We live in a time of a web revolution. Every day, more and more sites switch from pure HTML to JavaScript-enriched websites. While users get the benefit of modern technology (if they’re willing to update their browsers), web crawlers struggle with it.
In the search market, Google is the unquestionable leader. It leads not only in market share but also in technology. However, even Google has some limitations. Googlebot doesn’t interact with your website like a normal user would, and this may prevent it from discovering some of your content, particularly if it’s dependent on JavaScript.
One solution is to present crawlers with a pre-rendered version of the HTML file instead of the JavaScript code. This technique is not considered cloaking and is allowed by Google.
In order to do that, we have to be able to detect whether a request is made by a user or a bot. To learn more about search-friendly JavaScript delivery, you can watch this Google I/O ‘18 presentation.
Let’s start with some basics.

What are Crawlers?
If you’re seeking a way to detect and verify crawlers, you probably already know what they are. Nonetheless, crawlers (called spiders sometimes) are computer programs (bots) that crawl the web. In other words, they visit webpages, find links to further pages, and visit them, too. Often they map content that they find to use later for search purposes (indexing), or help developers diagnose issues with their websites.
Why Would Anyone Want to Detect Them?
If you own a website and would like to be visible in search results, for example, Google search results, you need to be visited by its crawlers first. They have to be able to crawl through your site and index your content.
If you find SEO problems on your website, checking server logs for Googlebot requests may be one of the steps you’d need to take in order to diagnose the issues.
Wonder how to perform server log analysis? Take advantage of our server log analysis services or check out this brilliant article by Kamila Spodymek!
There are also more specific purposes. For example, you might be legally forced to restrict access to your site in some countries. While blocking users you should allow access for search bots from that country, especially if that country happens to be the USA (Googlebot crawls mostly from the US).
As stated in the beginning, the ever-growing usage of JavaScript on the web is certainly beneficial to users, but rendering JS is a challenge for search engines.
Read our ultimate guide to JavaScript SEO to find out.Wondering how does Google see your JavaScript-based website?
If your website is not properly handled by bots, or your content changes frequently, you should render your pages dynamically, and serve rendered HTML to crawlers instead of JavaScript code.
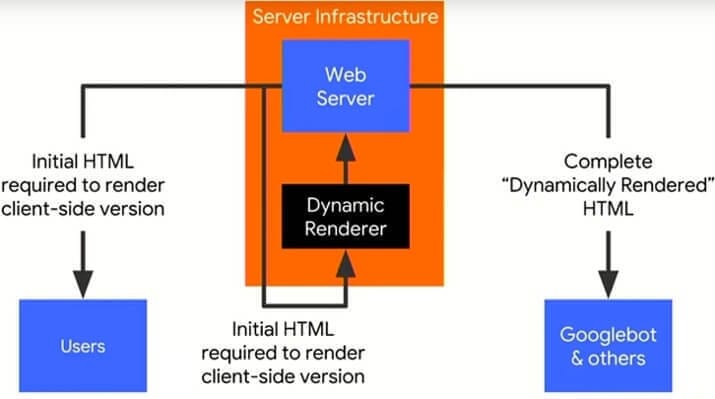
Obviously, in order to do so, you have to know if a request was made by a real user, or by a crawler.
User Agent detection – Hello, my Name is Googlebot

When you’re browsing the web, you might sometimes feel anonymous. Your browser, however, never does. Every request it makes has to be signed with its name, called User Agent.
For example, that’s the User Agent of a Chrome browser: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36.
Bots also have unique User Agents, for example, the following name belongs to the desktop version of Googlebot: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Couldn’t they Just Lie?
A true Googlebot will not be deceptive and will introduce itself with its true name.
However, there are other bots that might be harmful that will introduce themselves with Googlebot’s name. Some browsers can also change the User Agent.
For example, you can fake Googlebot hits using the Google Chrome Inspect tool. We SEOs also often visit pages, or even crawl whole sites, introducing ourselves as Googlebot for diagnostics purposes.
However, if you’re looking for a way to detect all requests from a specific bot, and you don’t mind including requests from sources that lie about their identity, the User Agent detection method is the easiest and fastest to implement.
When to validate crawler request
Before I explain how to validate crawler requests, let’s backtrack a little bit and explore scenarios in which you should do it.
- The first scenario that we’ll explore is server logs analysis. You surely don’t want that pesky scraper that visited your site to show as Googlebot in your logs. Imagine that for some reason, part of your site is not indexed because it’s blocked by robots.txt, but in your logs, you could see hits to that part made by a scraper that doesn’t give a damn about robots.txt. How are you going to establish if the true Googlebot was able to access these pages or not if you don’t filter that scraper out?
- Another situation you really want to avoid is serving scrapers with a pre-rendered version of your site. This is harmful in two ways. First: pre-rendering costs the server processing time. This cost is not negligible, and a lot of requests can hurt your performance significantly! You want to do the hard work of rendering only for crawlers that you care about. Second: rendering JavaScript can be difficult. If those bothersome scrapers will get non-rendered JavaScript, there is a great chance that some of them will be unable to steal your content.
Struggling with rendering issues? Go for Rendering SEO services to address any bottlenecks limiting your search visibility.
Verification Method
If you need to verify a request’s source properly, you need to check the IP address from which the request was made.
Lying about that is difficult. One can use a DNS proxy server and hide the true IP, but that will reveal the proxy’s IP, which can be identified. If you are able to identify requests that originate from the crawler’s IP range, you are set.
There are two methods of verifying the IP:
- Some search engines provide IP lists or ranges. You can verify the crawler by matching its IP with the provided list.
- You can perform a DNS look up to connect the IP address to the domain name.
Ok, now let’s get to the meat.
IP Lists and Ranges
As stated above, some popular search engine crawlers provide static IP lists or ranges. The advantage of comparing the crawlers’ IP address with the list is the fact that you can do it automatically. It’s especially useful for a large-scale check.
Unfortunately, the IP list may change in the future. In this case, comparing the IP with the list won’t be sufficient.
Some of the search engines that provide the IP lists include: :
Twitter and Facebook let you download their current IP lists by running the following Bash commands.
| Bot | Command |
| whois -h whois.radb.net — ‘-i origin AS32934’ | grep ^route | |
| whois -h whois.radb.net — ‘-i origin AS13414’ | grep ^route |
Bash is a Linux command line environment, which you can simulate on Windows using CygWin.
DNS Lookup
For bots that don’t provide official IP lists, you’ll have to perform a DNS lookup in order to check their origin. This method is also necessary in case the IP addresses change in the future.
DNS lookup is a method of connecting a domain to an IP address. As an example, I’ll show you how to detect Googlebot, but the procedure for other crawlers is identical. You’ll need to start with a request IP address, and then try to determine its origin domain.
The first step in the process is called reverse DNS lookup, in which you’re going to ask the server to introduce itself with the domain name.
If you’re using Windows Command Prompt, you are going to use the nslookup command. On Linux the equivalent command is host.
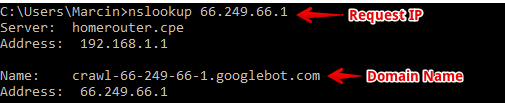
Evaluate the nslookup command with the request IP and read the domain name. It has to end with the correct domain. The correct domain for Googlebot is .googlebot.com.
It’s not enough to search the name for that string. To ensure proper verification, it has to be on the very end! For example, a domain named googlebot.com.imascam.se definitely doesn’t belong to a valid Googlebot (I’ve just made it up).
How to be 100% Sure?
There is a way to cheat this method. One can set up a redirect from their scam server to the valid Googlebot server. In this case, if you ask the server for its name, you’ll get the proper Googlebot domain!
In order to rule that possibility out, you have to ask the domain name for its IP address. You can do that using the very same command, but this time with the domain’s name instead of IP address.
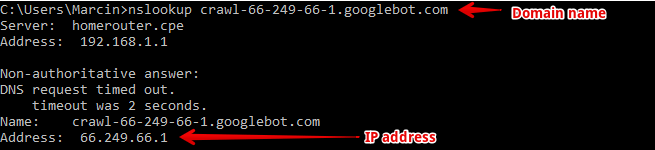
If the IP address from the response matches the IP of the request, you’re set. You’ve validated a true Googlebot! Here’s a list of popular crawlers’ domains:
| Service Name | Domain name |
|---|---|
| Baidu | *.crawl.baidu.com |
| Baidu | *.crawl.baidu.jp |
| Bing | *.search.msn.com |
| Googlebot | *.google.com |
| Googlebot | *.googlebot.com |
| Yahoo | *.crawl.yahoo.net |
| Yandex | *.yandex.ru |
| Yandex | *.yandex.net |
| Yandex | *.yandex.com |
A small bonus: in the case of Bing, you can verify the IP directly on this page but you cannot automate the verification process, as it’s human-only.
Whitelisting
You should remember that the published IP ranges may change in the future. Such a list will surely survive in some server configurations, making them vulnerable to deception in the future.
Nonetheless, you shouldn’t use the lookup method for every request! That will kill your Time to First Byte (TTFB), and ultimately slow down your website. What you want to do instead is to create a temporary IP whitelist.
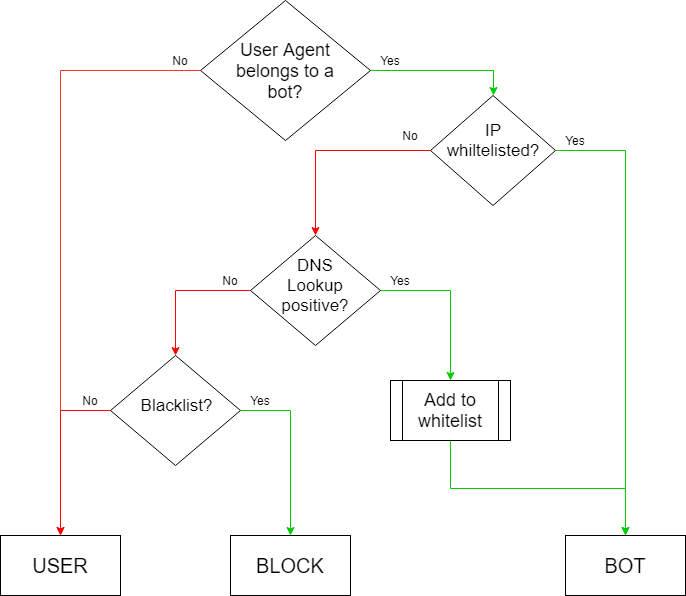
The basic idea is when you get a request from Googlebot’s user agent, you check your whitelist first. If it’s on the list, you know it’s a valid Googlebot.
In cases where it’s coming from an IP address that’s not on the whitelist, you’d want to do the nslookup. If the address is verified positively, it enters the whitelist.
Keep in mind that the whitelist is temporary. You should periodically remove or re-check all the IP addresses. If you’re getting a lot of false requests, you might want to think also about a blacklist to rule out such requests without doing the DNS lookup.
Below you’ll find a simple diagram that represents the idea described above.
Here’s what you can do now: Still unsure of dropping us a line? Read how technical SEO services can help you improve your website.NEXT STEPS
Summary
Before you jump into implementing these solutions, ask yourself what you really need. If you need to detect bots and don’t mind false positives, then go for the simplest User Agent detection. However, when you’re looking for certainty, you’ll need to develop the DNS lookup procedure.
While doing so, keep in mind that you really want to avoid increasing your server response time, which DNS lookup will certainly do. Implement some method of caching the lookup results, but don’t hold them for too long, because IP addresses of search engine bots may change.

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!