
There are countless SEO crawler tools available today, but how do you choose the one that best responds to your website’s needs?
There is no single best SEO crawler. You may find yourself torn between different options, wondering which crawler to invest in that would tick all the boxes regarding the features, pricing, technical capabilities, etc.
This guide is a result of my tests and analyses of SEO crawlers to help you choose the one that perfectly suits your business’ expectations and goals.
These are the SEO crawlers reviewed in this article:
- DeepCrawl
- Ryte
- Botify
- OnCrawl
- Screaming Frog
- Sitebulb
- Moz
- Ahrefs
- SEMrush
- WebSite Auditor
- Jet Octopus
- Audisto
- FandangoSEO
- Netpeak Spider
- ContentKing
Key features of SEO crawlers
Before I delve into the specifics of each crawler, let me explain the features and characteristics of these tools that I considered when testing them and preparing this article. Let me clarify why each feature is important for you and should be a part of a crawling tool, and in what situations they may be particularly useful.
Refer back to this list if anything is unclear down the road.
Basic SEO reports |
|
|---|---|
|
List of indexable/non-indexable pages |
This helps you make sure that your indexing strategy is properly implemented. |
|
Missing title tags |
A crawler should show you a list of pages that have missing title tags. |
|
Filtering URLs by HTTP status code |
How many URLs are “Not found (404)”? How many URLs are redirected (301)? |
|
List of Hx tags |
“Google looks at the Hx headers to understand the structure of the text on a page better.” – John Mueller (Google) |
|
View internal nofollow links |
Seeing an internal nofollow list allows you to make sure there aren’t any mistakes in your internal linking. |
|
External links list (outbound external) |
A crawler should allow you to analyze both the internal and external outbound links. |
|
Link rel=”next” (to indicate a pagination series) |
When you perform an SEO audit, you should analyze if the pagination series are implemented properly. |
|
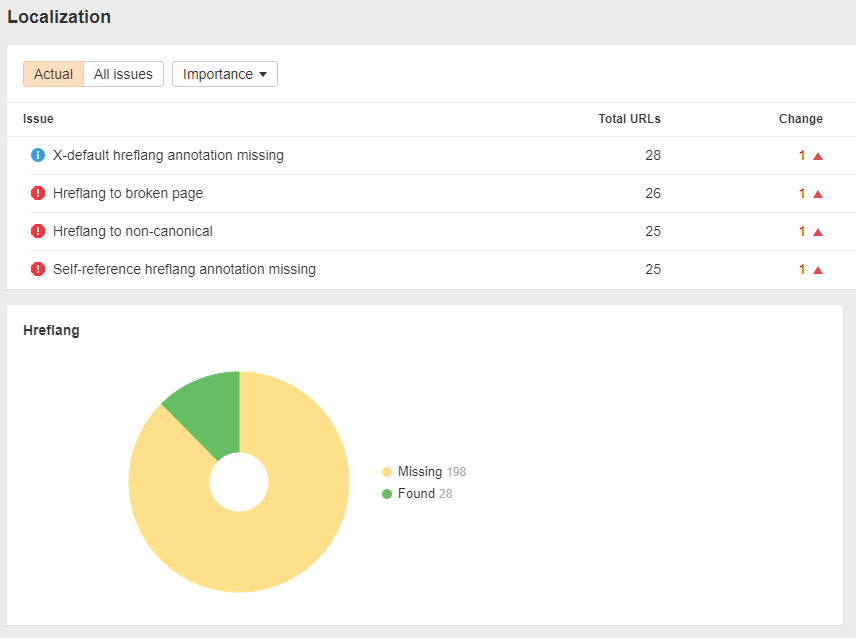
Hreflang tags |
Hreflang tags are the foundation of international SEO, so a crawler should recognize them. |
|
Canonical tags |
Every SEO crawler should inform you about the canonical tags to let you spot potential indexing issues. |
|
Crawl depth – number of clicks from a homepage |
Additional information about the crawl depth can give you an overview of the structure of your website. If an important page isn’t accessible within a few clicks from a homepage, it may indicate poor website architecture. |
Content analysis |
|
|
List of empty/thin pages |
A large number of thin pages can negatively affect your SEO efforts. A crawler should report them. |
|
Duplicate content reports |
A crawler should give you at least basic information on duplicates across your website. |
Convenience |
|
|
A detailed report for a given URL |
You may want to see internal links pointing to a particular URL or to see its headers, canonical tags, etc. |
|
Advanced URL filtering |
It’s common that I want to see the URLs that end with “.html” or contain a product ID. A crawler must allow for filtering. |
|
Page categorizing |
Some crawlers offer the possibility to categorize crawled pages (blog, product pages, etc.) and generate reports dedicated to specific categories of pages. |
|
Adding additional columns to a report |
When I view a single report, I may want to add additional columns to get the most out of the data. |
|
Filtering URLs by type (HTML, CSS, JS, PDF, etc.) |
Crawlers visit resources of various types ( HTML, PDF, JPG). A crawler should support filtering by type. |
|
Overview |
Having all the detected issues on a single dashboard will not do the job for you, but it can make SEO audits more streamlined. |
|
Comparing crawls |
It’s important to compare the crawls that were done before and after any changes implemented on the website. |
Crawl settings |
|
|
List mode – crawl just the listed URLs |
This feature can help you if you want to perform a quick crawl of a small set of URLs. |
|
Changing the user agent |
Some websites may block crawlers, and it’s necessary to change the user agent to be able to crawl them. |
|
Crawl speed adjusting |
Much like Googlebot, you should be able to adjust your crawl speed according to the server’s response. |
|
Setting crawl limits |
When crawling a very large website, you may want to set a limit to the number of crawled URLs or the crawl depth. |
|
Analyzing a domain protected by an htaccess login |
This is a helpful feature if you want to crawl the staging environment of a website. |
|
Directory/subdomain exclusion |
It’s helpful if you can disallow the crawler from crawling a particular directory or a subdomain. |
Maintenance |
|
|
Crawl scheduling |
It’s handy to be able to schedule a crawl and set monthly/weekly crawls. |
|
Indicating the crawling progress |
If you deal with large websites, you should be able to see the current status of the crawl. |
|
Robots.txt monitoring |
Accidental changes in robots.txt can lead to an SEO disaster. It’s beneficial if a crawler detects changes in robots.txt and informs you. |
|
Crawl data retention |
It’s helpful if a crawler can store crawl data for a long period of time. |
|
Notifications |
A crawler should inform you when the crawl is done (desktop notification/email). |
Advanced SEO reports |
|
|
List of pages with less than x links incoming |
If there are no internal links pointing to a page, Google may think it’s irrelevant. |
|
Comparison of URLs found in sitemaps and in a crawl. |
Sitemaps should contain all your valuable URLs. If some pages are not included in the sitemap, Google may struggle to find them. If a URL is included in the sitemap but can’t be found by the crawler, Google may think that page isn’t relevant. |
|
Internal PageRank value |
Although PageRank calculations can’t reflect Google’s link graph, it’s an important feature. PageRank is still one of Google’s ranking factors. |
|
Mobile audit |
In mobile-first indexing, it’s necessary to perform a content parity audit and compare the mobile and desktop versions of your website. |
Additional SEO reports |
|
|
List of malformed URLs |
Sometimes, websites use improper links, such as http://http://www.example.com. Users and search engine bots can’t visit those links. |
|
List of URLs with parameters |
Commonly, URLs with parameters create duplicate content. It’s beneficial to analyze what kind of parameters a website is using. |
|
Redirect chains report |
Nobody likes redirect chains. A crawler should find redirect chains for you so that you can fix them and avoid the “Redirect error” issues. |
|
Website speed reports |
Performance is increasingly more important both for users and search engines. Crawlers should analyze your website performance. |
|
List of URLs blocked by robots.txt |
You should review the list of URLs blocked by robots.txt to ensure it adheres to your indexing strategy. |
|
Schema.org detection |
Correctly implemented structured data markup is crucial to your search visibility. |
Export, sharing |
|
|
Exporting to Excel/CSV? |
Being able to export the crawl data to various formats will save you plenty of time. |
|
Creating custom reports/dashboards |
When working with a client or a colleague, you may want to create a dashboard showcasing a particular set of issues. |
|
Exporting individual reports |
Let’s say that you want to share a report which shows 404 URLs with your developers. Does the crawler support it? |
|
Granting access to a crawl to another person |
It’s pretty common that two or more people work on the same SEO audit. Thanks to report sharing, you can work simultaneously. |
Miscellaneous |
|
|
Why and how to address the issues |
If you are new to SEO, you will appreciate the explanation of the issues that many crawlers provide. |
|
Custom extraction |
A crawler should let you perform a custom extraction to enrich your crawl. For instance, while auditing an e-commerce website, you should be able to scrape information about product availability and price. |
|
Can a crawler detect a unique part that is not a part of the template? |
Some crawlers let you only analyze the unique parts of a page (omitting the navigation, footer, header, etc.) |
|
Integration with other tools |
It’s useful if you can easily combine your crawl data with data from other sources, like Google Analytics, Google Search Console, backlinks tools (Ahrefs, Majestic SEO), or server logs. |
|
JavaScript rendering |
If your website depends heavily on JavaScript, you need a crawler that is able to render it. |
|
Why you should use the particular crawler |
I reached out to the crawlers’ representatives to hear why they think their tool is the best choice. |
Types of SEO Crawlers
There are two types of crawlers: desktop crawlers and cloud-based crawlers.
Desktop crawlers
These are the crawlers that you install on your computer.
Examples include Screaming Frog, Sitebulb, Link Assistant’s WebSite Auditor, and NetPeak Spider. Usually, desktop crawlers are much cheaper than cloud crawlers, but they have some drawbacks, such as:
- Crawls consume your memory and CPU. However, the situation is much better than it used to be in that crawlers are improving in the areas of memory & CPU management.
- Collaboration is limited. You can’t just share a report with a client/colleague. You can, however, work around this by sending them a file with a crawl project.
- Unfortunately, desktop crawlers generally struggle with crawl comparison (Sitebulb is an exception) and scheduling.
- In general, desktop crawlers offer fewer features than cloud crawlers.
Many professional SEOs admit that even if they work with powerful and expensive cloud-based tools, they still regularly use desktop crawlers as well. Same here. There are some areas where desktop crawlers are more useful and convenient:
- When I need to see the screenshot of a rendered view, I use SF (currently, it’s the only tool that supports this feature).
- If I want to start a quick crawl with real-time preview, I use Screaming Frog.
- When I am running out of credits in the cloud tool, I simply use a desktop crawler like Screaming Frog, WebSite Auditor, or SiteBulb.
- For now, Screaming Frog and Sitebulb are better in spotting redirect chains than most of the premium tools.
Cloud crawlers
At Onely, we run desktop crawls using a server with 8 cores and 32 GB RAM. Even with a configuration like that, it’s common for us to have to stop crawls because we’re running out of memory. That’s one of the reasons why we use cloud crawlers too.
Cloud crawlers use cloud computing to offer more scalability and flexibility.
- Most cloud-based crawlers allow for online collaboration. Usually, you can grant access to the crawl results to a colleague/client. Some of the cloud crawlers even allow sharing individual reports.
- It’s common to get dedicated, live support.
- For the most part, you can easily notice changes between various crawls.
- Generally, cloud-based crawlers are more powerful than desktop ones.
- Many of them have basic data visualization features.
- Of course, this comes at a cost. Cloud crawlers are much more expensive than desktop ones!
Desktop Crawlers
Screaming Frog
Pricing
£149.00 per year per license. The cost is reduced if you purchase multiple licenses. For instance, if you purchase 20+ licenses, the cost per license goes down to £119.00.
Screaming Frog is the most popular desktop crawler. It checks for virtually every necessary aspect of SEO: canonicals, status codes, titles, headers, etc. It’s a very customizable tool – there are tons of options you can configure.
Screaming Frog is also up to date with the most recent trends. It allows for JavaScript crawling, and you can integrate the crawl data with Google Analytics and Google Search Console.
There’s one aspect where Screaming Frog could use some improvement: data visualization. In this category, Sitebulb is simply superior.
Notable features of the Screaming Frog SEO Crawler
- Structured data validation.
- JavaScript crawling.
- Website structure visualizations.
- Full command-line interface to manage crawls.
- Reporting canonical chains.
- Near duplicate content detection.
- Information on link position – content/footer/sidebar.
- AMP crawling & validation.
- Scheduling. You can schedule crawls (daily/weekly/monthly) and set up auto exporting. It’s a big step forward, but I am still missing the ability to easily compare the data between crawls.
- Web performance reports (Lighthouse + Chrome User Experience Report).
- Auto-saving & the ability to resume previously lost crawls.
- When you manage huge crawls, you can exclude storing particular elements (e.g., meta keyword) to save up the disk space.
Tip: when you do a crawl, don’t forget to enable post-crawl analysis, which will allow you to get the most out of the data.
Screaming Frog now offers visualization of links. You can choose one of two types of visualizations – crawl tree or directory tree. Both are valuable for SEO audits. The former can show you groups of pages and how they are connected. The latter can help you understand the structure of a website.
Checklist for Screaming Frog.
Sitebulb
Pricing
£25 + VAT per month per user. Every additional license costs £5 + VAT – a mere 20% of the price. Sitebulb also offers a Lite plan for £10 + VAT per month – this plan is ideal for freelancers or website owners.
By visiting https://sitebulb.com/onely you can get an exclusive offer, a 60-day free trial.
Sitebulb is a relatively new tool on the market, but it has been warmly received by the SEO community. Personally, I really like Sitebulb’s visualizations:
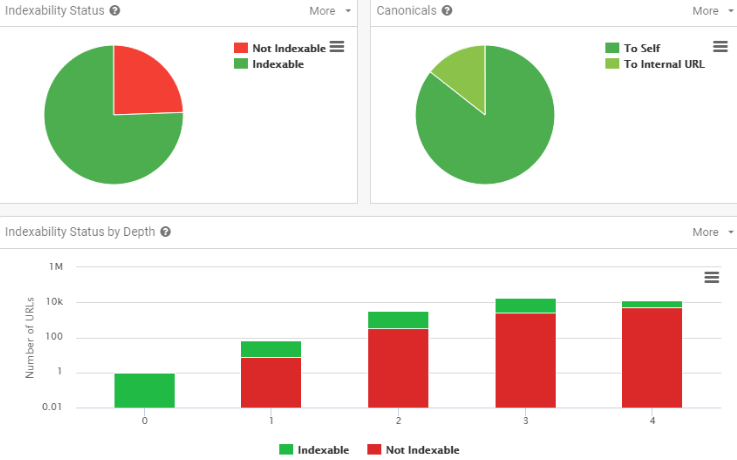
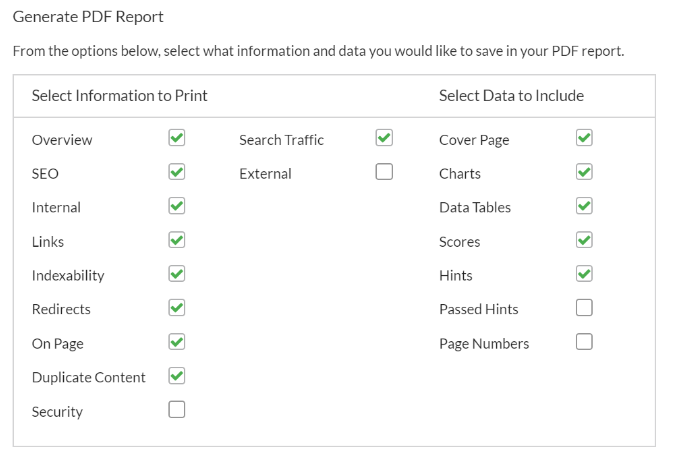
Because Sitebulb is a desktop-based crawler software, you can’t just share a report with your colleagues while doing an SEO audit. You can partially work around this by exporting a report to PDF. Once you click on the “Export” button, you will see a 40-page document full of charts presenting the most important insights. You can also copy your crawls and work on them with your team across several instances.
The PDF reports are highly customizable. You can select the aspects of the crawl data that you want to highlight in a report that you export.
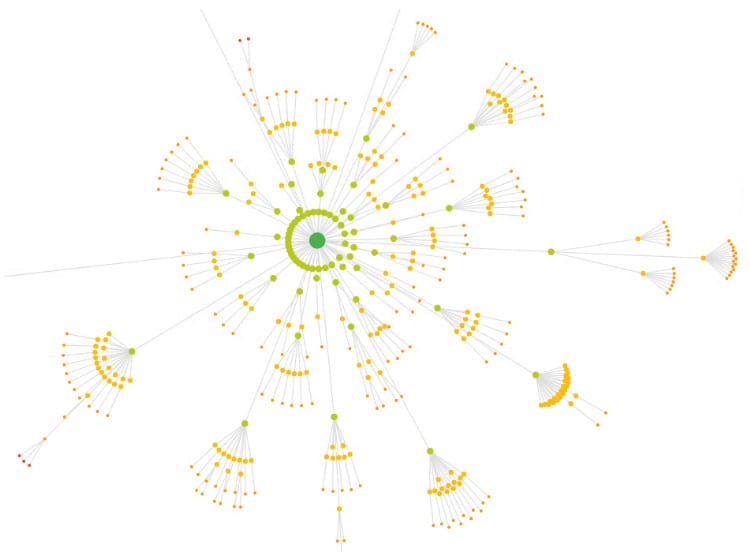
Crawl maps
Sitebulb’s crawl maps are a uniquely useful feature. These maps can help you understand your website’s structure, discover internal link flow, and spot groups of orphan pages.
Notable features of the Sitebulb SEO Crawler
- Performance statistics like First Meaningful Paint (helpful for website speed optimization).
- List mode (like in Screaming Frog).
- Schema + Rich Results validation.
- Code coverage report (unused CSS, JS – helpful for website speed optimization).
- Multi-level filtering, like in Ryte, Botify, OnCrawl, and DeepCrawl.
- AMP validation.
- Integration with Google Sheets, Google Analytics, and Google Search Console.
- Link Explorer.
- Crawling JavaScript websites (Sitebulb uses Chrome Evergreen).
- Sitebulb is the only desktop crawler that has the crawl comparison feature.
- Advanced content extractor.
Sitebulb’s main drawbacks
- Sitebulb doesn’t inform you about H2 tags.
- As a Big Data fan, I’d like to be able to export all internal links to a CSV/Excel file. Screaming Frog offers that feature. However, Sitebulb’s summaries and visualizations are probably more than enough for most SEOs.
- If Sitebulb encounters an error while retrieving a page, it will not be recrawled.
- I can do only one crawl at a time; other crawls are added to the queue.
I believe in the case of Sitebulb the pros outweigh the cons. By the way, you can suggest your own ideas directly to the Sitebulb team by submitting them through https://features.sitebulb.com/. It seems many interesting features like crawl scheduling and data scraping are going to be implemented in the near future. I’m keeping my fingers crossed for the project.
Checklist for Sitebulb.
WebSite Auditor
Pricing
WebSite Auditor is available for free and in two paid editions.
The 500 URLs limit of the free version makes it a good choice for freelancers and website owners.
The paid editions (Pro for 124$/year, and Enterprise for 299$/year) not only offer convenient maintenance and report sharing features, but also allow you to crawl over 500 URLs and store multiple projects in the cloud.
If you use our referral links at WebSite Auditor Enterprise or WebSite Auditor Professional, you will get 10% off at checkout.
WebSite Auditor gives you information about status codes, click depth, incoming/outgoing links, redirects, 404 pages, word count, canonicals, and pages restricted from indexing. You can then easily integrate the crawl data with Google Search Console and Google Analytics. As with Screaming Frog, for every URL you can see a list of inbound links (including their anchors and source). Also, you can easily export these data in bulk.
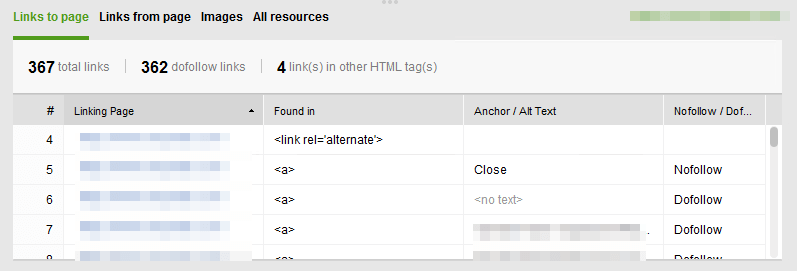
Notable features of the WebSite Auditor SEO Crawler
- Website structure visualization. WebSite Auditor lets you visualize the internal structure of your website: Click depth, Internal Page Rank, and Pageviews (available through integration with Google Analytics). To my knowledge, Sitebulb, FandangoSEO, and WebSite Auditor are the only crawlers on the market that offer this feature.
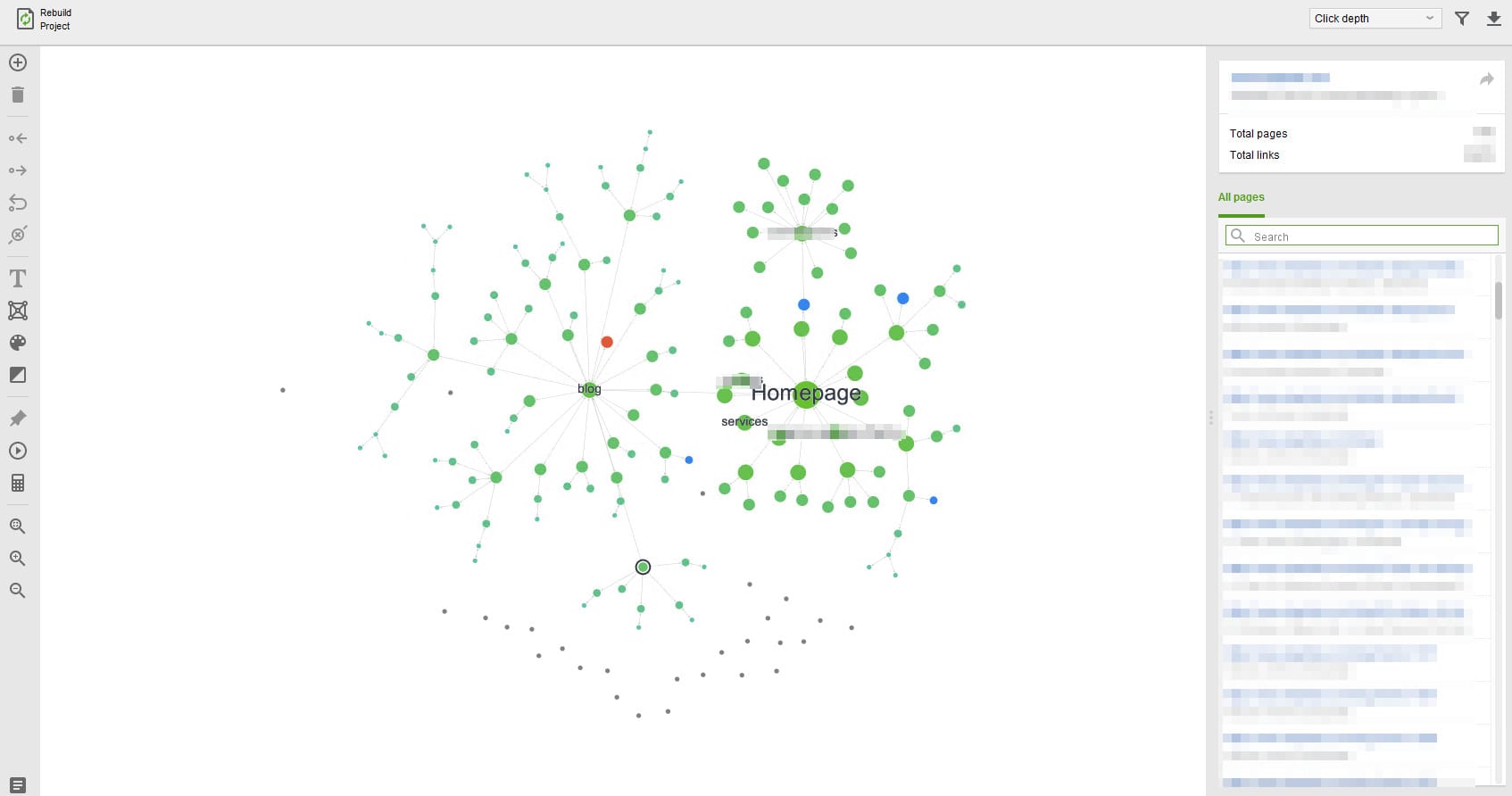
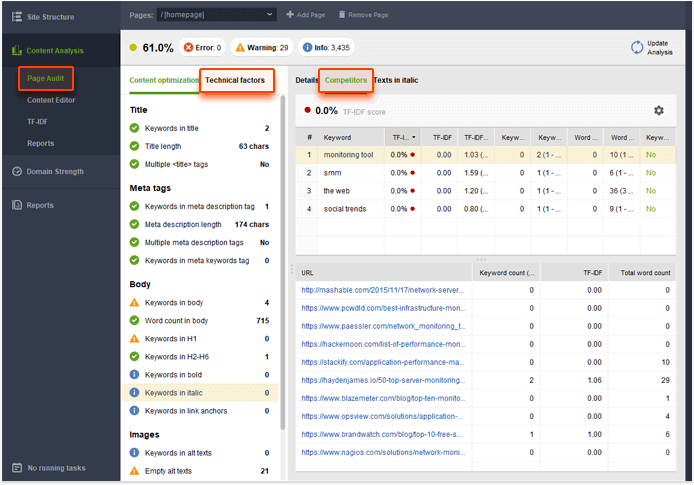
- Content analysis. WebSite Auditor provides a module dedicated to basic content analysis. It checks if the targeted keywords are used in the title, body, and headers. In addition, this module calculates the TF-IDF score for a page.
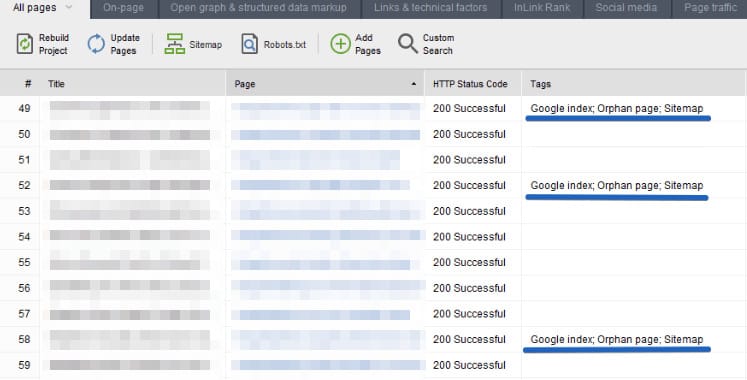
- WebSite Auditor’s unique function is the ability to look into Google index to find orphan pages.
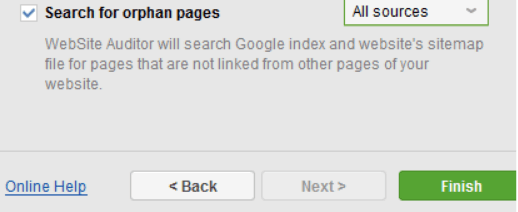
To do this, you have to tick the “Search for orphan pages’ option while setting up a crawl.
WebSite Auditor’s main drawbacks
- You can’t limit the number of URLs to be crawled, however, you can specify a maximum crawl depth.
- You can’t compare the data between different crawls.
- Although WebSite Auditor supports advanced filtering for reports, it doesn’t support regular expressions.
Checklist for WebSite Auditor.
Netpeak Spider
Pricing
Netpeak Spider is available in three pricing options – a Starter plan for $7/month, an Advanced plan for $12/month, and a Pro Bundle plan for $22/month. The Starter plan doesn’t offer multi-domain crawling or custom website scraping features and doesn’t provide the extensive customer support that the Advanced and Pro Bundle plans include.
Netpeak Spider was not analyzed in the initial release of the Ultimate Guide to SEO Crawlers. However, the list of improvements introduced in the recently released versions is quite impressive, so I just had to test it.
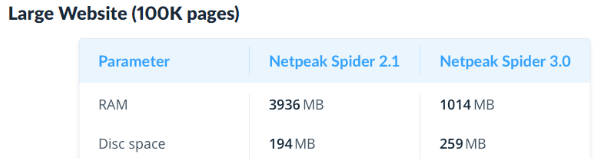
Speed improvements
First of all, according to Netpeak’s representatives, Netpeak Spider 3.0 consumes ~4 times less memory when compared to the 2.1 version. I don’t have the statistics on the most recent version, though.
Notable Netpeak Spider features
- Custom segmentation.
- JavaScript rendering.
- You can pause a crawl and resume it later or run it on another computer. For instance, if you see a crawl consumes too much RAM, you can pause it and move the files to a machine with a bigger capacity.
- Integration with Google Analytics and Google Search Console.
- You can rescan a list of URLs to check if the issues were fixed correctly.
- A dashboard that summarizes the most important insights.
- NetPeak shows the list of the most popular URL segments.
- Integration with Google Drive for better report sharing.
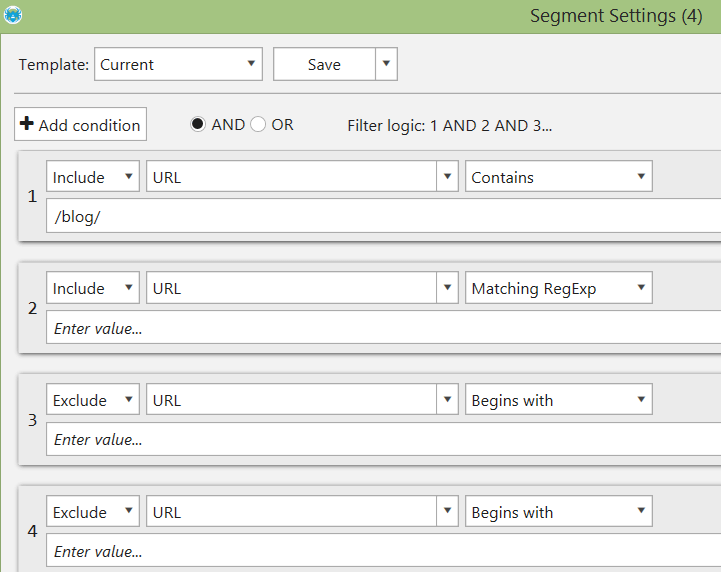
Custom Segmentation
My favorite feature of Netpeak Spider is data segmentation. To my knowledge, Netpeak Spider is the only desktop crawler that has implemented it.
With data segmentation, you can quickly define segments (clusters of pages) and see reports related to these segments only.
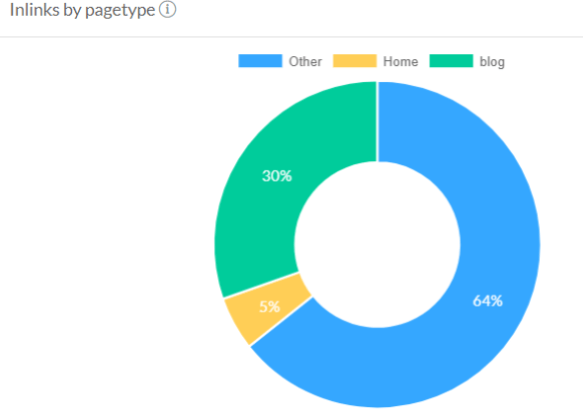
Custom segmentation is definitely a great feature, however, I miss the ability to see a segment overview report like those offered by cloud crawlers like Botify, FandangoSEO, and OnCrawl. In the screenshot from FandangoSEO below, you can see the page type breakdown when viewing the dashboard, which provides a great overview of segments.
Netpeak Spider’s main drawbacks
- Although Netpeak introduced a visual dashboard (which is fine), it still lacks the data visualization features of some other tools.
- NetPeak Spider works only on Windows. If you are a Mac or Linux user, you can’t use the tool.
Cloud Crawlers
Let’s move on to the cloud crawlers.
Disclaimer: at Onely, we primarily use DeepCrawl and Ryte. We did our best to remain unbiased. The crawlers are presented alphabetically.
Botify
Pricing
Botify doesn’t disclose its pricing on the website: it mentions three plans and states that pricing is flexible and adjusted according to your needs.
Botify is an enterprise-level crawler. Its client list is impressive: Airbnb, Zalando, Gumtree, Dailymotion.
Botify offers many interesting features. I think it’s the most complex, but also the most expensive of all crawlers listed.
Notable features of the Botify SEO Crawler
- Botify has the ability to filter reports and dashboards by segments.
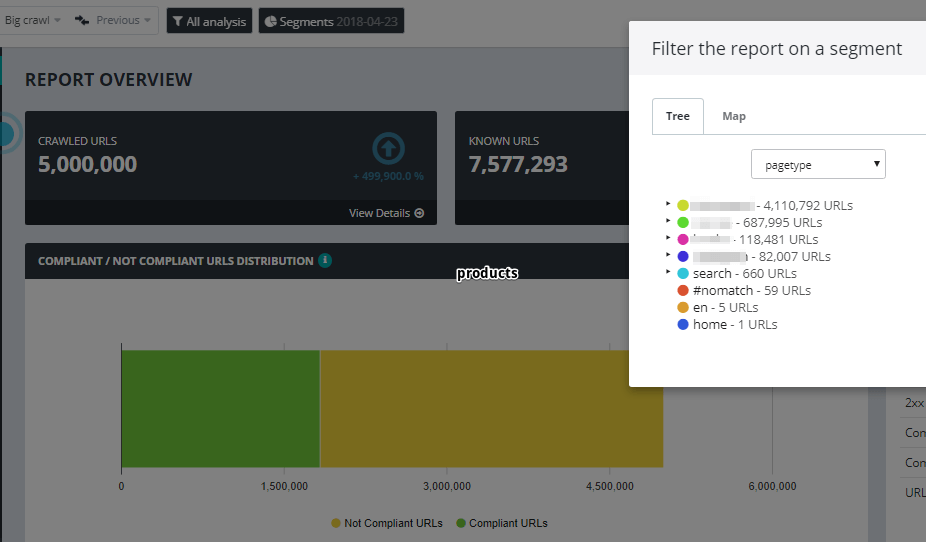
Let’s imagine you have three sections on your website: /blog, /products, and /news. Using Botify, you can easily filter reports to see the data related only to product pages.
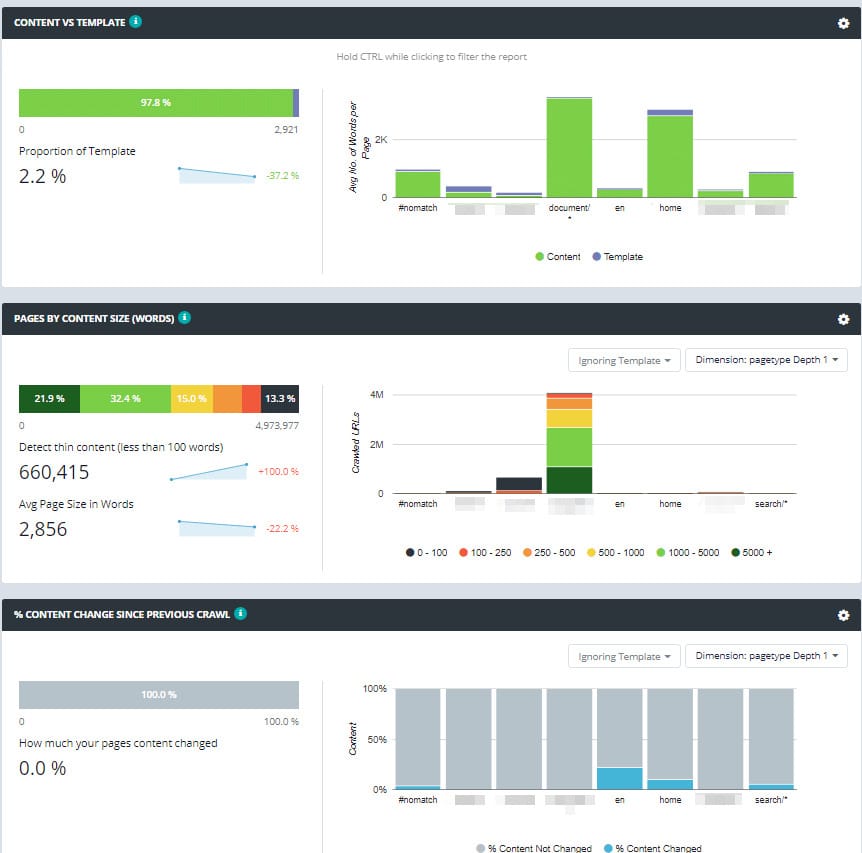
- For every filter, you can see a dedicated chart (there are 35 charts in the library across several categories). This is pretty impressive.
- You can install the Botify addon for Chrome and see insights directly from the browser. Just navigate to a particular subpage of a crawled website and you will see the basic crawl stats, a sample of internal links, URLs with duplicate metadata (description, H1 tags), and URLs with duplicate content.
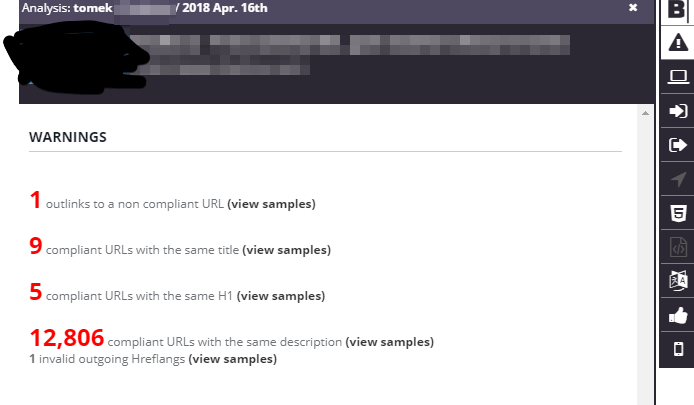
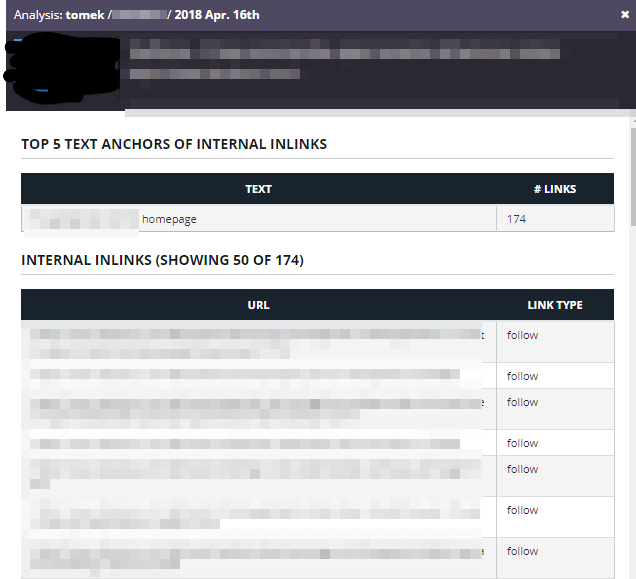
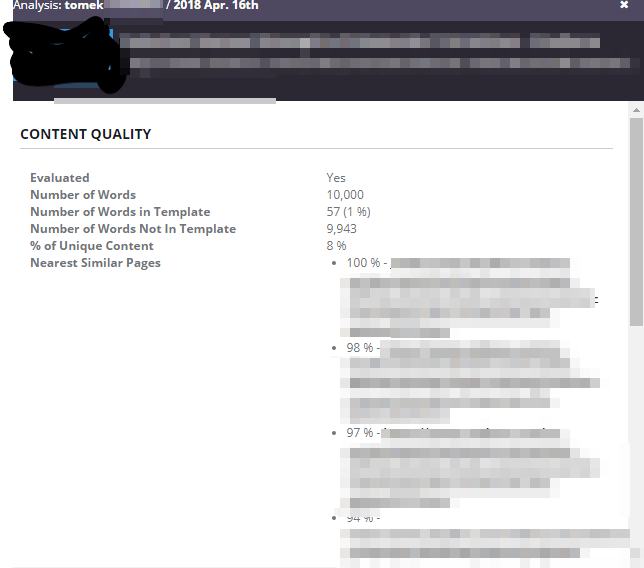
- Botify stores the HTML code for every crawled page. It allows for monitoring content changes across crawls.
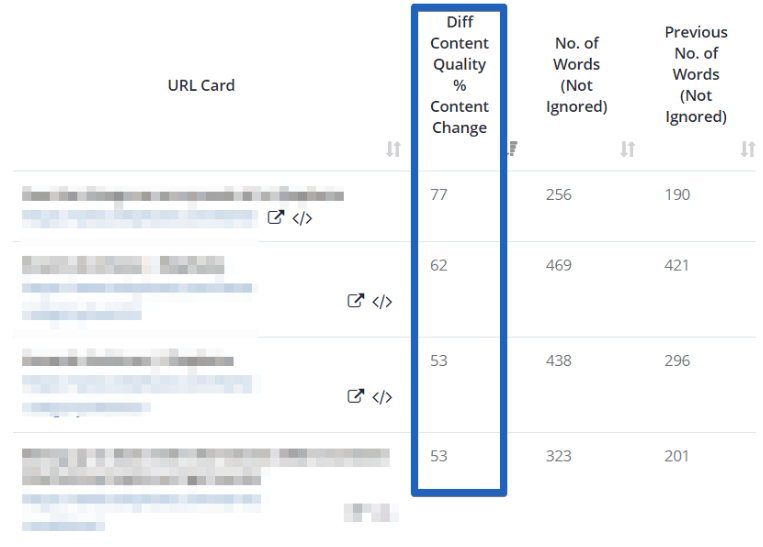
- Botify allows for server log analysis and JavaScript crawling; however, like in the case of OnCrawl, it’s not included in the basic subscription plan.
- Botify offers helpful SEO resources and webinars showing how to use their features.
Checklist for Botify.
Deepcrawl
Pricing
DeepCrawl doesn’t have a fixed price plan – get in touch with their sales team to start using the crawler.
DeepCrawl is a popular, cloud-based crawler. At Onely, we use it on a regular basis (along with Ryte and Screaming Frog).
Notable DeepCrawl features
- JavaScript rendering.
- Logfile integration.
- Integration with Majestic SEO.
- Integration with Zapier.
- Stealth mode (the user agent, the IP address is randomized within a crawl; helpful for crawling websites with restricted crawling policy).
- Integration with Google Search Console and Google Analytics.
- Crawl scheduling.
We really like DeepCrawl, but one of the biggest drawbacks of it is that you can’t add additional columns to a report. Let’s say I am viewing a report dedicated to status codes, and then I would like to see some additional data: canonical tags. I simply can’t do it in DeepCrawl. If I want to see the canonicals, I have to switch to the canonical report. For me, it’s an important feature that’s missing. However, I am pretty sure they will catch up shortly. I do believe that in the case of DeepCrawl, the pros outweigh the cons.
Checklist for DeepCrawl.
OnCrawl
Pricing
OnCrawl offers a free 14-day trial that lets you see if it’s the right crawler for your needs.
The paid plans include Explorer at €49/month, Enterprise at €199/month, and Ultimate at €399/month. The plans differ in the number of domains you can monitor, the number of URLs you can crawl per month, and the number of simultaneously running crawls. There’s also the Infinite&Beyond custom plan for large agencies and enterprise clients.
Using the “Onely-OnCrawlTR2020” promo code, you can get a discount when buying OnCrawl!
https://www.youtube.com/watch?v=kjcNjAe6woY
Notable OnCrawl features
- A unique near-duplicate detection feature – you can filter a list of URLs by similarity ratio.
- Being able to integrate crawl data with any other data in a CSV file. Note: Botify offers a similar feature for some of its clients. FandangoSEO recently added this feature as well.
- URL segmentation – let’s say you view a list of non-indexed URLs. You can easily use URL segmentation to see only the blog or product pages within that list.
- Excellent hreflang reporting.
- Crawl scheduling.
- Integration with Google Analytics and Google Search Console
- Creating custom dashboards. You can easily add or remove charts to a custom-built dashboard. OnCrawl provides a library of charts to choose from.
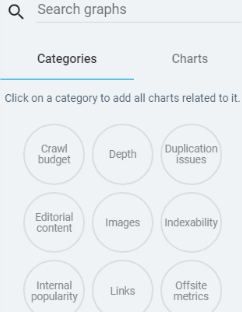
- Page groups.
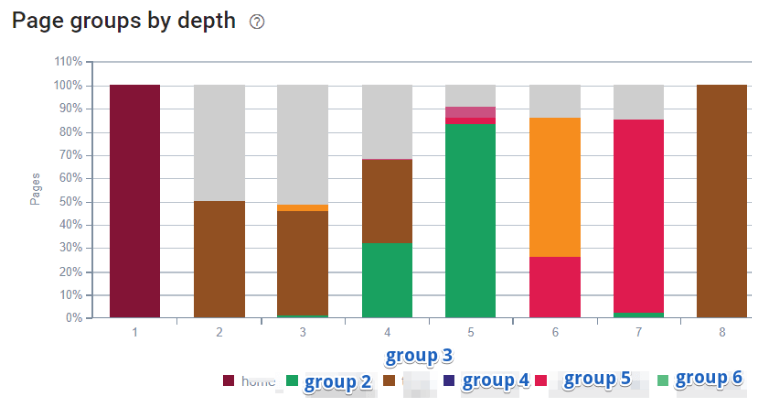
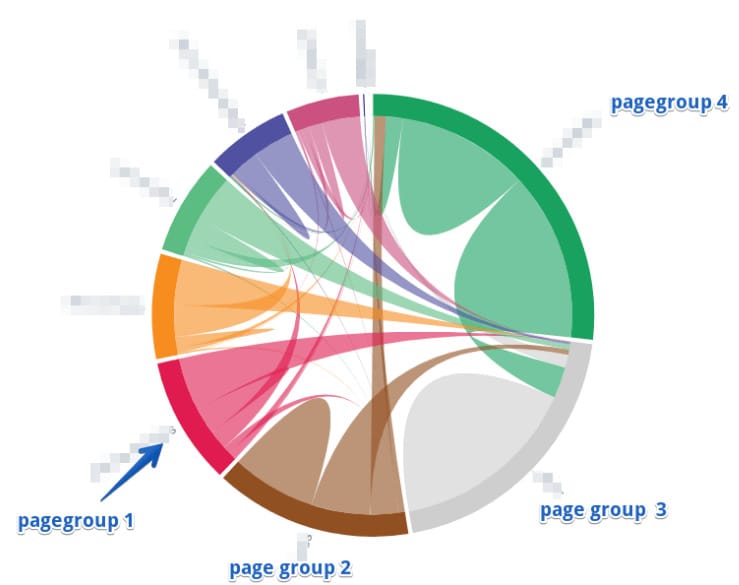
OnCrawl’s drawbacks
- OnCrawl lacks the ability to filter crawled URLs by regular expressions.
- It doesn’t come with a list of detected SEO issues by default. You can work around this by clicking on the Dashboard builder -> Onsite Issues.
Checklist for OnCrawl.
Ryte
Pricing
You can try a basic, limited version of Ryte for free. If you want to upgrade your account to access the full spectrum of Ryte’s features, you’ll have to contact the team at Ryte to get an offer that’s adjusted to your needs.
Ryte is a very popular web-based crawler. We use it regularly alongside Screaming Frog and Deepcrawl, and we’re Ryte’s Solution Partners.
Notable Ryte features
- Excellent general reporting. On a single dashboard, I can see a list of all the detected SEO issues.
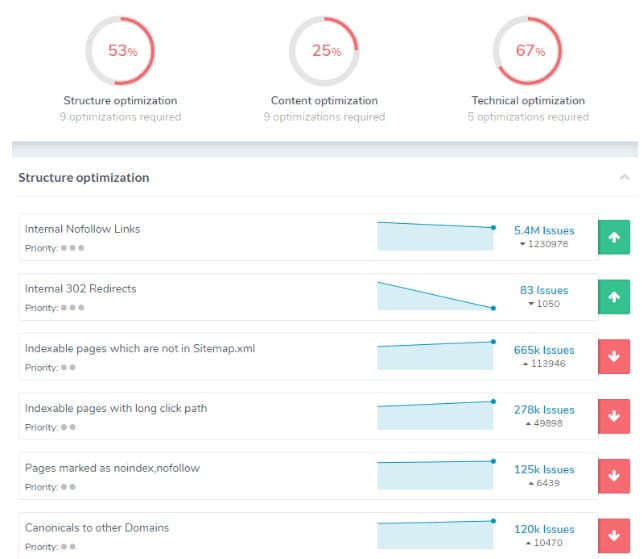
- Ryte integrates with Google Search Console and Google Analytics.
- Server uptime monitoring. Ryte checks if your server is up and running by pinging it regularly.
- Robots.txt monitoring. This amazing feature checks if there were any changes made to your robots.txt file – just in case a mistake was made.
- A vast knowledge base.
- Ryte now supports JavaScript crawling.
- Server log analysis.
- If you want to re-run an active crawl, you won’t be charged again.
Ryte’s drawbacks
- Ryte’s user interface may feel clunky at times.
Checklist for Ryte.
Audisto
Pricing
You can use just the Audisto Crawler (starting at 90€/month with a limit of 100k crawled URLs, the price goes up with the number of URLs crawled) or Audisto Monitoring, an extended service that includes additional features, such as regex, XPath, or conditional filtering (starting at €590/month, also growing in price with the number of URLs crawled).
Audisto is a crawler that’s popular mainly in German-speaking countries.
Notable features of the Audisto SEO Crawler
- You can split lists of issues by category, like Quality, Canonical, Hreflang, or Ranking.
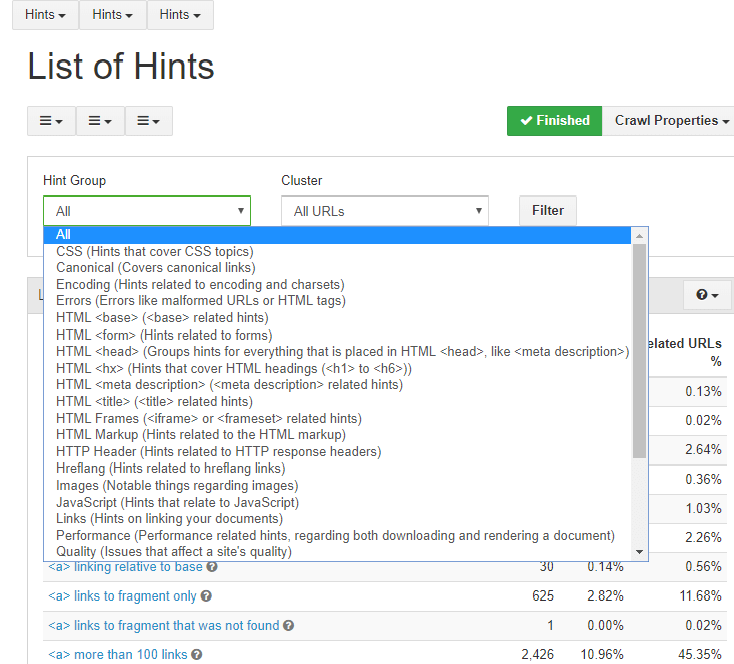
- You can create URL clusters based on filters and see reports and charts related only to those clusters. Many crawlers offering this a feature require you to have knowledge about Regular expressions. Audisto is a bit different in that; you can define patterns in the same way you define “traditional” filters. Additionally, you can even add comments when adding a cluster, which may be helpful for future reviews or when many people work on the same crawl.
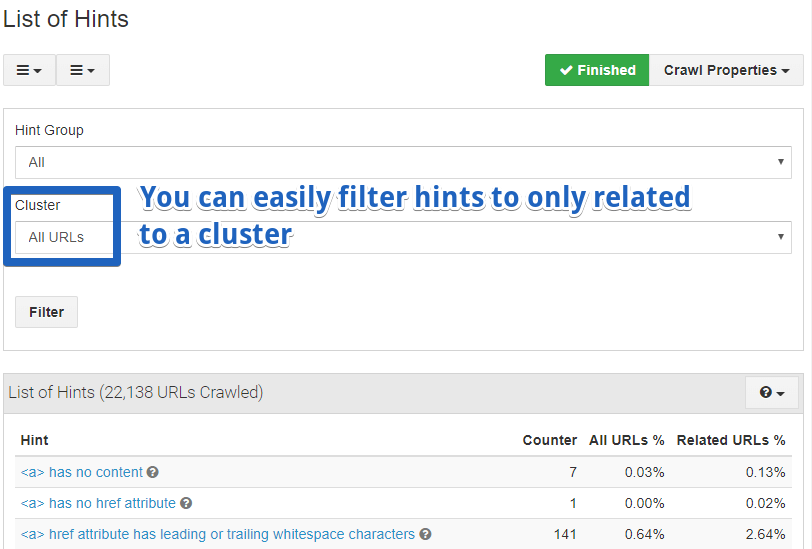
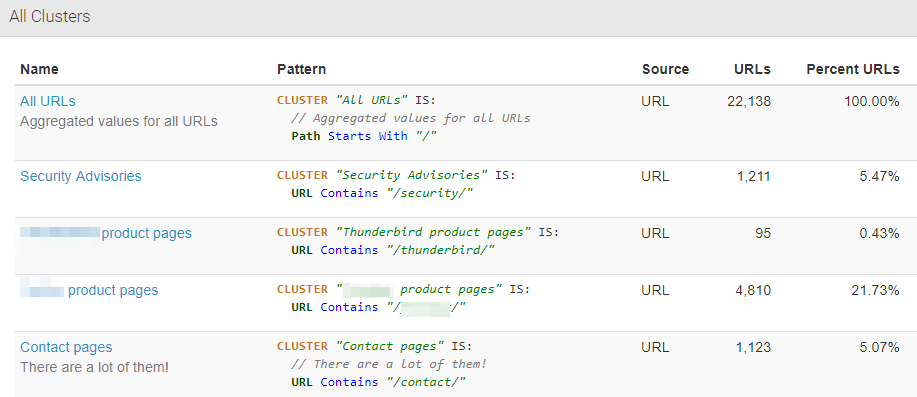
- Easy and straightforward crawl comparison.
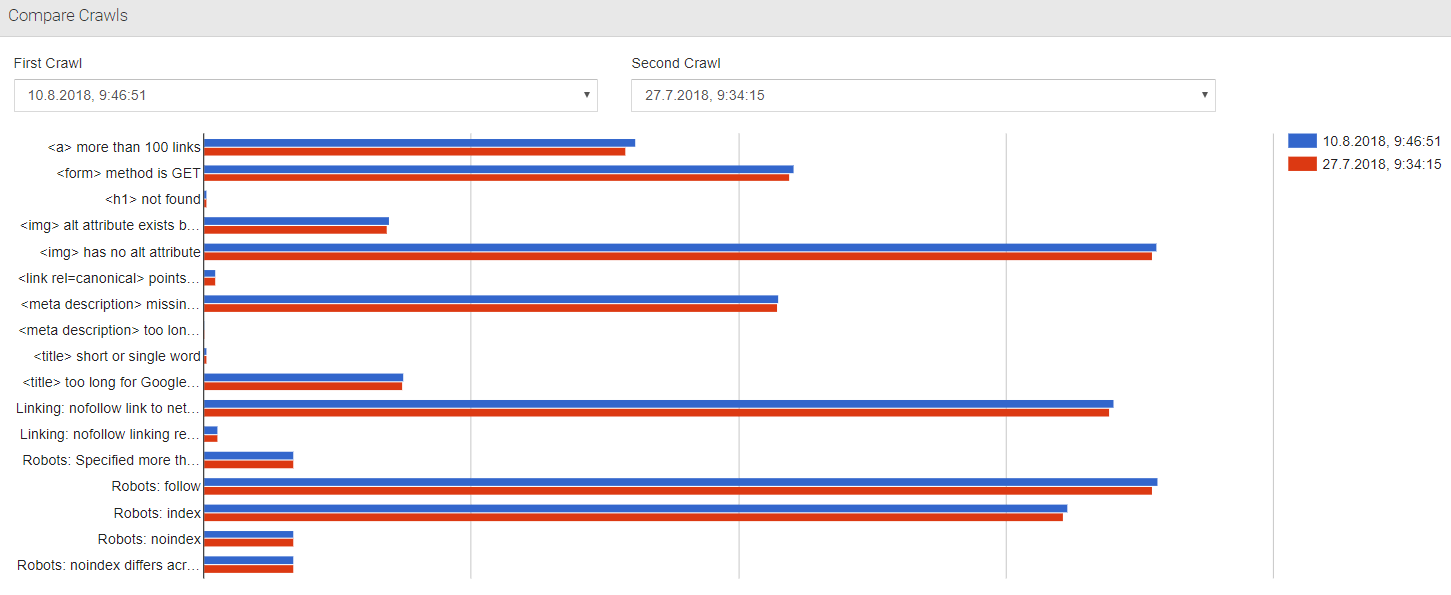
- Bot vs. User Experience. Audisto detects if users get a similar experience to Googlebot and even provides a chart to visualize the difference.
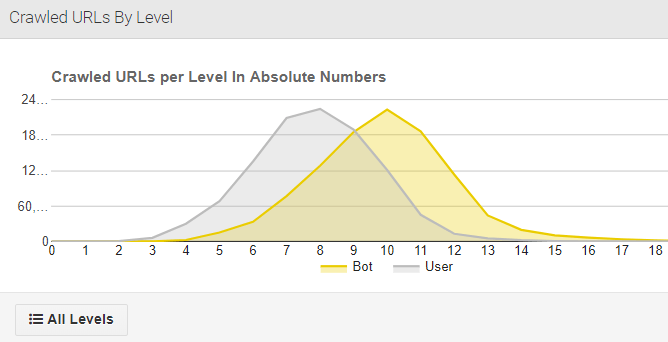
- Monitoring issues. For every issue listed in the Hint section (Current monitoring -> Onpage -> Hints) you can see the trendline:
- Extensive PageRank reporting.
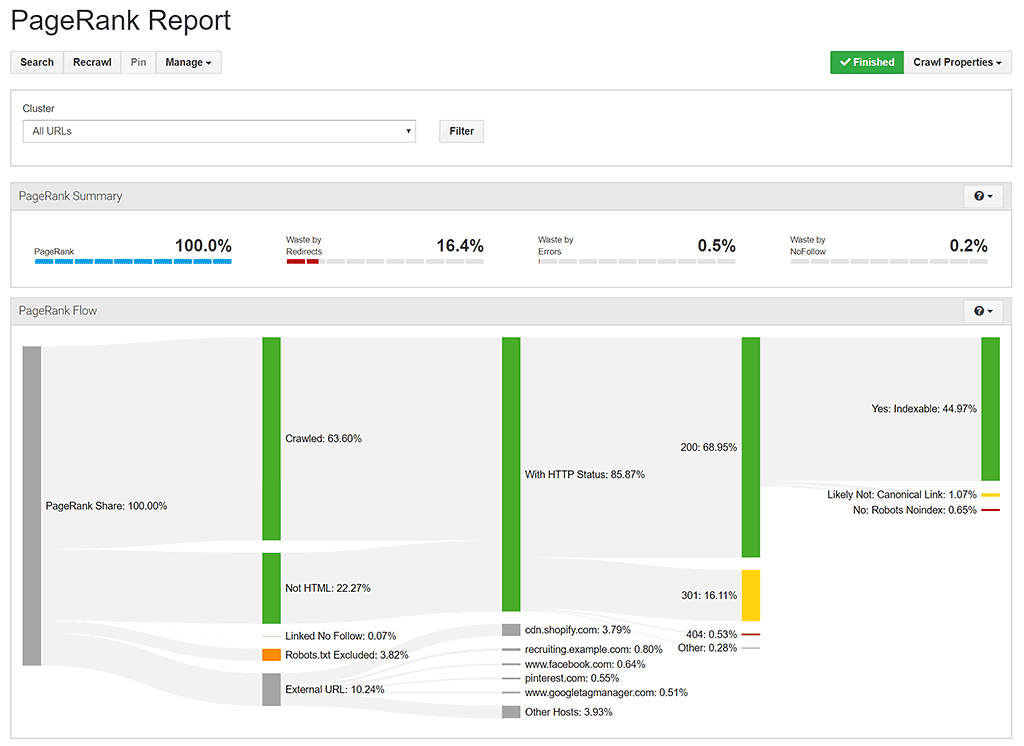
Disadvantages of Audisto
- You can’t add additional columns to a report (however, reports contain a lot of KPIs, and this should be improved in the next iteration of their software).
- The URL filtering is rather basic. However, you can partially work around this by using custom segmentation.
- Audisto doesn’t offer custom extraction.
- It doesn’t integrate with Google Analytics or Google Search Console and server logs.
JetOctopus
Pricing
JetOctopus is offering a wide range of pricing configurations, but to get the most out of the tool, you should go for the all-inclusive option, starting at $89/month with a limit of 100k crawled pages.
Using the “Onely” promo code, you can get a 10% discount for Jet Octopus.
JetOctopus is a relatively new tool in the market of cloud crawlers. It divides SEO issues into eight categories:
- Indexing
- Technical
- HTML
- Content
- Links
- Sitemap
- Internal Links
- External links
JetOctopus offers nice visualizations of the issues detected during the crawl.
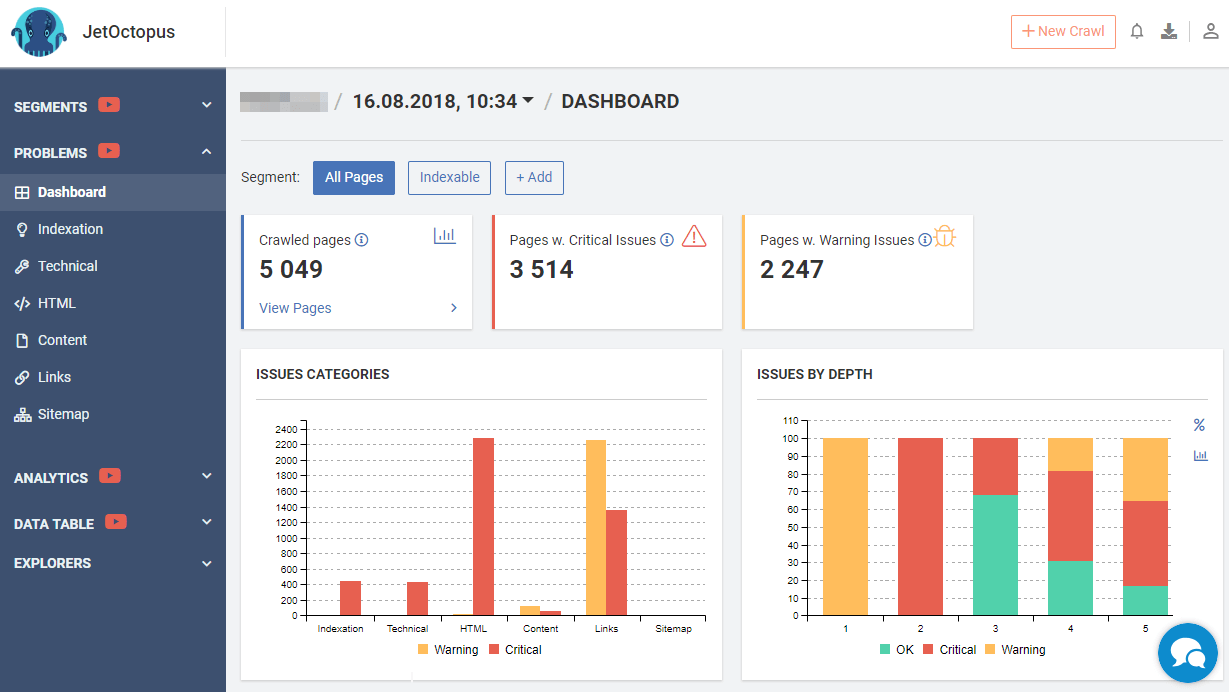
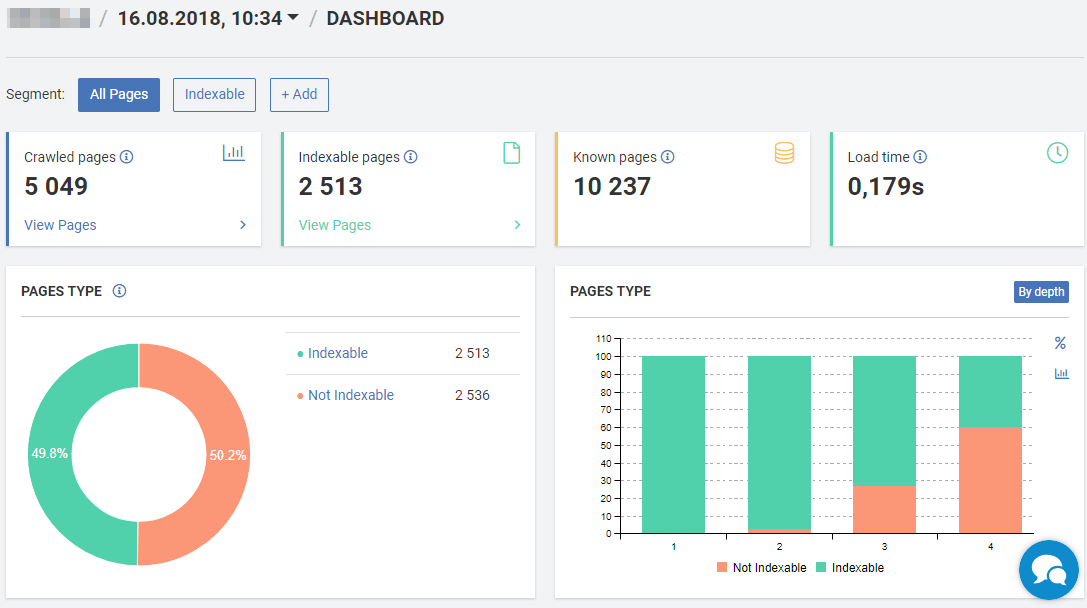
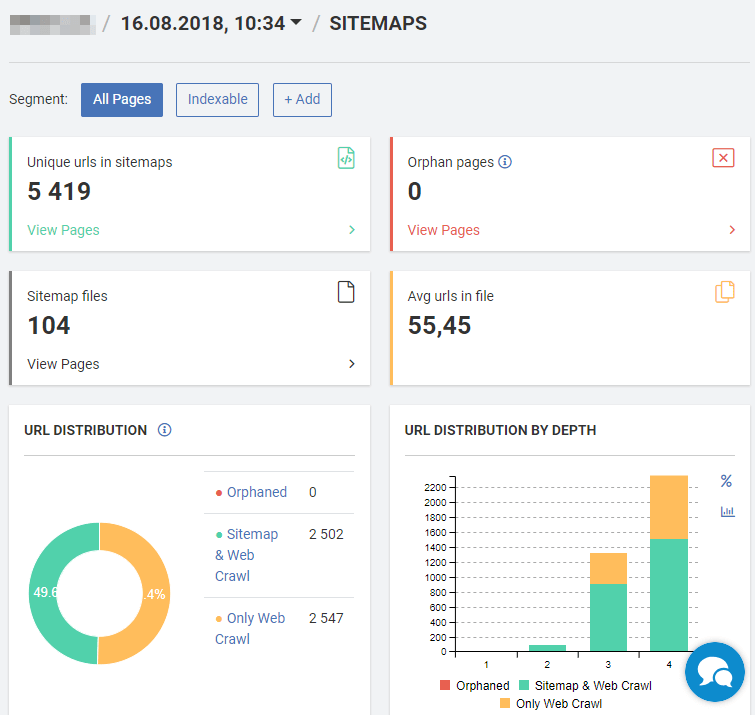
Notable features of the JetOctopus SEO Crawler
- Custom segmentation. JetOctopus allows you to define a new segment, which is very easy to use. You just set the proper filter and click on “Save segment,” and you don’t need to be familiar with Regular expressions.
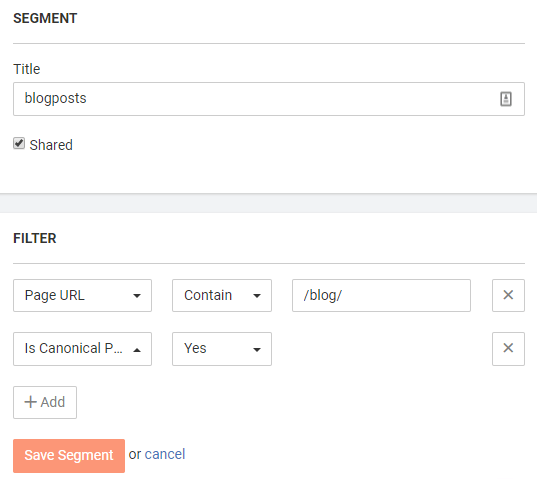
Then, you can filter reports to predefined segments.
- A great log file analysis feature
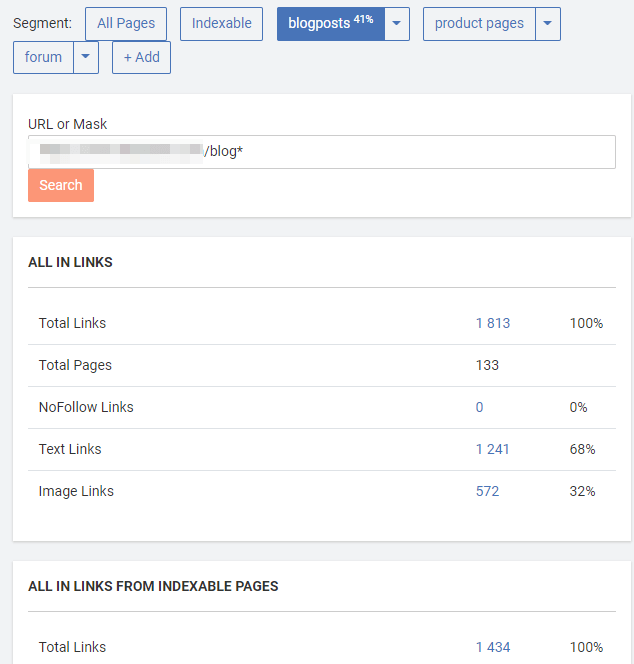
- Linking explorer. It lets you easily see the most popular anchors of links pointing to a page or group of pages.
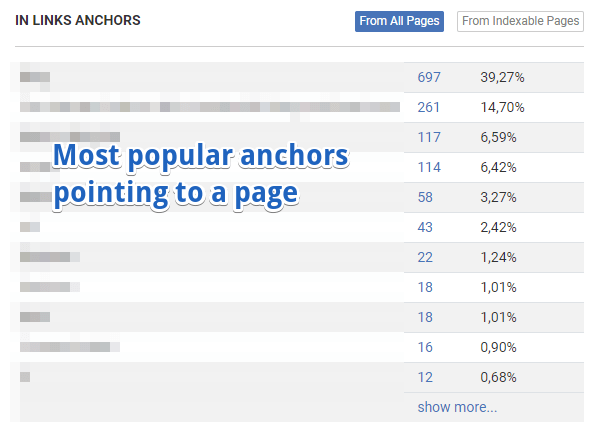
Also, it shows the most popular directories linking to a page.
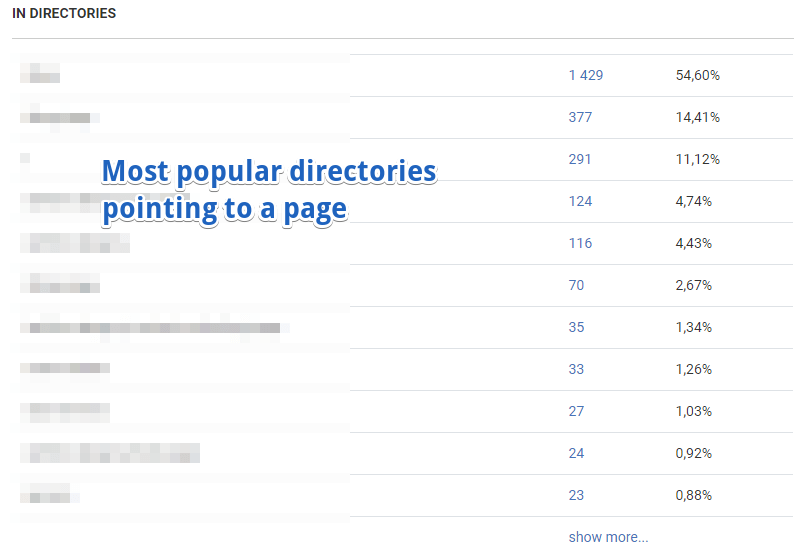
Here’s where page segments come in handy. You can quickly switch segments to see only the stats related to links coming from particular segments (i.e., from blog or product pages).
JetOctopus’s drawback
- No JavaScript crawling.
FandangoSEO
Pricing
FandangoSEO is available in three “sizes,” depending on the number of projects and pages you want to crawl. Starting at $59/month, the S plan lets you conduct 10 projects and crawl 150k pages per month. At $177/month, the M plan allows you to set up 50 projects and crawl 600k pages. Finally, the L plan comes with 100 projects and 1,8m crawled pages.
FandangoSEO is a Spanish crawler, and the name comes from the lively Spanish dance.
Like many other cloud tools, FandangoSEO offers good visualizations.
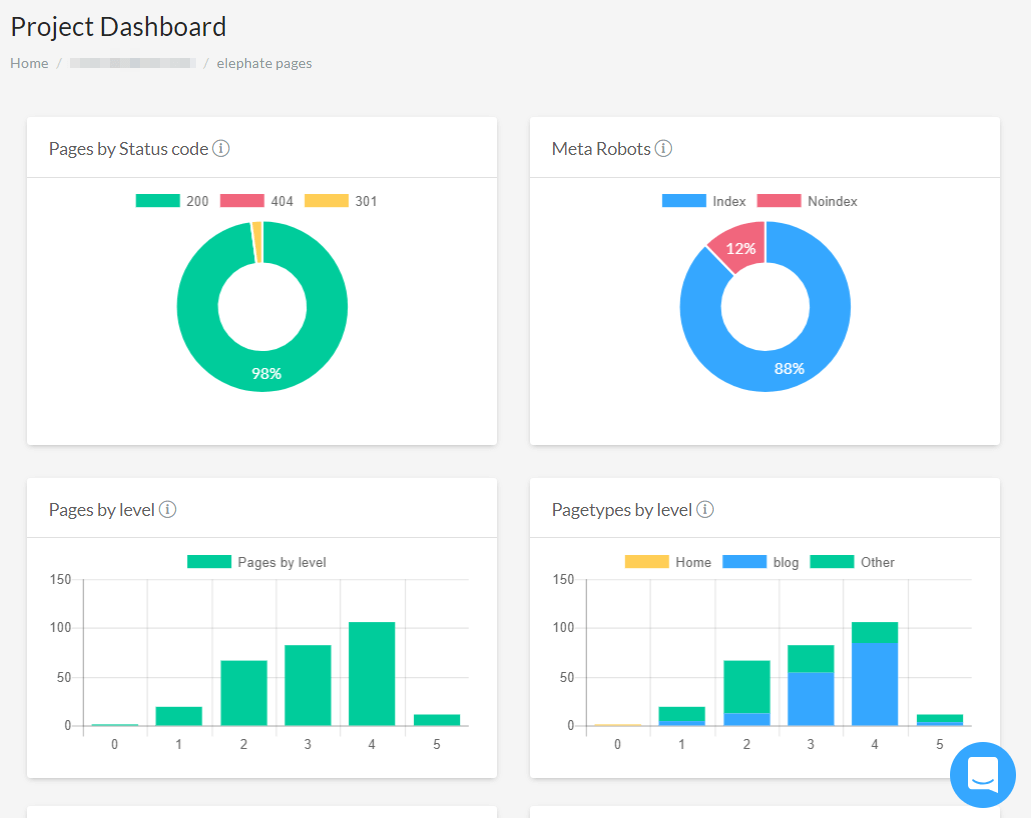
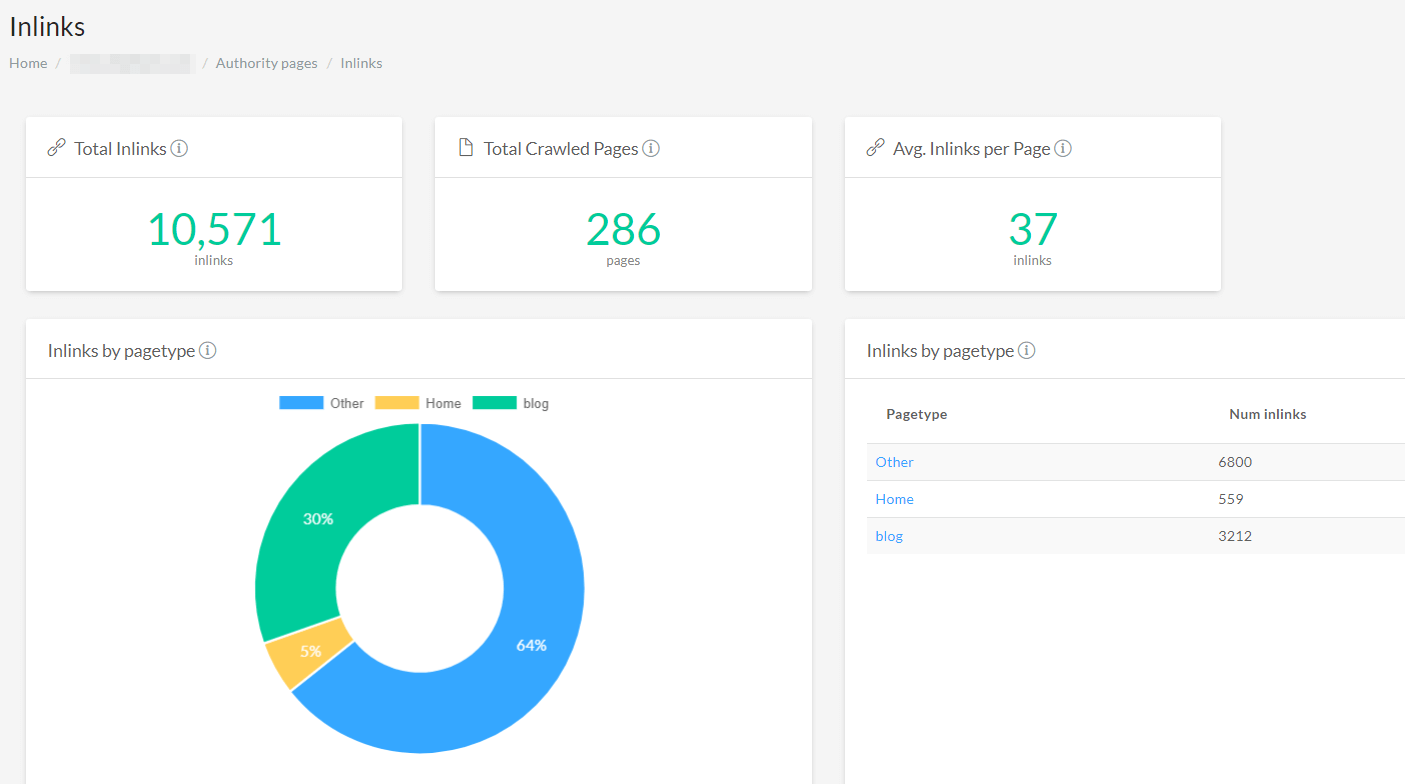
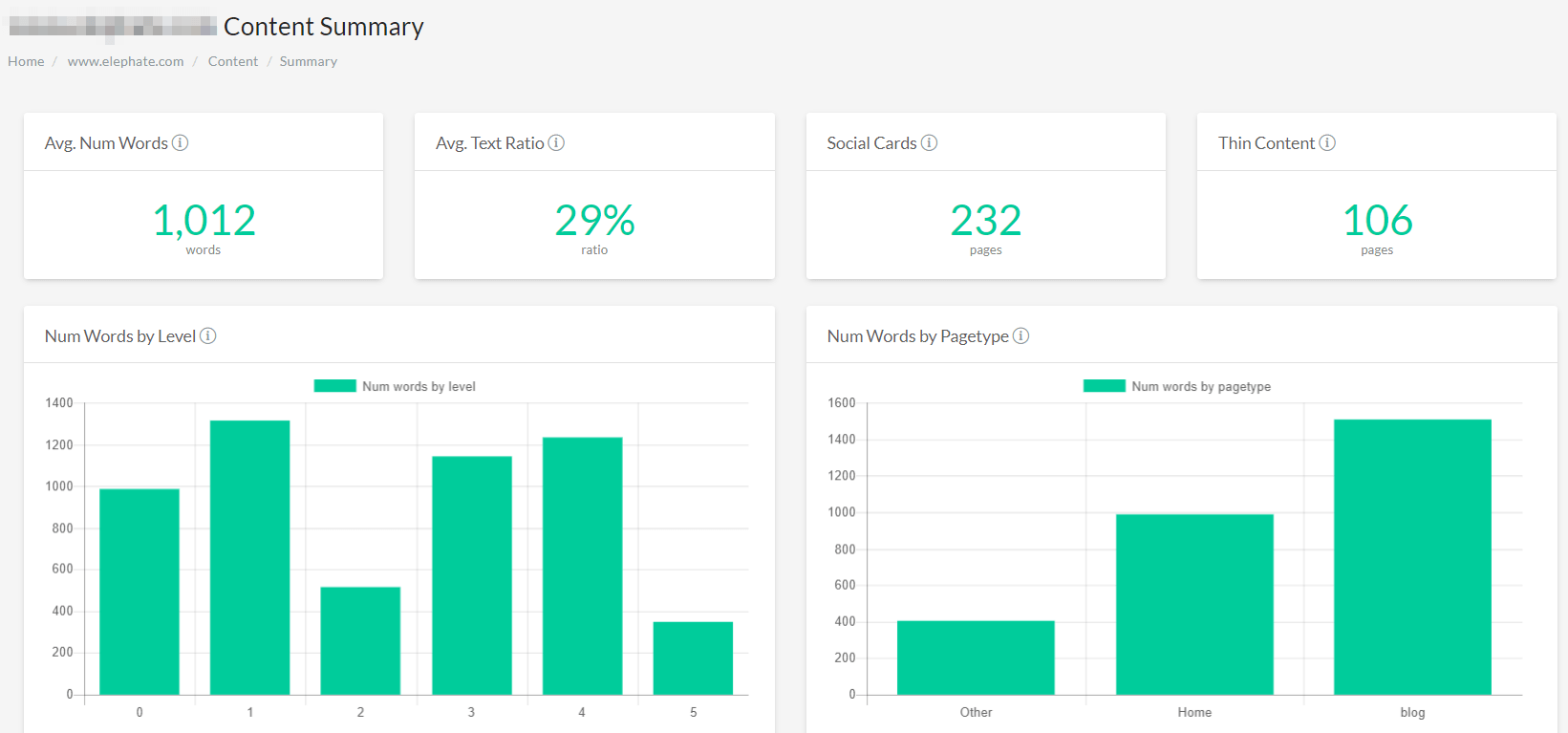
Notable features of the FandangoSEO Crawler
- Integration with server logs at no cost. FandangoSEO integrates with server logs (and like with DeepCrawl, you don’t need to pay extra for it). You can upload logs once or periodically (using their interface or FTP).
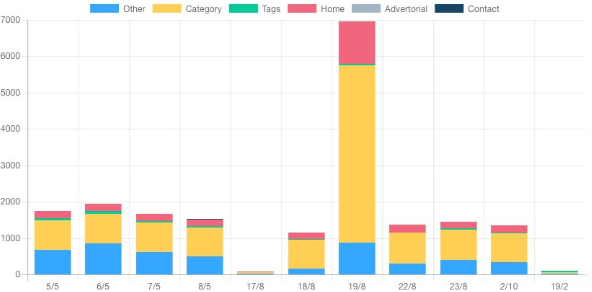
- Custom segmentation. Similarly to Botify, OnCrawl, or JetOctopus, FandangoSEO lets you define custom segments.
You can also see some reports based on the segments that you set up.
- Schema.org markup detection. You can easily see which URLs don’t have any markup implemented.
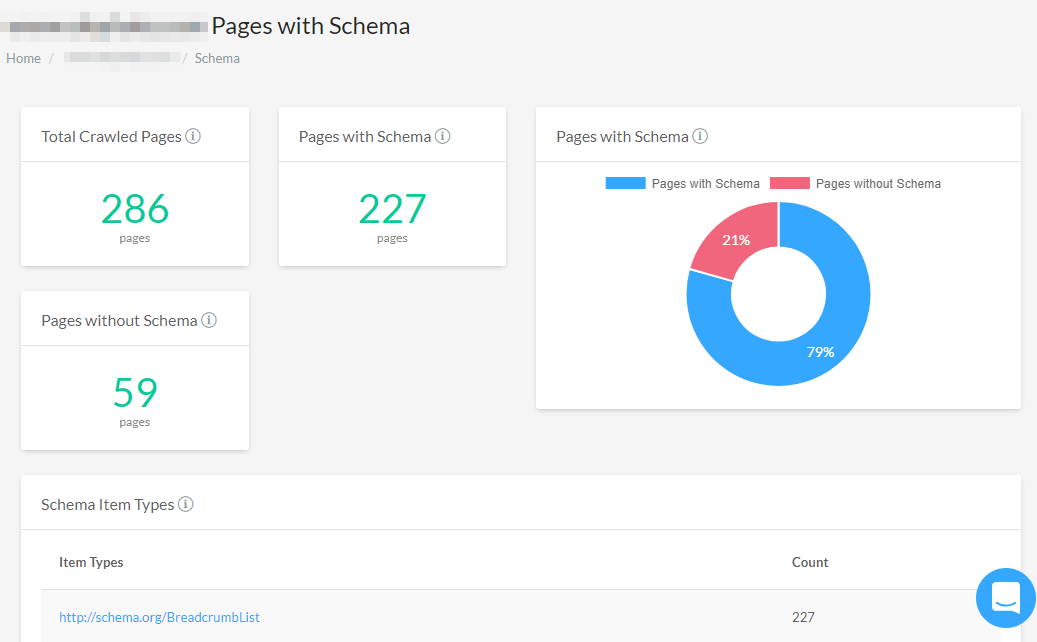
- Crawling your competitors’ websites. FandangoSEO lets you compare data between various projects, which makes it possible to crawl your competitor’s website.
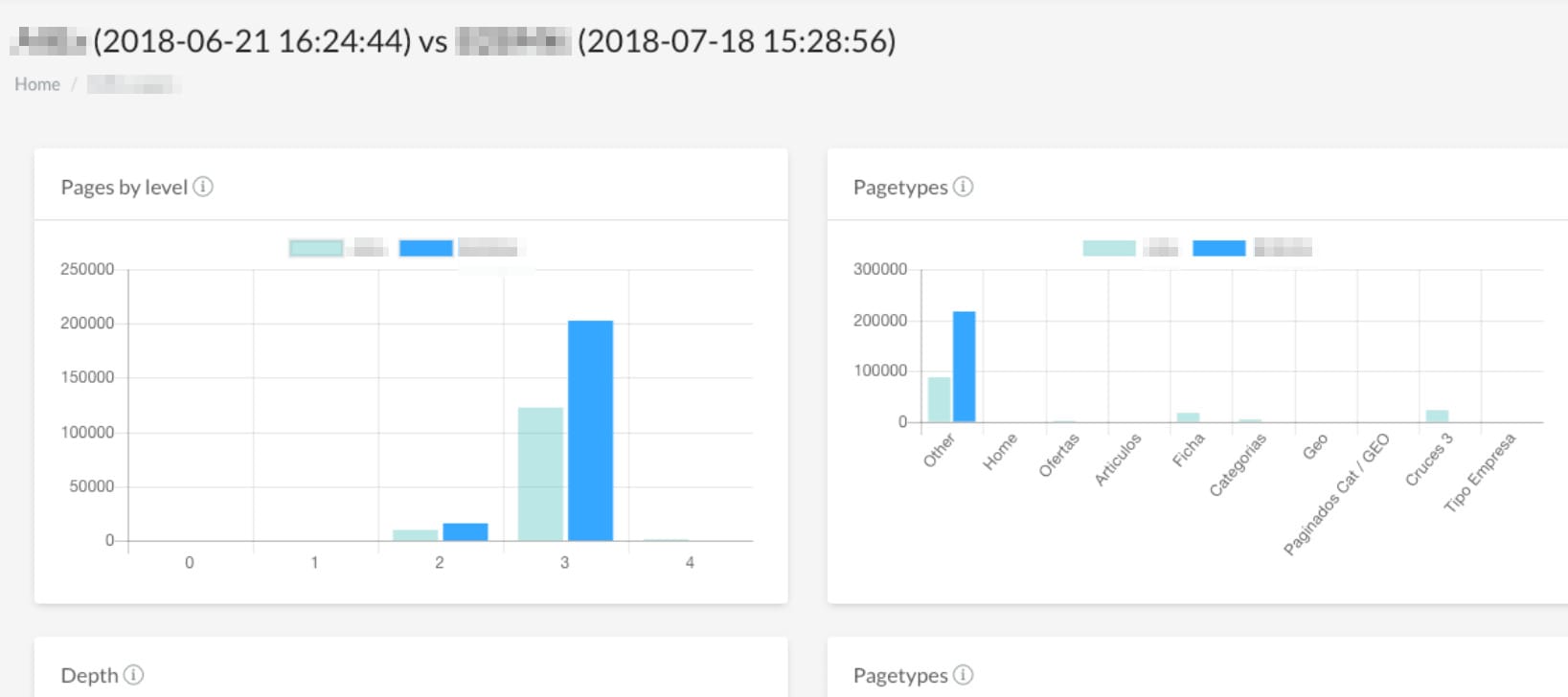
- Architecture maps. Similarly to Sitebulb and Website Auditor, you can see the architecture map with FandangoSEO.
- Integrate crawls with any data.
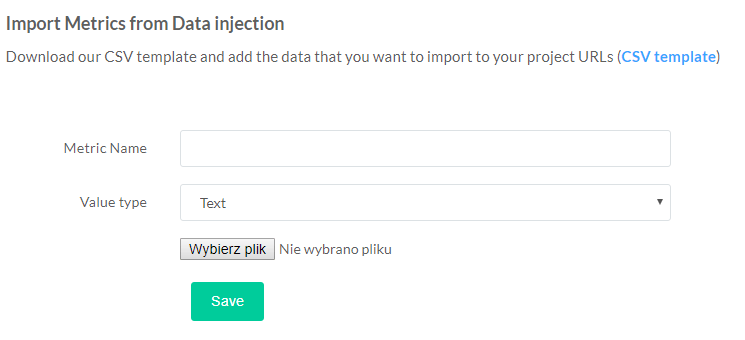
FandangoSEO disadvantages
- Additional columns can’t be added to reports.
- It doesn’t integrate with Google Analytics and Google Search Console.
ContentKing
Pricing
ContentKing offers three fixed plans as well as an enterprise plan. These plans differ greatly when it comes to the features they offer, ranging from technical possibilities to maintenance and data retention.
The fixed plans are: Basic at $39/month, Standard at $89/month, and Pro at $149/month.
Notable features of the ContentKing SEO Crawler
- Real-time monitoring, change tracking, and alerting. ContentKing is a unique crawler on the market since it is a real-time monitoring tool. It informs you in detail about things like on-page SEO changes, robots.txt changes, indexability issues, pages that got redirected, etc. Alerts are sent out if there are big changes or serious issues on your website. According to ContentKing’s representatives, the internal algorithm takes into account the impact of the changes/issues and the importance of the pages involved and then decides whether or not to send out alerts.
- ContentKing checks for OpenGraph and Twitter card markup, and the presence of tag managers and analytics software such as Google Analytics, Adobe Analytics, or Mouseflow.
- Advanced filter operators.
- Slack integration.
ContentKing’s disadvantages
- Filtering needs improvement. I need to be able to combine rules when filtering: “URL starts with X, contains Y, but doesn’t contain Z.”
- When viewing a list of issues, I can’t add additional columns (that feature is available only when viewing a full list of crawled pages).
Cloud-based tools at no additional cost?
You might be using other SEO tools for things like competition analysis or keyword research. Many of these tools, like SEMrush, Ahrefs, Moz Pro, or Searchmetrics, are also able to run a crawl of your website!
These tools are not as advanced as dedicated cloud-based crawlers, but if you need to run a basic SEO audit, they do a good job.
Ahrefs
The Ahrefs crawler (Site Auditor) is an integral part of Ahrefs Suite, a popular tool for SEOs. If you subscribe to Ahrefs (to use tools like the site explorer, content explorer, keywords explorer, rank tracker, etc.), you can use their crawler for free.
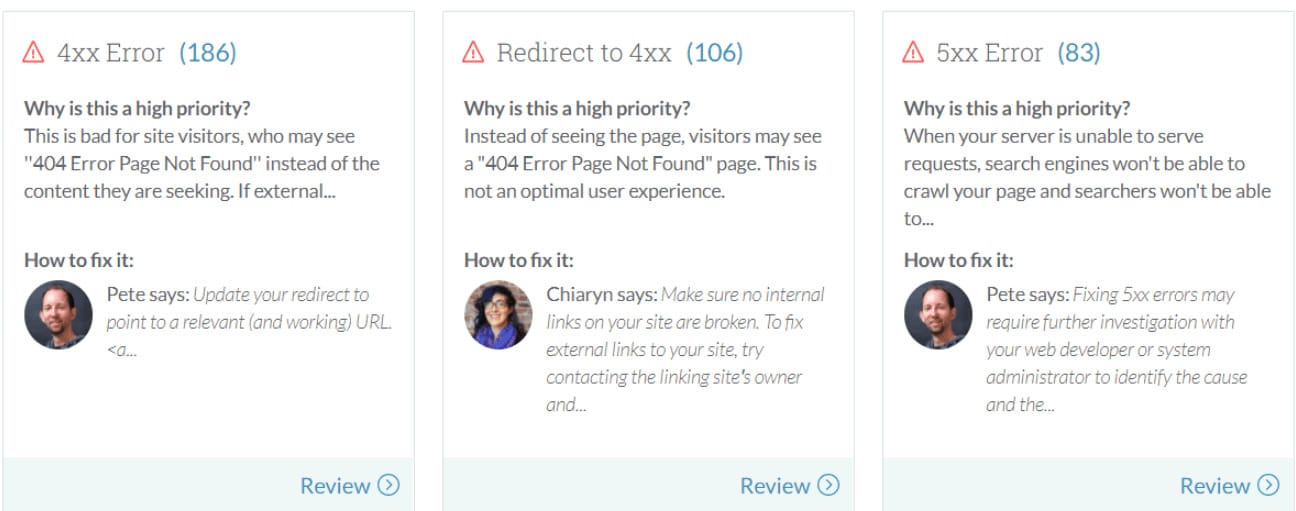
Ahrefs lets you easily filter the issues by importance (Errors, Warning, Notices).
For every issue, you can see if it’s new or if it was found in the previous crawl too.
Ahrefs’ advantage over other crawlers in its segment (Ahrefs/Moz/SEMRush) is that you can add additional columns to an existing report. You can also see which URLs are in the sitemap and which are not. It does have some limitations, though. It doesn’t integrate with GSC and GA. Similarly to Moz and SEMRush, you can’t share the crawl results with your colleagues, so only one person can work on the crawl at a time.
You can get around this limitation, though. If you use a single Ahrefs account within your agency, you can work simultaneously on the same crawl. The risk that you will be logged out is minimal.
Ahrefs recently released a new feature in their crawler. It’s called “Site Structure” and shows the distribution of HTTP codes, depths, content types, etc., across the website’s subfolders and subdomains.
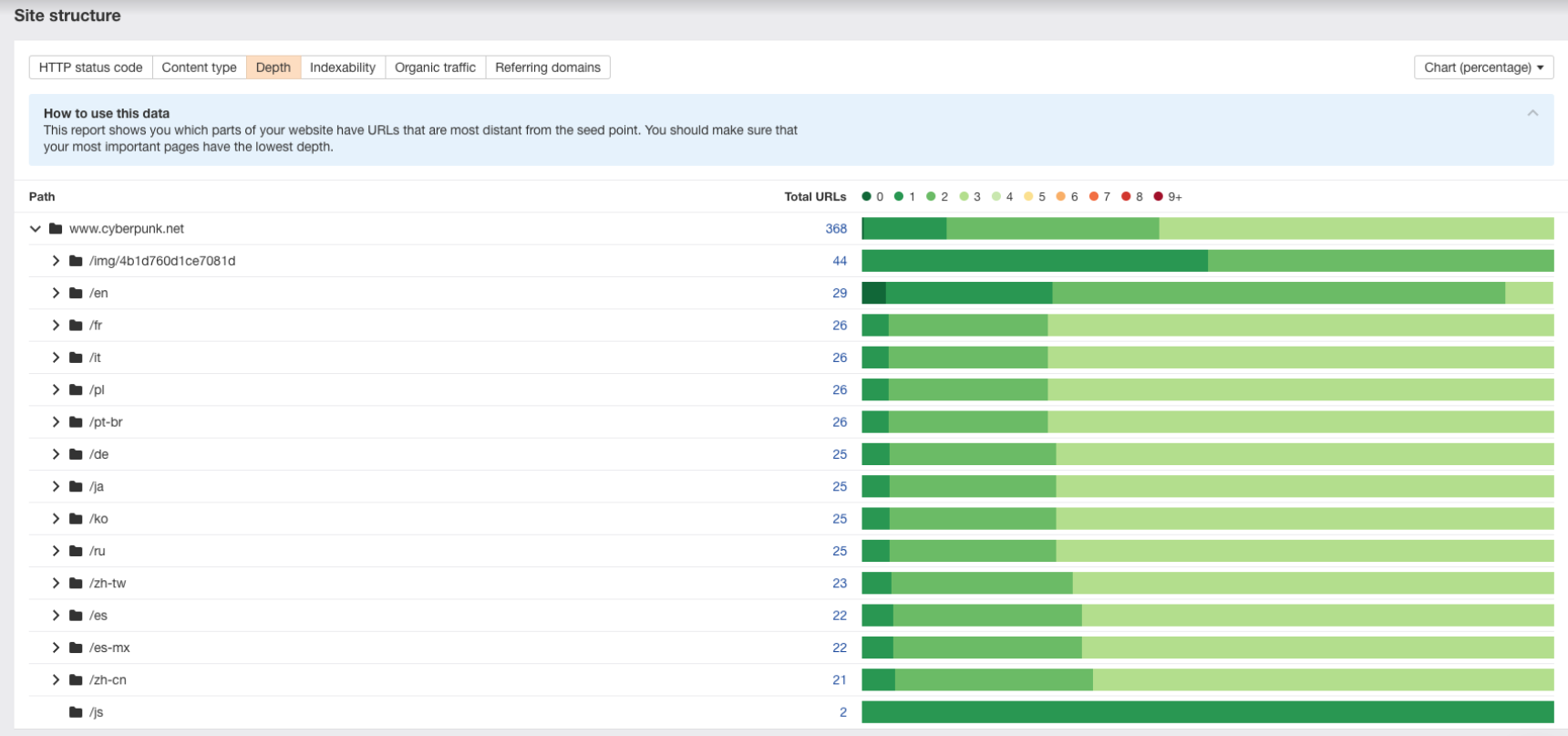
Depending on the Ahrefs plan you have, you can crawl 10k-2.5kk URLs.
Checklist for Ahrefs.
Moz
The Moz crawler is an integral part of Moz Pro.
On the one hand, this crawler lacks many functions and features that other crawlers support. On the other hand, it’s part of Moz Pro. So if you subscribe to Moz Pro, you can use the crawler for free. In addition to that, this crawler provides a few unique features like marking an issue as fixed.
Moz crawler integrates with Google Analytics, but it lacks integration with Google Search Console.
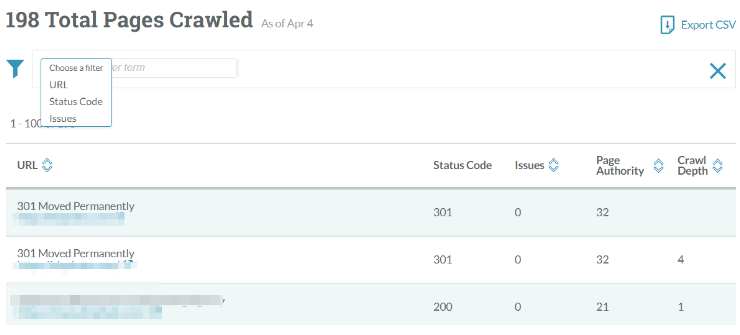
I appreciate that Moz provides a decent explanation for the detected issues.
It’s useful that the Moz crawler is integrated with other Moz tools and that you can see parameters like Page Authority and Domain Authority directly in the crawl data.
Other interesting features offered by the Moz crawler are the “Mark as fixed” and “Ignore” features. I think the Moz documentation explains it pretty well (emphasis mine):
“The tool is designed to flag all these issues so you can decide whether there’s an opportunity to improve your content. Sometimes you just know that you’ve fixed an issue, or you’ve checked that you’re happy with that page and it’s not something you’re going to fix. You can mark these issues are Fixed or Ignore them from your future crawls.”

Unfortunately, there are no reports related to hreflang tags, and the URL filtering is rather basic. If you want to perform some analysis related to orphan pages, it’s very limited – you can’t see the list of pages with less than x links incoming. Also, you can’t see which URLs are found in sitemaps but were not crawled.
Since August 2018, the Moz crawler offers an On-Demand crawl, so you can crawl projects outside of your Moz Pro Campaigns.
In my opinion, Moz is enough for basic SEO reports. However, I wouldn’t use it for advanced SEO audits. Its main competitors, Ahrefs and SEMRush, are much more advanced.
Checklist for Moz.
SEMrush
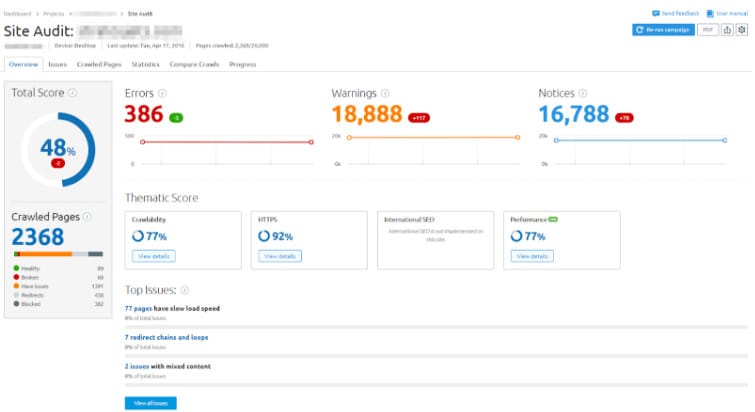
SEMrush is a well-known tool for competitor research. But it also allows you to crawl your website.
SEMRush is quite good at spotting basic SEO issues. When you go to the Issues tab, you will see all the detected SEO issues listed on a single dashboard. SEMRush divides the issues by importance (Errors/Warnings/Notices), and for every issue, you can see the trend so that you can immediately spot if the issue is new. Like the Moz crawler, SEMRush integrates with Google Analytics. The main drawback of SEMrush is poor filtering. That’s an area where SEMRush simply needs to catch up.
Let’s say you want to see the no-indexed pages. You go to Site audit -> Issues -> blocked from crawling. Unfortunately, this report shows you not only the no-indexed pages but also the ones disallowed by robots.txt, and you can’t filter the results.
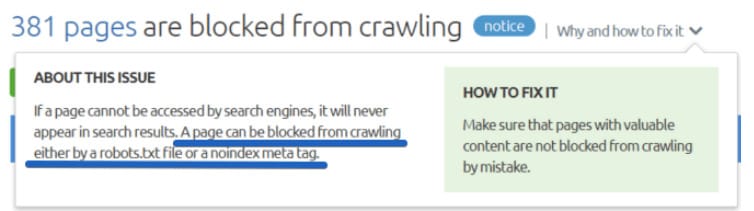
I really miss the ability to add a column with additional data.
If you need to create a basic SEO audit for a small website, SEMrush would be fine, but you can’t use it for large websites. The SEMrush crawler only allows for crawling up to 20k URLs per crawl.
Checklist for SEMrush
Should you get a dedicated crawler?
As I mentioned before, if you have an active account for Searchmetrics, Ahrefs, Moz, or SEMRush, you have access to a free crawler. Check if these tools are enough for your SEO audits. If they are, you can use them and save money.
I noticed an emerging trend with many SEO tools adding an SEO crawler feature to their toolkit. For instance, Clusteric, primarily made for link auditing and competitor analysis, now offers an SEO crawler feature. So the list of SEO tools that offer a crawler on the side is probably going to expand in the near future.
Which SEO Crawlers support JavaScript crawling?
Nowadays, an increasing number of websites use JavaScript. Crawlers try to adapt, so they have started supporting JavaScript.
|
Crawler |
Support for JavaScript crawling |
|---|---|
|
DeepCrawl |
Yes (it’s included in Corporate plans. For smaller packages: Starter and Consultant: price upon request) |
|
Screaming Frog |
Yes |
|
Sitebulb |
Yes |
|
Ryte |
Yes (available in the Business Suite) |
|
Moz |
No |
|
Ahrefs |
Yes (for Advanced and agency plans) |
|
Botify |
Yes (it’s not included in basic plans) |
|
OnCrawl |
Yes (it cost 3x more credits) |
|
Searchmetrics |
Yes (it costs 2x more credits) |
|
Website Auditor |
Yes |
|
NetPeak Spider |
Yes |
Disclaimer: Things I was not able to test
Although I did my best, I was not able to test everything. Some examples include:
- Does a crawler have maintenance errors? Maybe it often crashes, not allowing you to finish a large crawl? Maybe. Even if I noticed it, I can’t be sure if it’s constant or just temporary. So, I did not mention it.
- Are the reports provided by a crawler enough for most use cases? Are reports thorough and in-depth?
Which SEO Crawler is the Best?
There is no single best SEO crawler. Everything depends on your needs, expectations, and budget.
I can, however, list the aspects you should take into consideration when choosing a crawler to pay for.
The Perfect Crawler:
- Stores the crawl data forever.
- Is reasonably priced.
- Should have a crawling limit that lets you crawl all the websites you need to (if you need a crawler for your SEO agency, think 1 million URLs/month at the very least).
- Has website structure visualization
- Integrates with any data.
- Easily integrates with server logs, Google Analytics, and Google Search Console.
- Lets you easily share the crawl with your clients and colleagues (cloud crawlers are typically much better at this).
- Can show you a list of near-duplicates.
- Groups your pages by categories.
- Can crawl JavaScript websites.
- Allows for exporting data to CSV/Excel even if there are millions of rows to export.
- Provides a list of all detected issues on a single dashboard.
- Lets you see which URLs are orphans (not found while crawling, but placed in the sitemap).
- Lets you compare two crawls to see if things are going in the right direction.
- Lets you easily add columns with additional data to existing reports.
- Is the one that satisfies your needs!
Additional SEO crawlers to check out
There are still some tools to consider that I did not review in this article.
Give them a go if you still haven’t decided which crawler to go for and want to test additional options:
- SEOCrawler.io
- Raven Tools
- Searchmetrics Crawler
- IIS Site Analysis Web Crawler (a free tool)
- Xenu’s Link Sleuth (a free tool)
- BeamUsUp (a free tool)
- SEOSpyder by Mobilio Development
- SEOMator
- CocoScan
Wrapping up
My job is over. Now, it’s up to you!
Choose a crawler, research its features, ask for a trial, and test it – see if it fits your needs. Push it to its limits and integrate it with any data you have.
Remember: it’s common that some advanced features are only available with Pro subscriptions. Before purchasing, make sure the plan you’re buying gets you all the features you need.
Have fun and good luck! If you have any questions, feel free to reach out.
And, if you’re struggling with technical SEO analysis and can’t identify all the issues on your site, contact us and tell us how we can help!
If you’re a crawler representative, and you have recently updated your crawler, let me know what needs changing in the article.
Thank you to all the crawler representatives that helped me with creating this article.

Hi! I’m Bartosz, founder and Head of Innovation @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with your organic growth – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!







