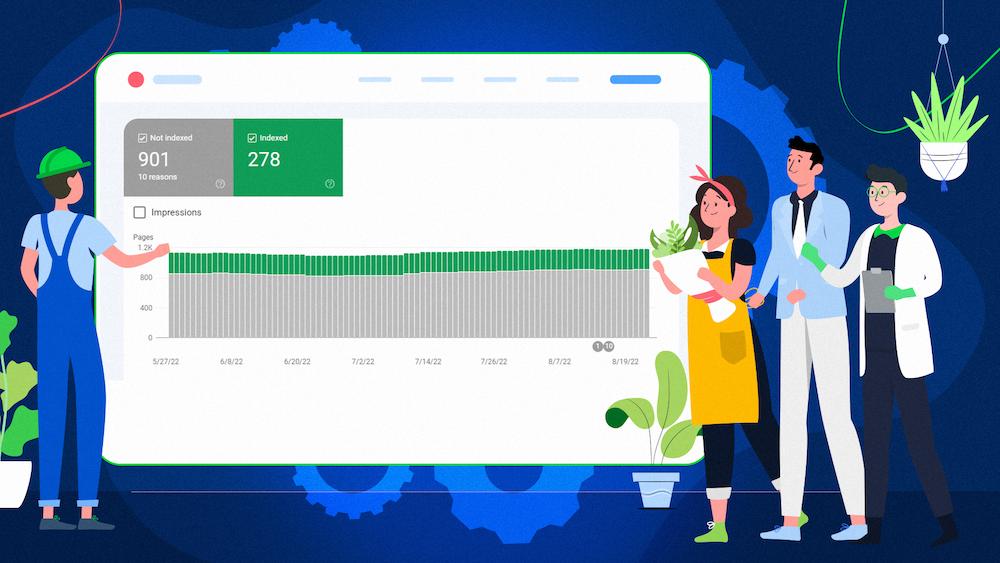
Before your pages appear in search results and drive traffic to your site, they need to be indexed.
Unfortunately, getting indexed is a challenge, especially if you have a large website. According to our research, 16% of valuable pages on websites are not indexed.
Before taking steps to improve your site’s indexing and search performance, it’s crucial that you check your site’s indexing status and identify which of your pages are indexed correctly and which aren’t.
One challenge you may be facing is finding reliable methods to check your site’s indexing status that let you analyze URLs in bulk. If this is the case, you’ve come to the right place.
There are a few useful tools that can help you determine your site’s indexing status and assist in a more thorough analysis of each URL to identify why it’s not indexed.
Follow my advice in this article to learn how to check a large website’s indexing status, analyze the issues that prevent pages from getting indexed, and find the right solutions.
What to do before inspecting your website’s indexing status
Before checking your indexing status and addressing your issues, you need to have a proper indexing strategy.
By creating it, you can determine which pages are essential and should be indexed and which ones should be excluded from indexing.
Some of your pages can be low on quality or contain duplicate content, and users shouldn’t find them in search results. As a rule, these are the kinds of pages that should be kept out of the index.
Here are a few examples of pages that shouldn’t be indexed:
- Archived content,
- Login- and password-protected pages,
- URLs with added parameters, created as a result of sorting or filtering,
- Internal search results,
- Thank you pages.
If you don’t want a page to be indexed, you can:
- Include appropriate directives for bots in the robots.txt file to prevent them from crawling a given page,
- Implement the noindex tag to prevent search engine bots from indexing a page.
URLs that haven’t been indexed and should remain this way don’t require your attention. Instead, focus on the pages that aren’t indexed but should be.
As a rule of thumb, you should aim to have the canonical versions of your pages indexed, and they should be submitted in your sitemap.
So how exactly can you find out which pages are indexed and which ones aren’t?
Methods to check your indexing status and diagnose indexing issues
There are a few useful tools to check your site’s indexing status.
But keep in mind that most of them have limitations on the number of URLs you can check. When looking online, you may come across many tools that are unreliable.
I will show you which tools show the most accurate information and workarounds to extend their limits.
Also, I will introduce you to a new indexing analysis tool developed by our sister company, ZipTie.
The “site:” command
One popular method to check a site’s number of indexed pages is to input the “site:” command in Google Search, followed by the domain name, such as “site:onely.com.”
Although it lets you check the indexing status of a website, the data you will see can be misleading or inaccurate, as the numbers are only estimates.
This method will be particularly inaccurate for large websites with dynamically changing content.
It may happen that every time you use it, the results will show a completely different number of indexed pages for your domain.
However, while the “site:domain” command is far from optimal, you can use the “site:URL” command, where you input a specific URL instead of a domain name. You can then learn whether the particular URL has been indexed.
John Mueller has recommended this solution:
Using site:-queries is useful for checking individual URLs, but I wouldn't use the counts for diagnostics purposes.
— E-e-eat more user-agents (@JohnMu) April 16, 2019
Tools in Google Search Console
Google Search Console offers much better tools for checking your Index Coverage.
If you don’t already use them regularly, start right now – they should become your standard SEO monitoring tools.
Let me describe them in more detail and advise how to make the most of them on a large website.
The Index Coverage (Page Indexing) report
The Index Coverage (Page Indexing) report in Google Search Console gives you data from Google about which pages are indexed.
Additionally, it provides you with insight into the specific statuses of your URLs concerning their discovery, crawling, and indexing, and, if applicable, what issue Google has found that prevents them from being indexed.
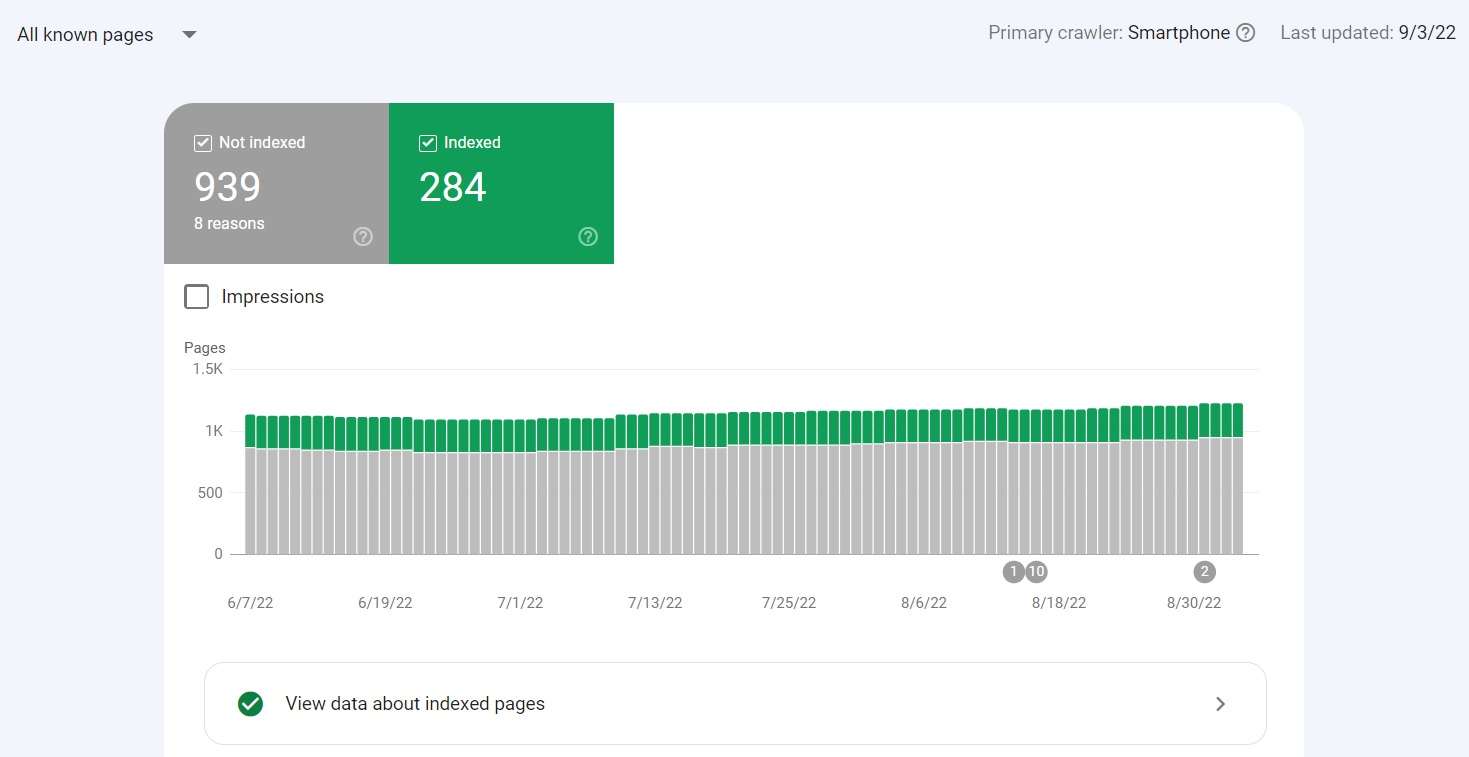
The Index Coverage (Page Indexing) report shows two statuses:
- Not indexed – for pages that aren’t indexed.
- They may struggle with errors such as the 5xx HTTP status code, incorrect disallow directive in the robots.txt file or incorrect usage of the noindex tag.
- Sometimes Google systems may decide not to index a page that was available to them for crawling for other reasons.
- Indexed – for pages that are indexed. Some of them may still be dealing with issues you should investigate, but no critical problem prevented them from being indexed.
Depending on what data you want to display, in the top left corner, you can choose:
- “All known pages” – for all URLs that Google has discovered in any way,
- “All submitted pages” – for URLs that Google found in your sitemap,
- “Unsubmitted pages only” – for URLs that Google discovered while crawling even though they’re not on your sitemap.
Ordinarily, the “All submitted pages” view should contain all pages you want to be indexed.
If some pages appear in “Unsubmitted pages only,” and they should be indexed, place them in your sitemap. If they shouldn’t be indexed, it means Google finds them elsewhere, perhaps through links.
The report’s main limitation is that each report displaying specific issues shows only 1000 pages. Luckily, there are ways around it.
One solution is to create separate domain properties for different website sections.
An alternative would be to divide your pages by creating multiple sitemaps and narrowing the report down to a separate sitemap.
It’s recommended that each sitemap contains a maximum of 50000 URLs.
There are many angles to dividing the pages between sitemaps. Consider arranging them in a way that will help you group similar types of content for easier analysis.
Here are some suggestions:
- Separate sitemaps for different types of content, e.g., categories, products, blog posts,
- Separate sitemaps for a selected amount or kind of products,
- Separate sitemaps for various language versions of the site.
Now, choose one of the sitemaps and navigate to the “Why pages aren’t indexed” section of the report.
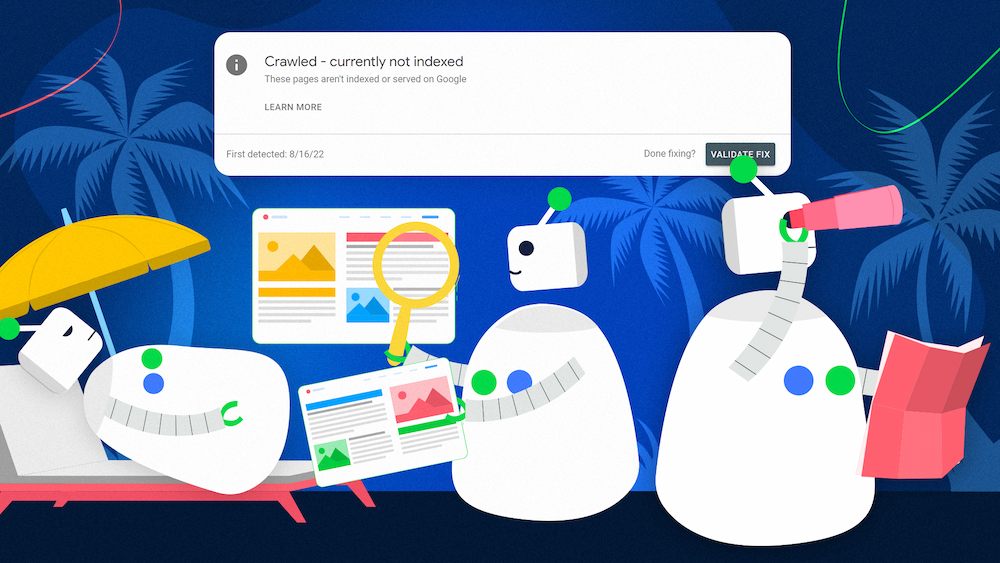
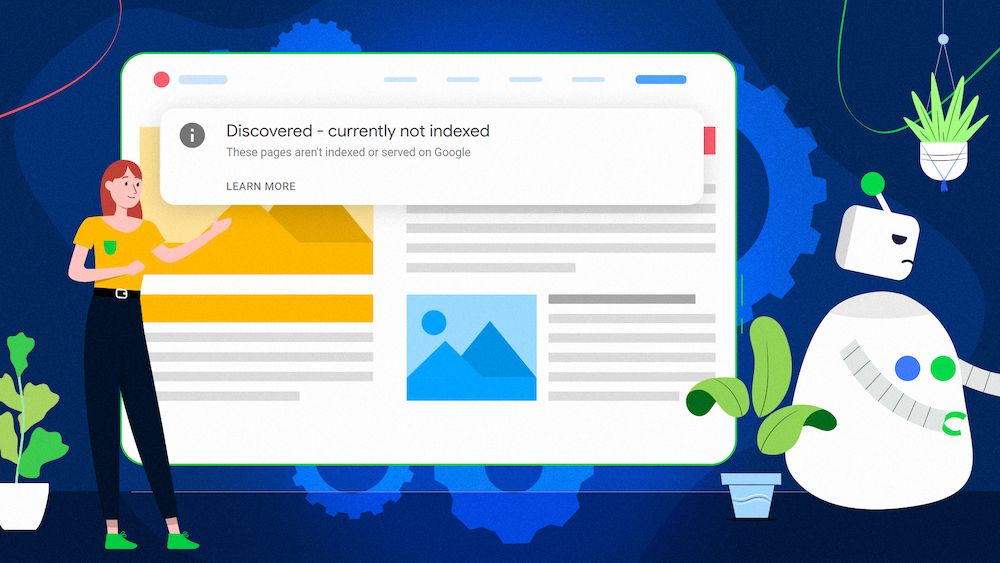
Go through the issues it displays – on the right, you can see the number of affected pages and learn which issues are the most common. You can check our other articles on how to deal with often occurring “crawled – currently not indexed” report and “discovered – currently not indexed” report.
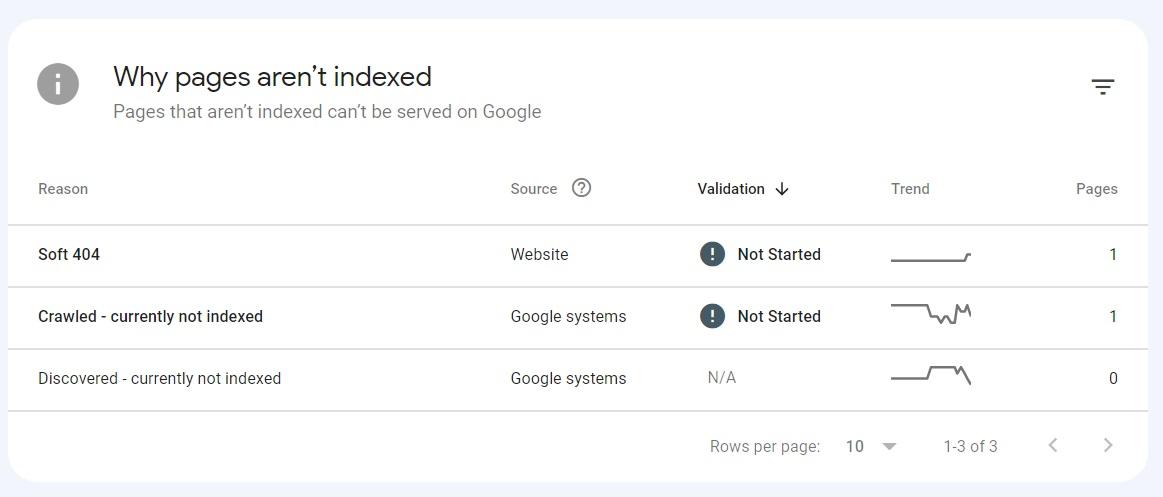
The report’s statuses describe the causes for each issue quite descriptively, and in most cases, they point to the actions you need to take to fix them.
Review how to address each status in my complete guide to Google Search Console’s Index Coverage (Page Indexing) report.
Look for patterns in your excluded pages. If many pages have similar content or layout, reviewing only a portion of URLs can give you an idea of what the remaining pages may be struggling with.
URL Inspection tool
Another helpful feature available in Google Search Console is the URL Inspection tool.
It lets you check whether a specific URL is in Google’s index and view tons of additional information. You can use this tool to complement the data you receive from the Index Coverage (Page Indexing) report.
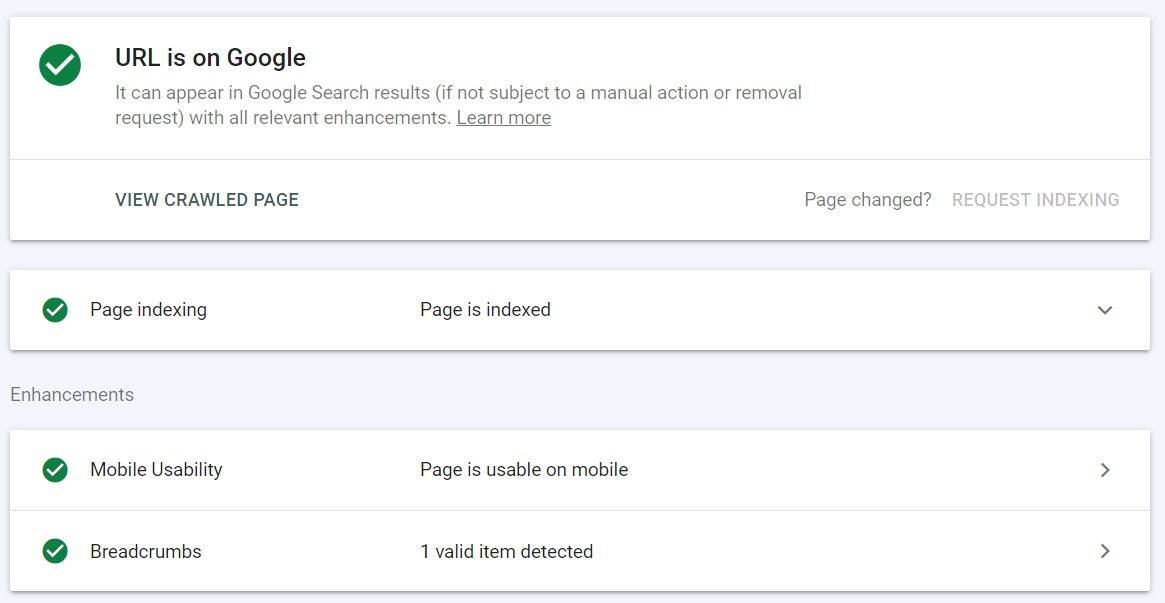
Here is an overview of the most important features of the URL Inspection tool:
- The presence status – whether or not the URL is eligible to appear in Google search results and any warnings or errors detected by Google.
- View crawled page – technical details such as the HTML and HTTP response that Google received.
- Request indexing – use it to ask Google to re-crawl and re-index your URL. There is a daily limit for this feature. Though it’s not explicitly specified in Google’s documentation, it is mentioned as a method to submit “just a few URLs”. It may allow you to submit up to 50 URLs.
- Details on a page’s coverage status, namely:
- Whether any known sitemaps point to the URL,
- The referring page – a page that Google could have used to discover the URL,
- When the page was last crawled,
- Whether a page is crawlable,
- Whether a page can be fetched from the server,
- Whether a page is indexable,
- The canonical URL declared by the user,
- The canonical URL that Google selected instead.
- Enhancements – this section shows whether Google found valid structured data on a page, as well as details on a page’s mobile usability and AMP.
- Test Live URL – you can run a live test on a URL, e.g. if you want to validate fixes or changes.
The URL Inspection tool requires you to check your indexing status per URL, which can be time-consuming if you have a large website.
However, analyzing a sample of pages can already point you to what issues your site is dealing with.
Instead of inspecting all URLs, you can select and check a portion of URLs that have been excluded from Google’s index. You can also collect URLs that should be indexed but are getting no organic traffic.
Moreover, your site may have the following sections:
- example.com/shop
- example.com/blog
- example.com/gallery.
You can pick a number of URLs to analyze from each distinctive section. But don’t just select a few URLs – use a representative sample for each section.
Are your pages “Excluded by noindex tag” in Google Search Console?
Read our article to make sure that you used the noindex tag on purpose.
URL Inspection API
In 2022, Google announced the release of the URL Inspection API, which allows you to send up to 2000 requests per day for a single Google Search Console property.
This is great news for anyone who found the URL Inspection Tool data useful but struggled with being able to only check one URL at a time. By accessing the URL Inspection data through an API, you can automate the process, which opens up multiple new possibilities of using this information.
Limitations of Google Search Console tools
The Google Search Console tools are not without their flaws.
In October 2021, users reported seeing URLs in the Index Coverage report marked as “Crawled – currently not indexed.” However, when inspected with the URL Inspection tool, these URLs were listed as “Submitted and indexed” or another status.
Google responded that this situation is not a bug but rather a limitation of the Index Coverage report:
This is because the Index Coverage report data is refreshed at a different (and slower) rate than the URL Inspection. The results shown in URL Inspection are more recent, and should be taken as authoritative when they conflict with the Index Coverage report. (2/4)
— Google Search Central (@googlesearchc) October 11, 2021
Report an Indexing issue
Google announced in April 2021 that it was introducing a feature called Report an Indexing Issue to help users make Google aware of an indexing problem. The feature is currently available in the US.
For those needing further support, signed-in Search Console users in the US will soon see a “Report an Indexing Issue” button under the Index Coverage report and URL Inspection Tool articles in the Search Console Help Center.https://t.co/3sFqvCvhjohttps://t.co/I7k3BYAH0i pic.twitter.com/Wd9ooXqK0y
— Google Search Central (@googlesearchc) April 28, 2021
Users can access a form and select whether their site or pages are not indexed, or are indexed but aren’t ranking properly. They will then be guided through troubleshooting options related to the reported issue.
If these solutions fail, they can report the issue directly to Google.
However, this feature should be treated as a last resort, and it’s not guaranteed that Google will follow your request and index your content.
Google aims to only index the most relevant, high-quality content. Therefore, following best practices and optimizing your pages to make them crawlable, indexable, and worthy of Google’s attention can give your site long-lasting results.
ZipTie
ZipTie provides an assortment of extensive features for analyzing the indexing status of any website, regardless of its size. The tool is especially beneficial for large, enterprise-type websites.
Here is precisely what ZipTie offers:
Analyze Index Coverage
The core feature of ZipTie is that it tells you which pages didn’t get indexed by Google.
And, what’s critical, there is no limit on the number of URLs ZipTie can analyze. This is important for large websites with thousands or millions of URLs that can’t be successfully assessed using other tools.
Crucially, you can check Index Coverage of any domain – not only yours but also your competitor’s. Then, compare your indexing status to competing domains and see which areas you should improve to get ahead.
Monitor indexing delays
ZipTie lets you monitor indexing delays and estimate when your newly published content will get indexed and when you can expect it to drive traffic.
This is done by analyzing new URLs added to your sitemaps and investigating the time between publishing the content and the moment it appears in search results.
Alerts on deindexed content
ZipTie will update you on the amount of content that got deindexed. Pages that have already been indexed may be dropped out of Google’s index after some time – this feature lets you react quickly when it happens.
JavaScript indexing
Indexing JavaScript-based pages is tricky – but ZipTie offers a helping hand.
Specifically, ZipTie can determine whether Google indexed particular page fragments generated with JavaScript.
It’s vital to understand whether Google has problems rendering and indexing your JavaScript-based content. If this is the case, ZipTie can let you know exactly which page elements are problematic.
Additional information on unindexed pages
As a bonus, ZipTie offers additional information about unindexed URLs such as their word count, titles, headers, image count, meta description, and more. This is significant when investigating the possible causes of indexing problems and identifying patterns between unindexed pages.
You can export the data from ZipTie as a CSV file and easily combine it with data from other tools, like Google Analytics or Google Search Console.
ZipTie is not openly available as of yet. More details on it will be released as the tool’s development advances. You can stay up to date on the official launch by signing up to ZipTie’s mailing list.
But you don’t have to wait.
Get in touch with ZipTie’s team right now to conduct an in-depth analysis of your website’s indexing status.
Bing Webmaster Tools
Even if appearing in Bing is not your priority, Bing Webmaster Tools can help you gain insight into all types of indexing issues, some of which you may be facing in other search engines too.
Site Explorer
First of all, let’s look at Site Explorer.
The Site Explorer tool allows you to navigate through your website’s structure and details on the pages’ indexing status, among other data:
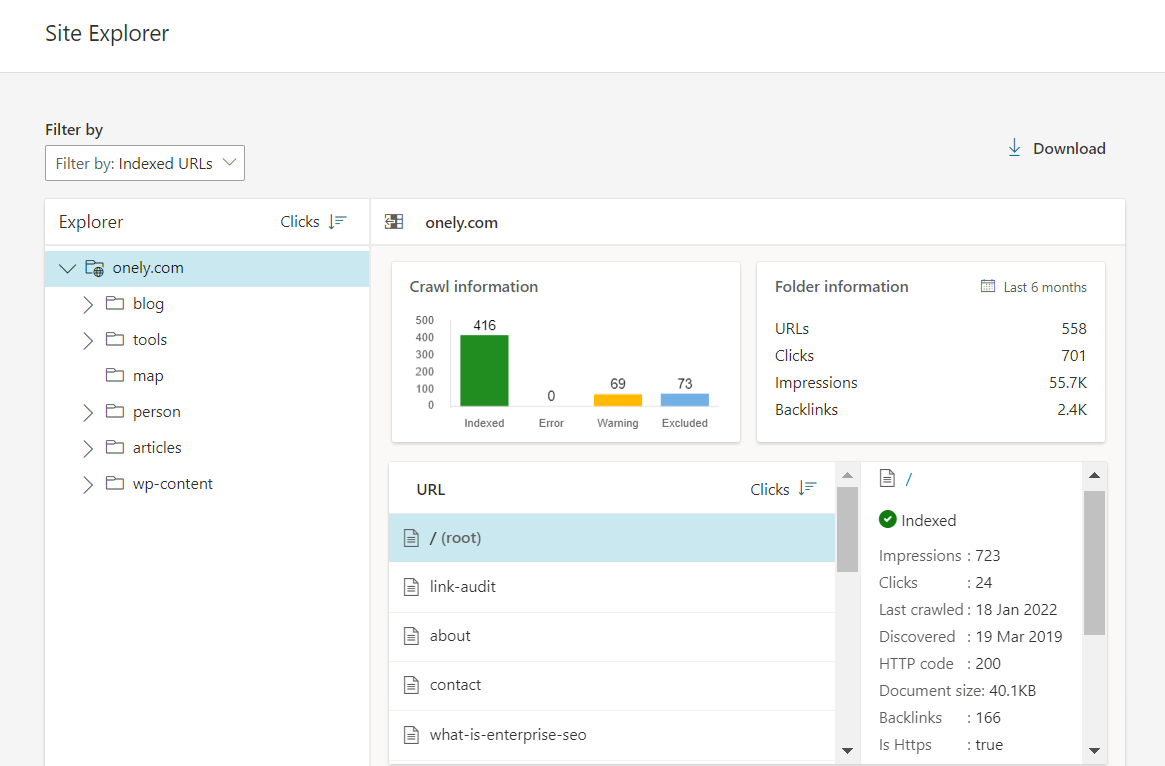
One aspect that makes Site Explorer stand out is the option to group URLs per folder, where each folder can represent a subdomain or a part of the URL’s path. As a result, you have access to data for a significant number of pages.
The crawl information that you have access to includes:
- Indexed – the number of indexed URLs within a given folder,
- Error – Critical crawl errors that led to the specified URLs not being indexed,
- Warning – these URLs have been found to have guidelines issues, temporary crawl issues, disallowed in robots.txt, etc. Monitor this section regularly to spot any spikes or drops in affected URLs,
- Excluded – URLs that have been excluded from the index, e.g., due to spam violations or low rank.
You have the option to filter the URLs further to display pages based on specific features.
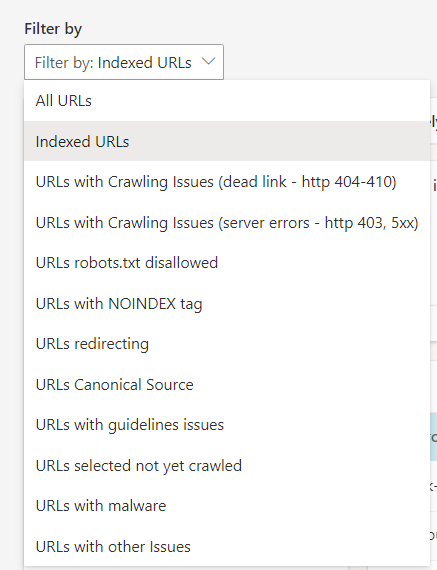
These filters let you identify URLs that require your attention and point you in the right direction when addressing indexing issues.
Bing’s URL Inspection tool
Another great feature is the Bing URL Inspection tool that complements the Site Explorer. It lets you review whether a specific URL is in Bing’s index and if any indexing or crawling errors were recognized.
Paste a URL into the tool – you will then see a lot of supplemental information.
In the Index Card section, you can see the indexing status of a URL and details on it, such as when the URL was discovered and how it was crawled.
You can also view the HTML code of the page and the HTTP response that the system received.
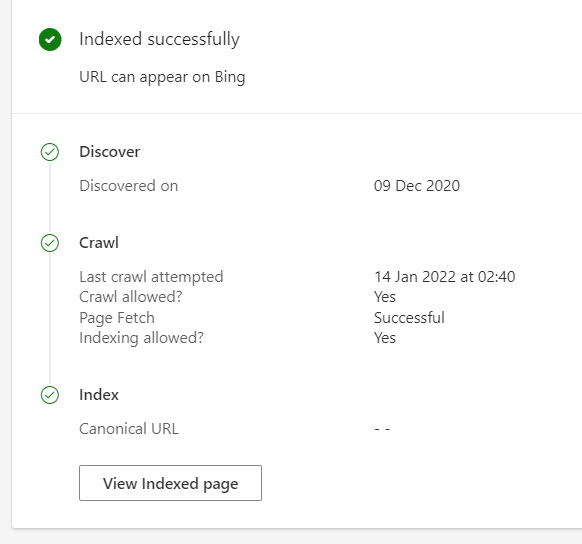
If the URL hasn’t been indexed due to errors, you will be able to take further action, such as request indexing of a URL, contact support, make adjustments to your robots.txt file, etc.
Bing provides guidance on why a page may not be indexed – here are some reasons:
- No links are pointing to your page,
- The page does not meet the quality thresholds,
- Robots.txt directives are blocking the crawling of the page,
- There are other crawling issues with the page – the Live URL feature will help you look into it further,
- The page has a noindex tag that prevents it from being indexed,
- The URL has not been discovered and crawled yet and simply needs more time,
- The page violates the quality guidelines and has been penalized and removed from the index.
You may further use this as a reference point when diagnosing indexing issues in other search engines, like Google.
If URLs are not indexed and should be, Bing allows you to submit URLs for indexing.
What’s important is the limit is relatively high – you can submit up to 10000 URLs per day. That far exceeds Google’s reported limit of up to 50 URLs.
Common indexing issues for large websites
Indexing issues occur on most sites, and they can have a disastrous effect on the organic search performance of your site.
Tomek Rudzki has looked into the most common indexing issues for different website sizes.
Through his research, we now know that large websites typically suffer from the following problems:
- Crawled – currently not indexed,
- Discovered – currently not indexed,
- Duplicate content,
- Soft 404,
- Crawl issues.
Another typical issue concerns internal linking. Googlebot needs to follow a path to find a page – if it’s not connected with other pages, it may be kept out of the index.
How to address indexing issues
You can take steps to maximize the chances of getting your pages indexed.
These solutions are also helpful when you find unindexed URLs and can’t identify why they aren’t indexed.
Make sure your pages are indexable
Finding out if your pages are indexable consists of looking into two aspects:
The directives specified in your robots.txt file
The robots.txt contains instructions for web crawlers on what should be crawled on a site. Ensure there is no “Disallow” directive preventing your valuable pages from being crawled.
Noindex tags allow search engine bots to visit the pages but prevent them from getting indexed.
To bulk check whether your pages are indexable, use an SEO crawler – for example, Screaming Frog.
Check out other popular SEO crawlers in this article.
You can paste a list of your URLs into the tool and start the crawl. When it’s done, look at the Indexability column, which will tell you whether a page is Indexable or Non-Indexable.
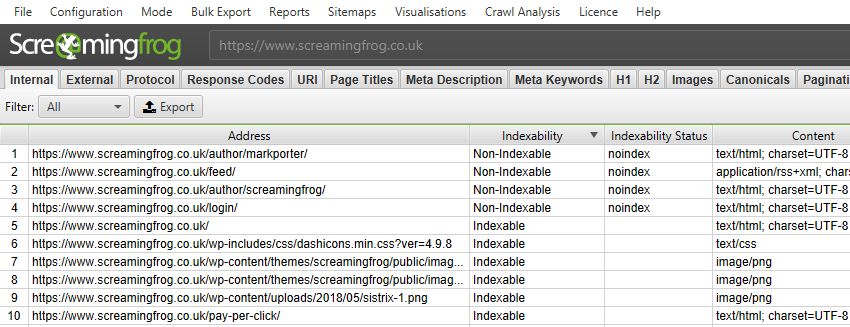
Ensure all valuable pages are submitted in a sitemap
Check whether the unindexed pages have been submitted in a sitemap – if not, add them accordingly.
Additionally, make sure your sitemaps don’t contain URLs that shouldn’t be indexed in the first place. Allowing search engines to discover and crawl irrelevant pages can lead to inefficient crawling and extend the time the bots require to find your highest-quality content.
If you don’t have a sitemap, you can easily create it or use dedicated tools that will keep it up-to-date, such as Yoast SEO or Screaming Frog’s SEO Spider. You can also use one of the sitemap generator tools.
Our ultimate guide to sitemaps will be your number one resource for creating an optimized sitemap.
Adjust your internal linking
Internal linking is a crucial aspect of your site from an SEO perspective.
Simply including a URL in a sitemap is not sufficient for Google. Googlebot needs to be sure that a URL is worth its attention – for this reason, it needs to find signals highlighting its importance.
Ensure you have no orphan pages, meaning pages without incoming links. You can crawl your website to find orphan pages – for example, do it by using Screaming Frog’s Orphaned pages report.
Some ideas for improving your internal linking include creating sections for related products or writing blog posts to link to other pages across your site.
You also need to have a clean website architecture. It means organizing the content on the site so users and bots can intuitively and quickly navigate to every section of your site.
Contact Onely if you see a need for more detailed internal linking optimization.
Fix duplicate content issues
When more than one version of the same or very similar content exists on your site, search engines may struggle to decide which page is the most representative version.
To make search engines’ job easier, implement canonical tags pointing to your selected canonical URLs. Each page version should have just one canonical URL.
Make sure the canonical tags consistently point to the right canonical pages. If they point to duplicate pages, the primary URL may remain unindexed.
Google Search Console notified you about indexing problems due to duplicate content? Read our guides and fix:
- the “Duplicate, Google chose different canonical than user” status,
- the “Duplicate without user-selected canonical” status.
Follow best practices of JavaScript SEO for easier crawling and indexing
Although search engines have gotten much better at rendering and indexing JavaScript, their handling of it is still not perfect.
Generally, search engines may not render JavaScript on a page if they think it won’t make any significant changes to its content. Also, if your pages look completely different with and without JavaScript, you may struggle to get them indexed.
There are tools you can use to analyze your JavaScript indexing.
You can easily check which parts of your page rely on JavaScript using our What Would JavaScript Do tool.
Use the Live Test in Google’s URL Inspection tool to see a screenshot of how exactly Googlebot would render the JavaScript content on your page. You can then go to the More info tab to look for JavaScript errors.
The View crawled page option in the URL Inspection tool will tell you what Google crawled on your page and whether all the JavaScript content is there.
In case of issues with JavaScript indexing, refer to our article on JavaScript SEO for further guidance or contact us to get a JavaScript SEO audit.
Optimize your crawl budget
The crawl budget is the number of pages on a website that search engines can and want to crawl.
Your site’s crawl budget can be affected by numerous factors.
Follow these general guidelines for crawl budget optimization:
- Improve your web performance,
- Optimize the JavaScript and CSS files on your site,
- Beware of internal redirects and redirect chains to avoid the “Redirect error” issues,
- Adjust your site architecture,
- Clean up your internal linking – update any links pointing to “Not found (404)” pages and frequently link to your most important content,
- Have a properly structured sitemap – you can analyze your sitemap’s structure using one of the SEO crawlers, like Ryte or Sitebulb.
Here’s what you can do now: Still unsure of dropping us a line? Read how technical SEO services can help you improve your website.NEXT STEPS
Takeaways
Large websites may struggle to get many of their pages indexed. But it doesn’t mean that indexing all of your valuable content is impossible.
Analyzing the indexing of a large website may require some work. Still, features available in Google Search Console and Bing Webmaster Tools will give you actionable insights that you can instantly start acting on.
I think you can expect that ZipTie will be a game-changer in the field of indexing – I encourage you to get in touch with ZipTie’s team for an indexing analysis.
And, if you are dealing with large-scale indexing problems that you’re struggling to address, contact us for a full technical SEO audit.

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!