page contains unique content.
Read the Quality Rater Guidelines
I recommend that you look through Google’s Quality Rater Guidelines. The Quality Rater Guidelines details how to rate the quality of webpage content.

Our article on the Quality Rater Guidelines sums up the guidelines. Look through it to aid your understanding of quality web content as defined by Google. You can then apply Google’s idea of quality to your pages.
If you want to dive deeper into the topic, check out our article on E-A-T. This is a concept used in the Quality Rater Guidelines to determine the expertise, authoritativeness, and trustworthiness of a webpage.
And if you struggle to fully demonstrate your expertise to Google, contact us for our E-A-T SEO services.
Ensure you have unique content
Google may ignore your URLs if it thinks they are duplicates. Because Google’s resources are limited, it puts emphasis on crawling (and indexing) the most valuable URLs. That entails having unique content that targets specific user intent.
Check your affected URLs to make sure that:
To sum up what John Mueller said, double-check your website for duplicate content. If you have duplicate content, check out our article on how to optimize duplicate content. If you have a lot of similar URLs, consider using canonical tags. These tags tell Google to only index the primary version of your page.

Remember that Google can ignore improperly created canonical tags. If Google ignores your canonical tag, you can spot it thanks to the “Duplicate, Google chose different canonical than user” status in GSC.
Go through the list of affected URLs and make sure that each page contains unique content.
This will increase the likelihood of having your page crawled and indexed. Plus, it will add to your website’s quality and increase user satisfaction.
2. Follow internal linking best practices
Googlebot follows internal links to discover different pages on your site and understand their connections. Internal links also help spread PageRank, a signal of page importance used in ranking.
Suppose Google doesn’t find enough links coming to a URL. In that case, it may skip crawling due to insufficient signals pointing to its importance. Google may assume that pages with poor internal links are unimportant. As a result, these pages may fall under the “Discovered ‐ currently not indexed” status.
Proper internal linking involves connecting your pages to create a logical structure. This structure allows search engines and users to understand the hierarchy of your pages and how they connect.
By properly using internal linking, you both help Googlebot find all your content and improve its chances of ranking high. In the context of fixing “Discovered ‐ currently not indexed”, linking internally to pages that weren’t crawled and indexed improves their chances of getting picked up by Google.
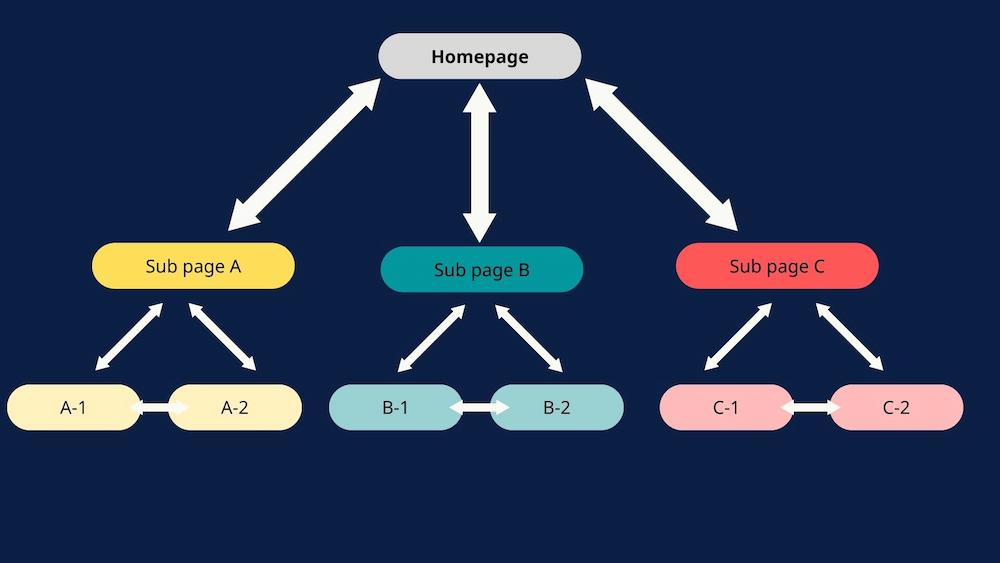
Some of the best practices for internal linking include:
- Decide on your core content and link other pages to it
- Apply contextual links within your content
- Link pages based on hierarchy, e.g., link core pages to supplementary pages and vice versa
- Don’t spam your website with links
- Don’t over-optimize anchor text
- Incorporate links to related products or posts
- Add internal links to unintentional orphan pages
Want to know more? Check out our article on internal linking.
You can also contact Onely for internal linking optimization.
A crawl budget is the number of pages Googlebot can and wants to crawl on a website. The factors that determine a site’s crawl budget are: Any website can suffer from crawl budget issues. However, they are prevalent with large websites. The larger a website is, the more likely it is to have un-crawled pages because of an insufficient crawl budget. “Discovered ‐ currently not indexed” is often a consequence of crawl budget issues. It’s simple – if the crawl demand is too low or the crawl rate is limited, some of your pages won’t get crawled. Many factors can cause crawl budget issues, including: We’ve already gone through the importance of internal linking. Now, let’s address the other factors causing crawl budget issues. Before you move on, learn about the importance of crawl budget optimization
3. Prevent Google from crawling and indexing low-quality pages
Letting Google go through your entire website without restrictions has two negative consequences.
First of all, Googlebot will visit every page on your website until it runs out of its crawl budget. If Googlebot crawls low-quality pages, it may reach its crawling limit before it gets to your most essential pages.
Secondly, if you let Google crawl and index low-quality pages, it may think less about the quality of your entire website. This can damage your rankings but also decrease crawl demand, creating a vicious cycle of crawl budget issues.
Low-quality pages include:
- Outdated content
- Pages generated by a search box within a website
- Duplicate content
- Pages generated by applying filters
- Auto-generated content
- User-generated content
If you already struggle with unindexed content, you should prevent Google from crawling and indexing those pages.
Block low-quality pages from crawling in your robots.txt file and use the noindex meta tag to prevent indexing.
Need to decide on your indexing strategy? Check out our article on how to create an indexing strategy for your website.
4. Create an optimized sitemap
An optimized sitemap can guide Googlebot through the crawling and indexing process. It’s essentially a map for Google to use to get through your content.
But, if your sitemap is not properly optimized, it can negatively impact your crawl budget and lead to Googlebot missing your important content.
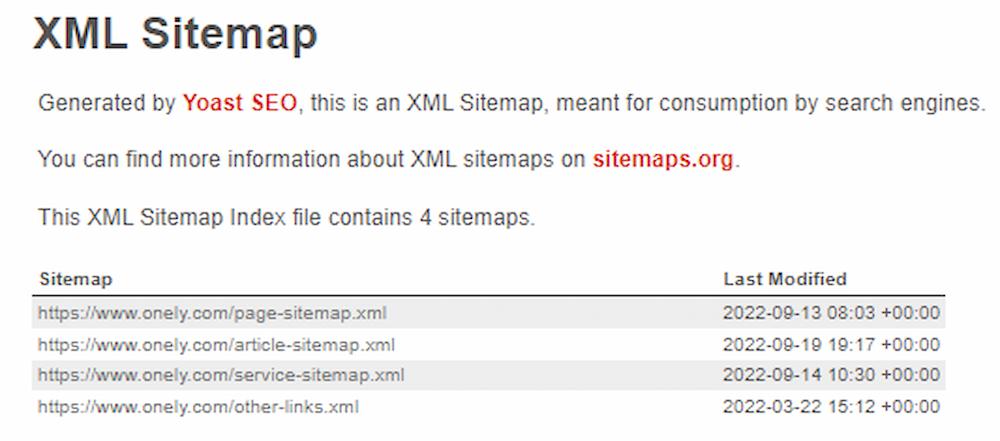
A sitemap should contain:
- URLs responding with 200 (OK) status codes
- URLs without meta robots tags blocking them from being indexed
- Only the canonical versions of your pages
The below screenshot is an example of an XML Sitemap Index file.
If you want to know more about optimizing a sitemap, check out this ultimate guide to XML sitemaps.
5. Fix redirects
You need to avoid redirect chains and loops.
Redirect chains are when you want to redirect traffic from page A to page B but unnecessarily redirect to page C first.
Redirect loops are when you create a redirect chain that starts and ends on the same page, trapping users and bots in an endless loop.
Both redirect chains and loops force Google to send multiple unnecessary requests to your server, reducing your crawl budget.
And, in the case when your redirects don’t work properly, they may end up within the “Redirect error” status in Google Search Console.
To avoid spending your crawl budget on unnecessary redirects, don’t link to redirected pages. Instead, update them so they point to 200 OK pages.
Also, always make sure to stick to the best practices for implementing redirects.
6. Fix overloaded servers
Crawling issues may happen because your server is overloaded (responding slower than expected). If Googlebot cannot visit a certain page because your server is overloaded, it will scale back its crawling activity (crawl demand). This may lead to some of your content not getting crawled.

Google will attempt to revisit your website in the future, but the whole indexing process will get delayed.
You should check with your hosting provider for any server issues on your site.
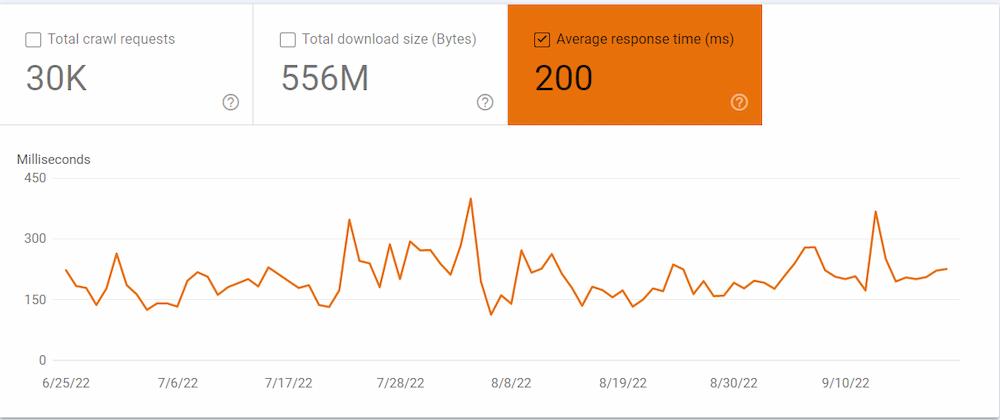
In the meantime, check your crawl stats report on Google Search Console. Open the report, select your domain, and click the Average response time (ms). This will show you how long it takes for your server to load. You will likely notice a correlation between your total crawl requests and the average response time.
To find out more on how web performance and crawl budget are connected, read our article on web performance and crawl budget.
7. Fix resource-heavy websites
Resource-heavy websites are another reason for crawling issues.
If a page calls for multiple additional resources to be crawled and rendered (such as multiple CSS stylesheets or JavaScript files), it has a particularly negative impact on your crawl budget.
That’s because every resource Googlebot uses to render your page counts toward your crawl budget.
You should optimize your site’s JavaScript and CSS (top offenders) files. Optimizing these files will reduce the negative impact of your code.
Here’s what you can do now: Still unsure of dropping us a line? Read how technical SEO services can help you improve your website.NEXT STEPS
When to optimize “Discovered ‐ currently not indexed” pages
In some cases, URLs that have the “Discovered ‐ currently not indexed” status do not need updating. You do not need to do anything if:
- The number of affected URLs is low, and they get crawled and indexed with time.
- The report contains URLs that shouldn’t be crawled or indexed, e.g., those with canonical or ‘noindex’ tags, or those blocked by robots.txt.
It’s crucial that you check whether your URLs should be crawled in the first place. It’s normal for some pages to be reported as “Discovered ‐ currently not indexed.” But if:
- The number of URLs increase
- Essential URLs have the “Discovered ‐ currently not indexed” status
Then you need to check and optimize the affected URLs as this could result in significant ranking and traffic drops.
The URL inspection tool
Once you have decided to update your content and URLs, you can request that specific pages be indexed via Google’s URL inspection tool.
Open the URL inspection tool on Google Search Console. Paste the URL you want to index into the search bar at the top of the page.

Then click the “request indexing” button.
Using the URL inspection tool to request indexing doesn’t guarantee that a given page gets crawled and indexed. It only sends a signal to Google that you want this page to be crawled and indexed with high priority.
Wrapping up
URLs in “Discovered ‐ currently not indexed” are caused by site quality, internal linking, and crawl budget issues.
Here are the key points that can help your pages to be crawled and indexed:
- Check the quality and originality of your affected pages
- Apply internal links, especially to vital pages
- Use robots.txt to prevent Googlebot from crawling low-quality pages
- Have an indexing strategy in place which focuses on the most important pages
- Optimize your crawl budget, so Google has more resources to crawl these pages.
Have you also got page’s with the “Crawled – currently not indexed status?” Find out how to get those URLs indexed in our “Crawled – currently not indexed” guide.

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!