
What interests us the most when we put our site on the internet? How users will find it. We want it to be visible, but it is not our decision to make.
GoogleBot “makes this decision” (we are talking about the Google search engine in this article). It crawls Internet resources and assesses your site constantly. GoogleBot checks if the domain is valuable and if it is the best fit for user queries. The bad news is that a wrong website configuration can work against you. You can even make your domain invisible for GoogleBot. The good news is that you can optimize your website in order for GoogleBot to ‘like’ it – if you are aware of its limited budget per domain.
The conclusion is simple – you would like to know on what basis Googlebot assesses your site (which resources it crawls). This information is closer than you would think. It is already in your server logs.
What is the GoogleBot budget and why is it limited?
The GoogleBot budget is the number of crawled pages per unit of time for a particular domain (you can check your GoogleBot budget in Google Webmaster Tools).
It has to be limited because GoogleBot can’t crawl all internet resources all the time (there is simply too much data). It picks up the most relevant and valuable resources and crawls them the most frequently. If it crawls low-quality pages on your domain, your budget shrinks and this can negatively impact its visibility.
The goal of this article
Until recently, server logs were underestimated in the world of SEO. Since most of us are not that technical, it was hard to see its true value, and we would usually draw conclusions from beautiful tables and charts. However, real beauty is sometimes hidden…

The number of specialists who have taken up the challenge to make their SEO efforts even more technical remains low. The very first few times I opened server logs, I wanted to run (hope my boss doesn’t mind). Now, I can’t imagine my work without them. My goal is to show you the benefits of server log analysis. So read carefully if you have trouble with Google Panda or want to protect your website from its negative impact.
If you are not interested in technical issues, please jump to the “User cases” section.
What is a server log and why is it so important?
A server log is like an extremely detailed diary. The server keeps a record of every single request for a particular resource (image, HTML, script, etc.) within your website. From the server side, it doesn’t matter if this request is made by a bot or a user. It puts all those hits into a predefined file which you can download.
OK, I promised that we would search for this beauty. Let’s break down a sample request (Combined Log Format).

Server hits are collected, but usually, they are not analyzed or filtered by any algorithms before you get them. At least not for SEO purposes. If you manage to analyze them wisely, you will have a clear picture of any chosen user-agent (including GoogleBot) preferences when crawling your website.
Crawling vs. Google Panda
Do you need to recover from a penalty? Well, SEOs are a huge help when a website is trying to recover from the Panda algorithm. They know which pages should be crawled frequently and which should not. But in reality, what is actually crawled by GoogleBot? What percent of its budget is allocated in the main categories vs. sub-pages or other areas of the website? The easiest way to find out is server logs.
This is the real beauty of raw data.
Server log analysis – what can go wrong?
I would like to make you aware of some obstacles on the road to reliable conclusions from server log analysis.
Uploading logs – The log files are huge. I have worked with logs from big, eCommerce companies and it really wasn’t easy to figure out how I could handle those files with a “normal” desktop computer within a reasonable amount of time.

SaaS (online software) is expensive. Actually, the bigger the files, the more expensive it is.
Someone would say that there is a good open-source software! I haven’t found one for Windows despite investing a lot of time searching. If you have some recommendations, please share them in the comments below because I am always looking to peers for new techniques and strategies. After all, we are all on the same page, right?
Parsing logs – you can get different kinds of access logs as they can be customized. I believe that the most popular one is the Apache Common Log Format (as the name says).
Example from http://httpd.apache.org/:
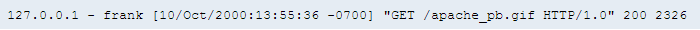
But, if you want to provide server log analysis to your customers, you should learn how to find useful information in other kinds of server logs, too.

Exporting the data – let’s assume that you have managed to filter the data, and now you would like to export them and create some nice tables. Hmm, I would do that with Excel. The problem is that it can only open 1,048,576 rows of data. This number is lower when filtering and creating pivot tables.
No, I’m not crazy – this is a small number if you are working on the full set of logs from ex. one month.
Let’s do it right!
Software
I have chosen Splunk to show you some examples. Why? Because I haven’t found anything better yet. This tool is really pricey, but it has been created for much more than server log analysis.
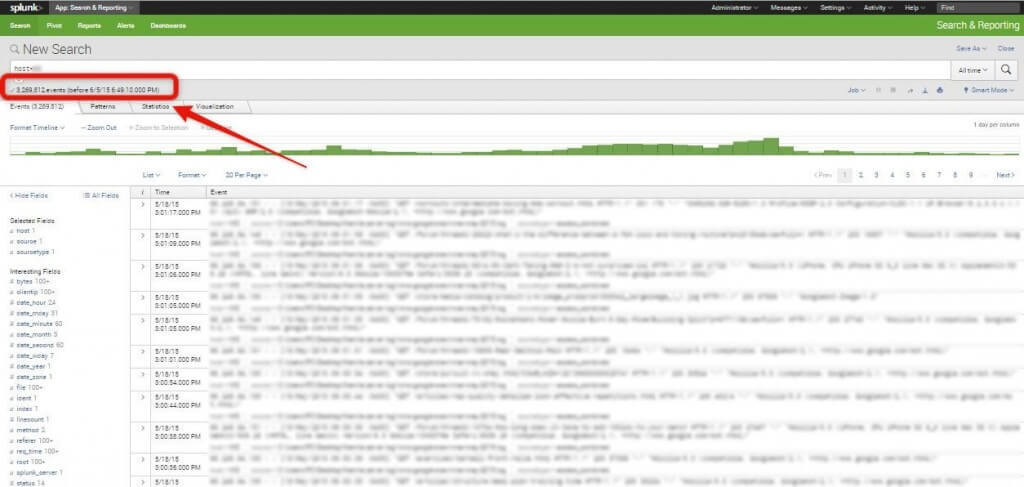
Notice that there are more than 3 million events indexed.

You can set up Splunk on your machine or on a dedicated server – ex. for company use. Splunk, even when installed locally, is very well optimized to handle large amounts of data.
I also think Gamut LogViewer is worth mentioning.
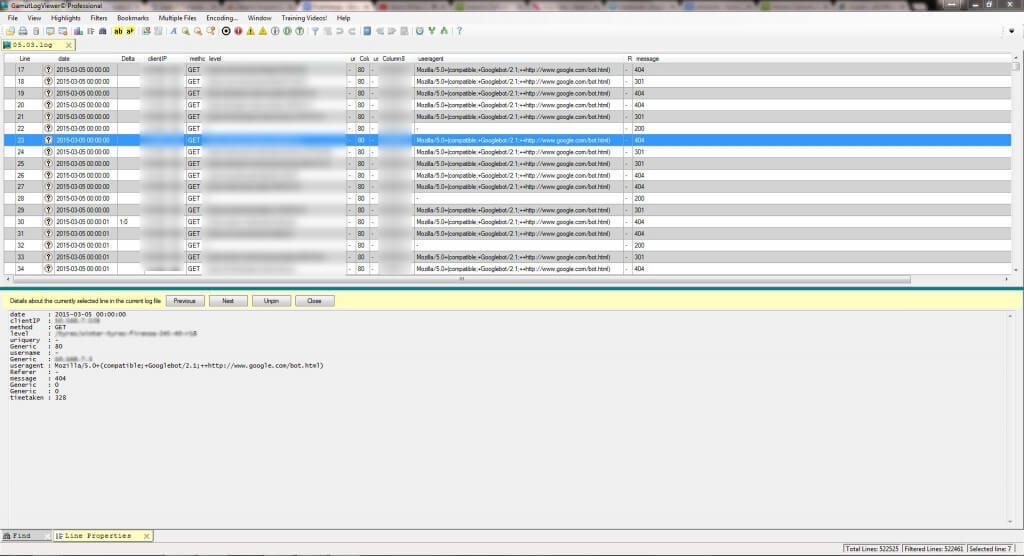
It has nice filtering options but unfortunately provided a bad user experience, even when I tried to process about 500KB of data. It takes a lot of resources and doesn’t show any process status bar when calculating – you can only see that it is unresponsive, so you never know if and when a particular process will end or if the process is frozen.
Furthermore, parsing logs needs a lot of accuracy and time spent on deciphering log formats.
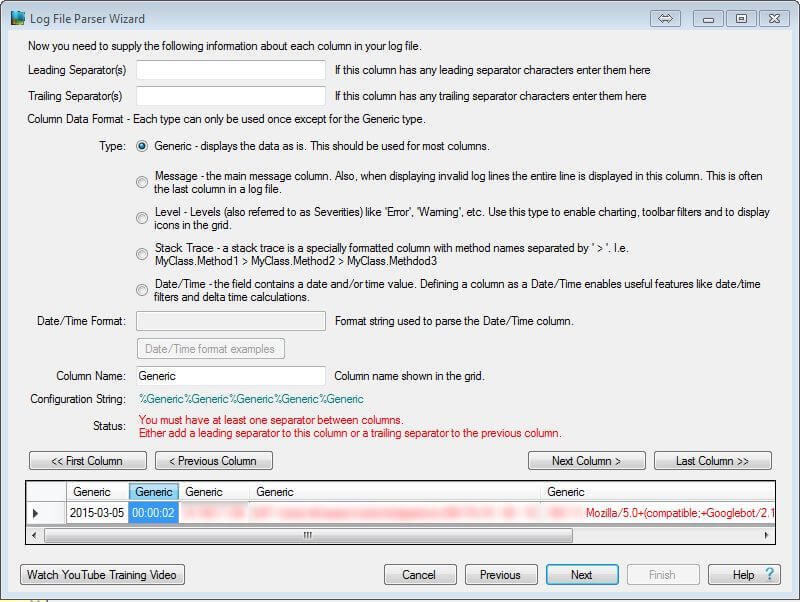
You can, of course, export filtered data to Excel, where further analysis can be done(e,g., in pivot tables and charts).
Gamut is the right choice if the site does not have much traffic or if you would like to limit your analysis to one day logs.
Uploading and parsing server logs with Splunk
It is definitely not rocket science. You don’t have to know what the exact format of logs you receive is. It is important to know where the information is and which information is the most valuable for you.
I use two options for adding the data: Uploading and Monitoring.
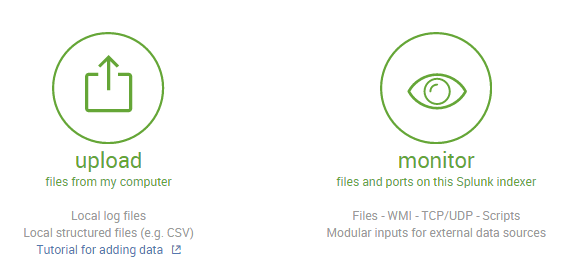
When uploading, you have more control over the data. You can preview, set the timestamp, event breaks, and so on. However, you are limited to a 500MB size for each uploaded file, so uploading server logs from periods of, e.g., one month, can be a long process (you have to split it, ex. 30MB file into 60 smaller pieces…).
Here comes the “monitor” option, which is very powerful when it comes to handling bulk data. You can indicate the directory with server log files – Splunk will find and index all of them without your assistance.
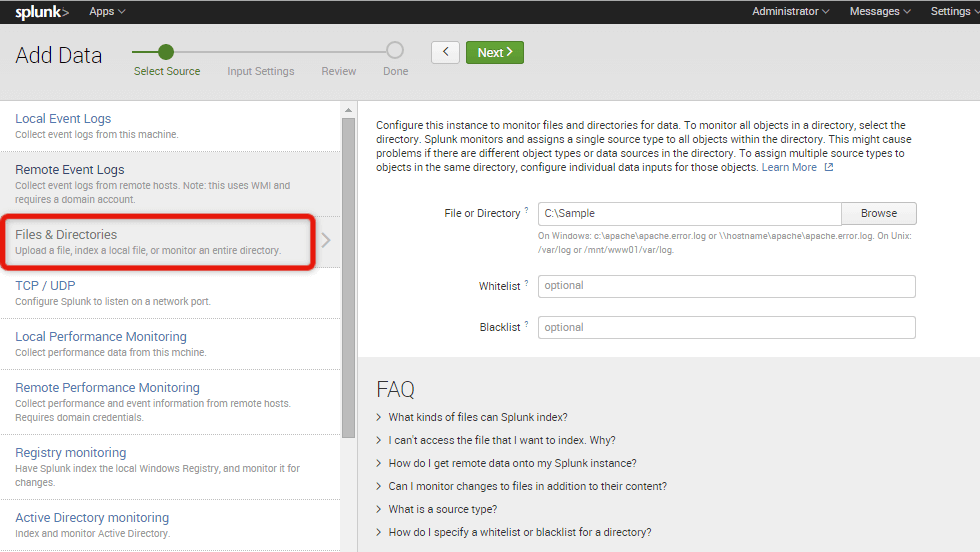
When your logs are uploaded, you have to check if the tool parsed them correctly. It does really well with Apache access logs setting, the sourcetype to acces_common, or access_combined. Splunk doesn’t always know how to parse the server log correctly. In this case, you can set the sourcetype by yourself, or extract the necessary fields.
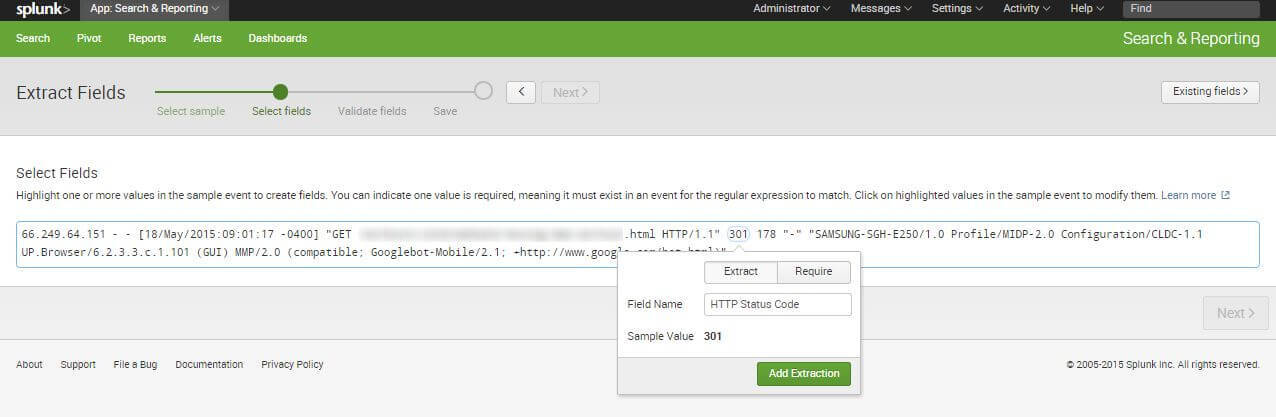
Extracting fields can be done by just marking a string (as opposed to Gamut LogViewer). When you do that, a small window shows up where you can enter the name of the field. In most cases, you only need to mark a particular field in two logs. It is enough for Splunk to create a regular expression which is applicable to all the logs in a chosen Sourcetype. You can also create the reg by yourself, for example.
The most important fields to make brilliant log analysis:
- Client IP
- URI
- Server Response
- Referer
- User Agent
- Time taken (if it is available)
- Correctly set Timestamp
NEXT STEPS
Here’s what you can do now:
- Contact us.
- Receive a personalized plan from us to deal with your indexing issues.
- Enjoy your content in Google’s index!
Still unsure of dropping us a line? Read how technical SEO services can help you improve your website.
How to find the REAL Google Bot?

In a few articles on server log analysis, I found this advice: look for the Googlebot in User Agent. But should we trust the User Agent? Not really. It is helpful – yes, actually, everyone can crawl your site as Googlebot (you can set the user agent to GoogleBot even in ScreamingFrog or Deepcrawl). As you probably guessed – it can strongly influence your analysis and result in drawing false conclusions about Panda. What is more, you can miss AdsBot this way.
Example of the fake Googlebot:
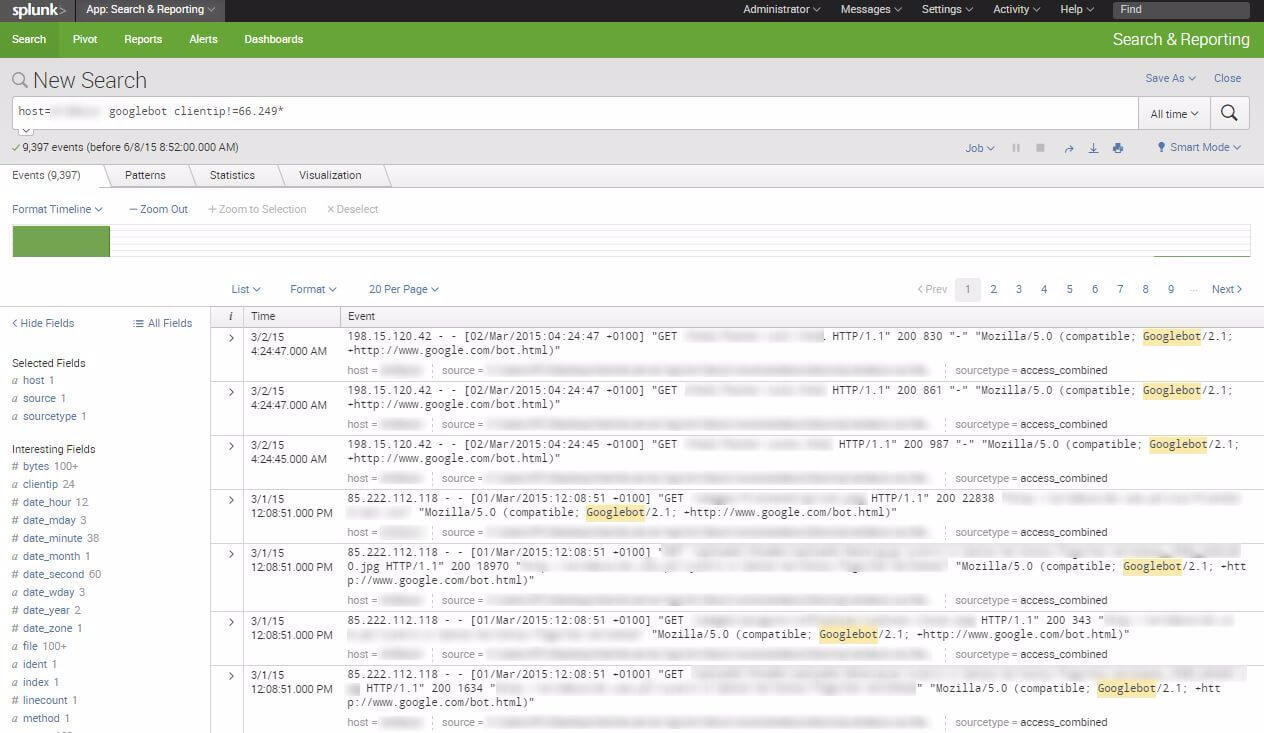
There is one thing that is much harder to fake – an IP.
Googlebot IP pattern is 66.249.***.***. You can verify it by searching for “Google” in User Agent, seeing which IP is popular in the search results, and checking its owner by whoisIP.
How to pick the right range of data?
It depends on what you are searching for.
I like to work on a month’s server logs. It is much easier to detect some patterns with a good-sized period of time and with only around 1 – 3 weeks’ worth of data, we may exclude the possibility of intensive crawling due to daily swings (e.g., GoogleBot will often follow links and crawl the target pages). The full range gives the opportunity to show the client the exact number of server hits with particular parameters of the given time period.

Use cases
If you are not trying to analyze logs by yourself, this part is the most important for you.
How can server logs improve your business? How can they help you understand why you got hit by Panda? How do you use server log to improve SEO performance?
Here is a list of findings available through them:
- Optimizing GoogleBot crawler budget.
- Investigating the loss of rankings due to the index bloats.
- Monitoring errors that waste GoogleBot budget and provide a bad user experience.
- Monitoring potential negative SEO attacks.
- Finding the most and the least valuable for the GoogleBot directories of your site.
This post will focus on the very first point of the list above, as I believe it gives the most surprising and useful results for SEOs.
You CAN optimize the GoogleBot crawl budget, so you SHOULD take advantage of it.
As some of us know, the GoogleBot crawl budget is limited. When it crawls low-quality pages on your website (there could be many reasons for that), the number of crawls per valuable page can decrease. GoogleBot assesses your site on the basis of what it crawls. The conclusion is simple – a badly allocated GoogleBot budget can lead to visibility loss due to the Panda algorithm.
We cannot afford to let this happen.
One more important issue – GoogleBot indexes what it crawls. If it crawls low-quality pages (404 errors, duplicated URLs, sorting that doesn’t add a new value, etc.) and they are indexable – it will index them. Do you want the users to go there instead of your main landing pages?
I thought so.
By finding Googlebot hits in your logs and creating some simple pivot tables, you can find the answers to the following questions:
- Which URLs does it visit the most frequently?
- Which URLs does it not visit at all?
- On which URLs it encounters errors?
- Are URLs from the Sitemap crawled?
- What are the categories of URLs which consume the greatest amount of budget?
Here is the example of a search query that creates a table with the sum of Googlebot hits per URL:
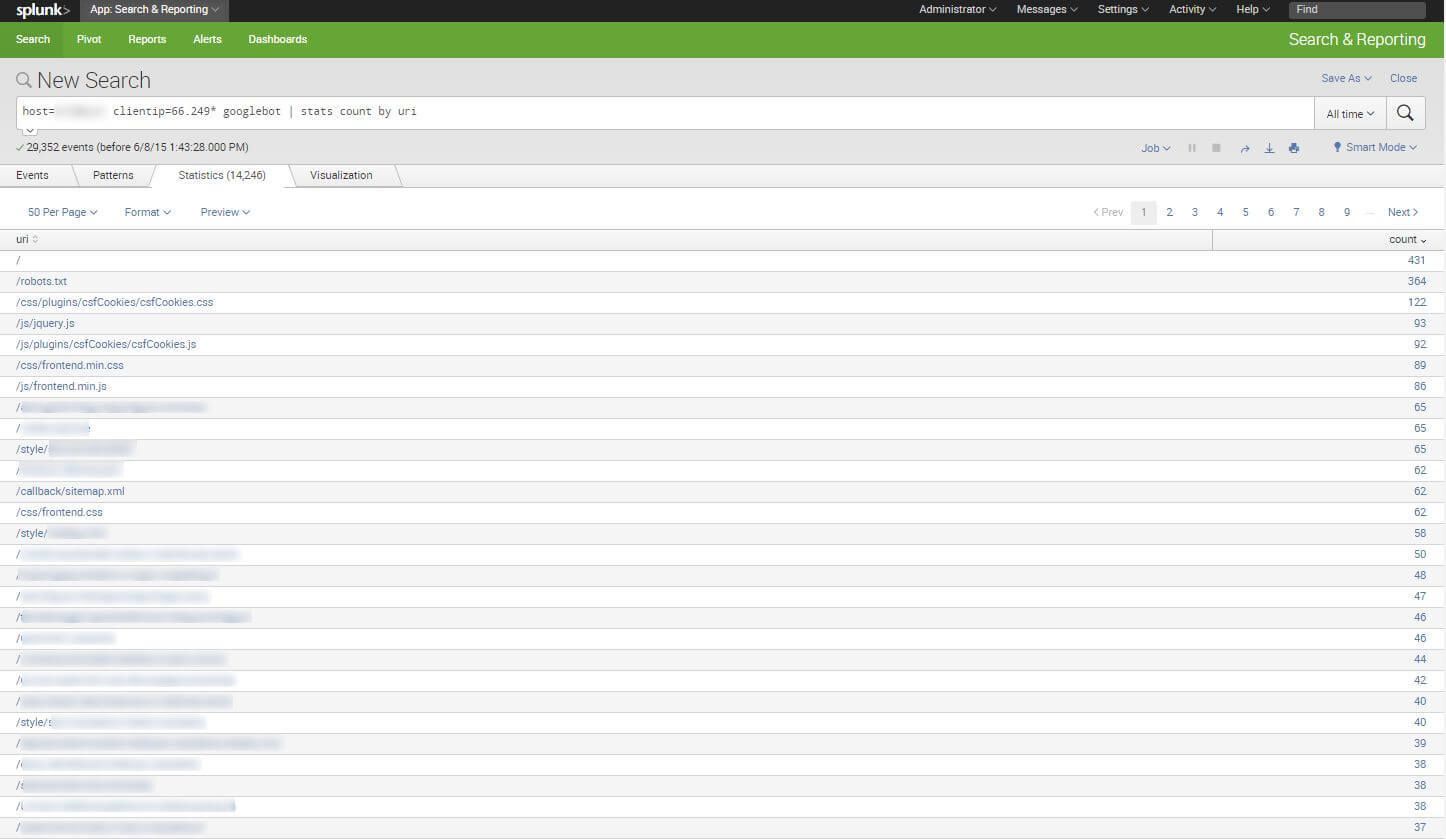
You can also use the built-in Pivot table feature:
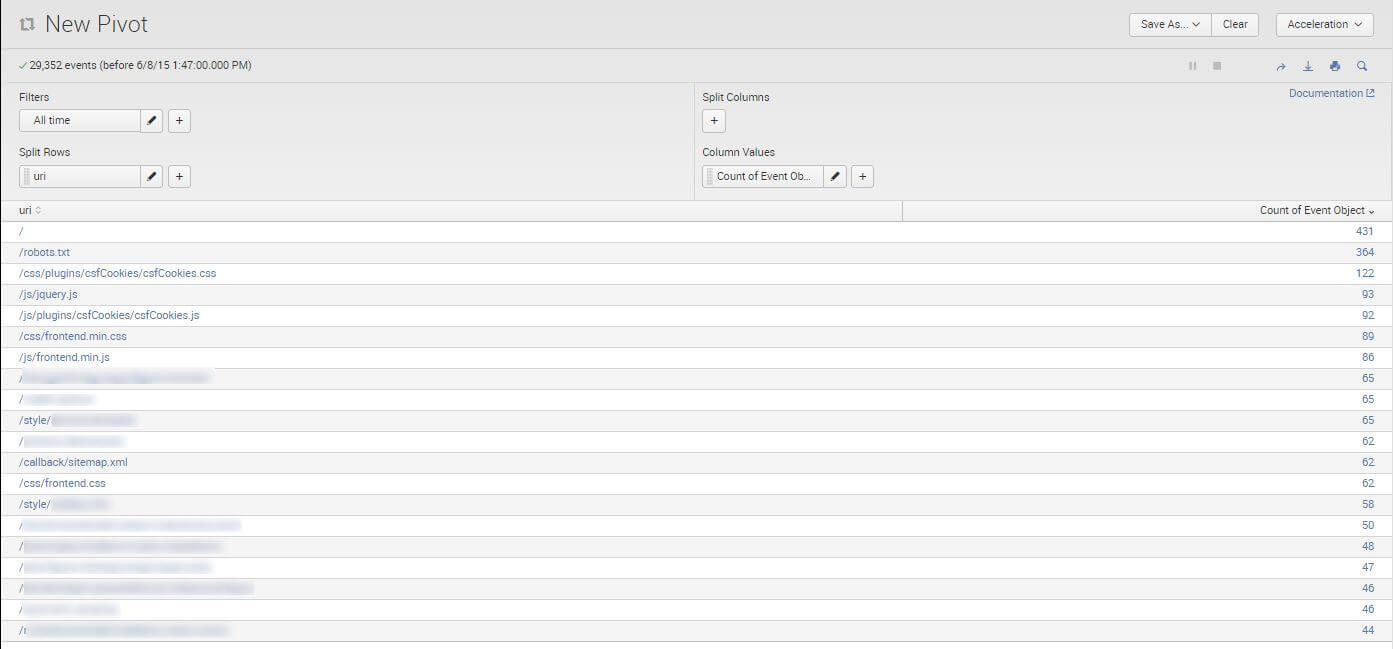
It is very convenient – you don’t have to export the data. The whole analysis can be done in Splunk.
Having such a table, you can look through the most crawled URLs and answer the question: Is it the most valuable content on my site? If it is – you are lucky, but in the most problematic cases, Googlebot gets fed up with low-quality content.
Using one of our clients who is an industry leader in the United States:
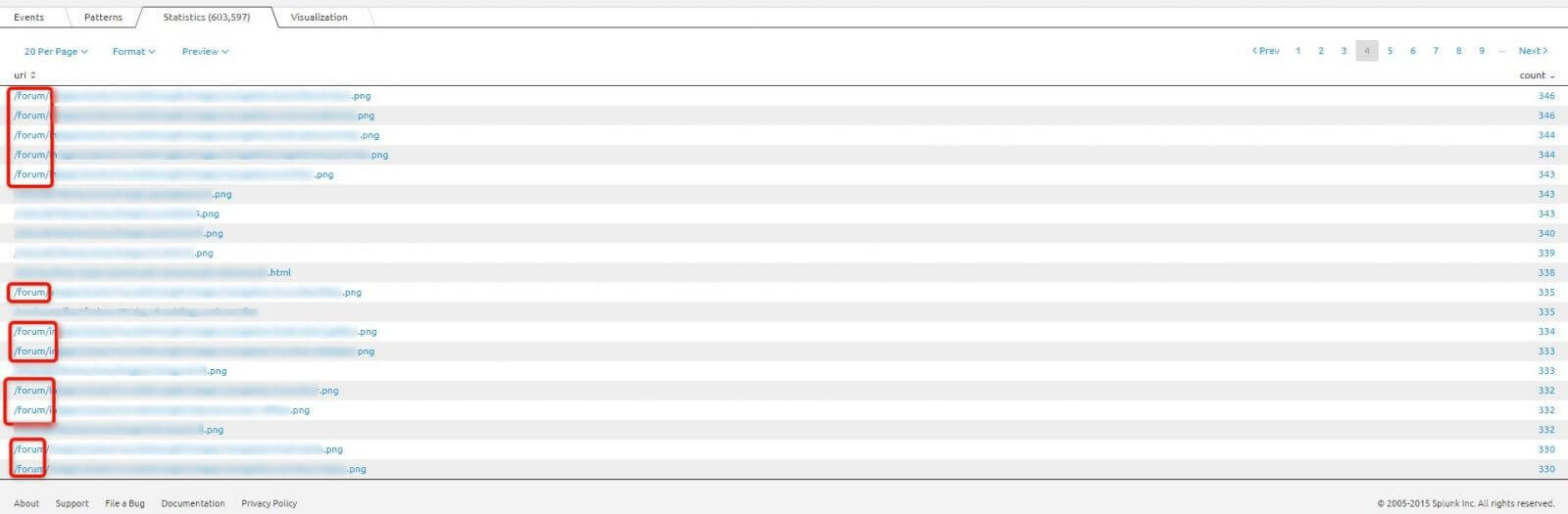
Googlebot willingly crawls forum. However, my question is: Where are our landing pages?
OK, let’s see what the size of this problem is. We can do this by summarizing hits by root – top category URL.
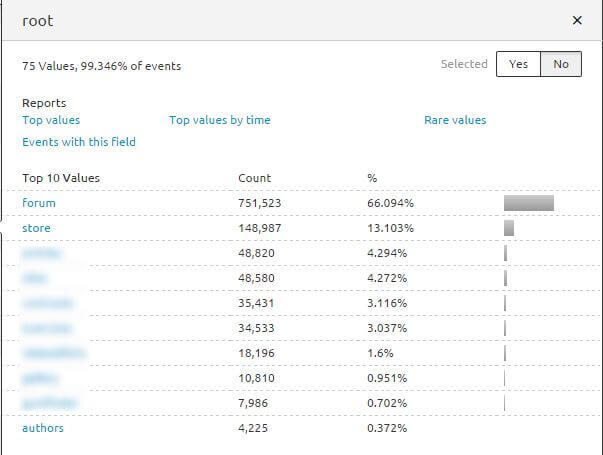
It does not look good. Over 66% of the Googlebot budget is allocated to the forum. This website contains thousands of articles, tutorials, and its own store. The forum only extends the functionality of the site, and it shouldn’t consume such a large amount of the GoogleBot budget. My team solved it by blocking most of the forum directories in the robots.txt file. This should result in GoogleBot not being pulled away from valuable content.
To see which URLs are not crawled, you will need the list of all your URLs and compare them with those crawled by Googlebot. You can do this using vlookup function in Excel. The same is true for the Sitemap – you can assess if it is useful for Googlebot. In our clients’ Sitemap, no links to forum were included. There were a lot of links to the Store directory instead. Why does the Googlebot prefer the forum and avoid the store?
Here is the answer:
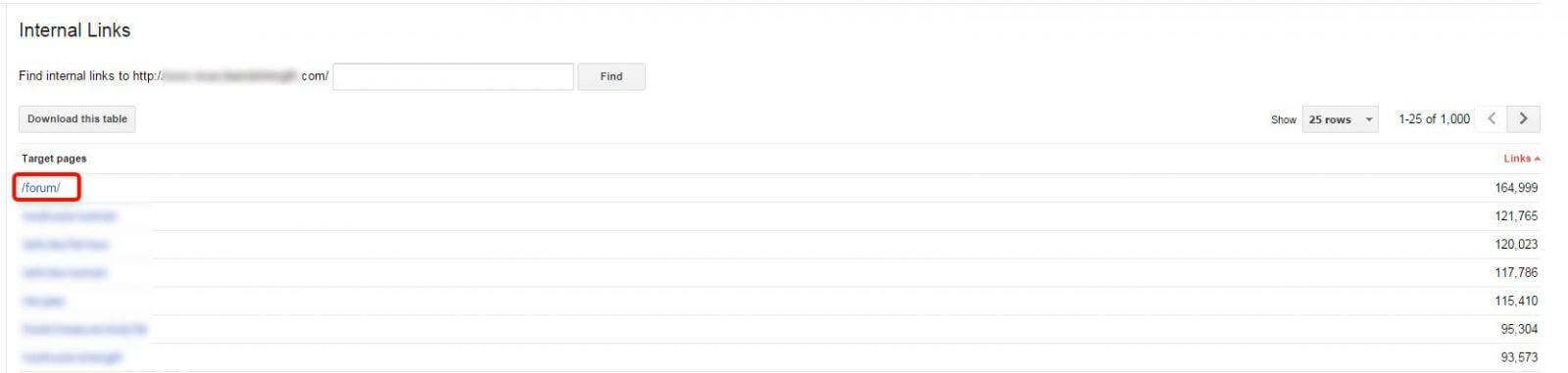
Remember – Googlebot is a crawler. It moves through links. The more internal connection a page has, the greater probability it would be crawled frequently.
After blocking forum URLs in the robots.txt file, the number of indexed pages for this client dropped significantly.
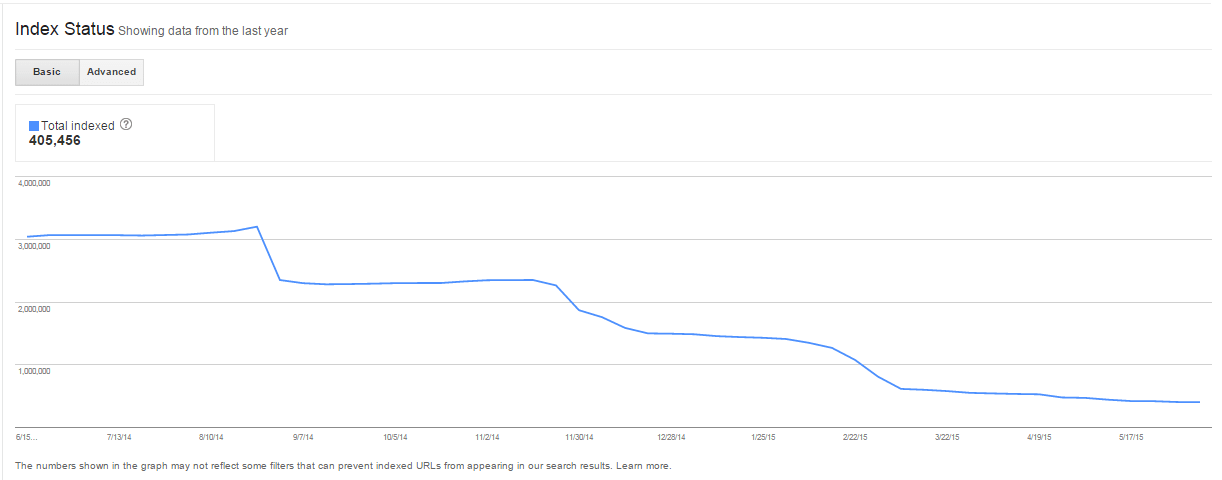
This is proof that GoogleBot respects directives from the robots.txt file. Only valuable and unique pages should be indexed – such a clean profile of URLs in search results gives you a greater chance for high visibility.
This is a big French website – www.pimido.com (recently re-branded from dacodoc.fr). The purpose of its existence is to enable users to buy and sell articles, publications, etc. It suffered from major Panda issues.
Here, you can read the deeper analysis of dacodoc.fr case, published on Deepcrawl.com.
One of our findings was that search queries made by users were indexed in Google.
For example:
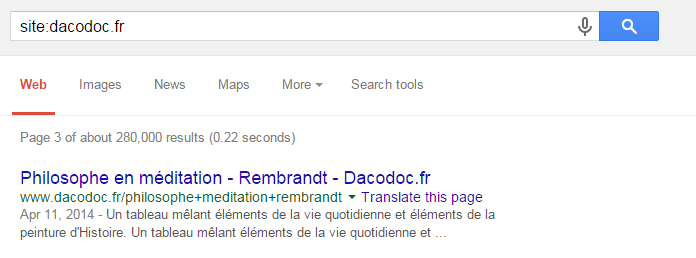
It caused a big issue with thin content, so we obviously decided to de-index the search results. We prepared brand-new and strong category pages, which were supposed to be new landing pages of our clients’ websites.
However, during log analysis, we found out that over 32% of the Googlebot budget was consumed by search queries, while categories could be found in only 2% of Googlebot logs. It is logical – category pages didn’t include valuable content, but internal search queries perfectly represented users’ needs. This way, we came to the conclusion that de-indexing part of the site, which had such a huge traffic would kill our clients’ visibility. Category pages were too weak to substitute for search queries right away, so we changed our approach – we rebuilt navigation and created more landing pages, so when we start to de-index and redirect those queries, GoogleBot will have quality content to index and process.
In this particular case, the log analysis resulted in a much smarter decision – to de-index search queries gradually, while new category landing pages would grow and slowly take over the traffic.
Key points
Through reliable log analysis you can:
- Protect your site from the negative impact of the Panda algorithm
- Remove the probable cause of being hit by Panda
- Improve the visibility of a website that is already ranking high
- Control what is indexed in the search engine (what the user sees)
- Find some hidden user-experience issues
Summary
I work with server logs nearly every day, and I am constantly surprised at my findings. I think it would be impossible to figure out some of the issues without server logs. It is crucial to get to know the client and his business. However, as a business owner, you shouldn’t focus on your own opinion. You should consider the value your site provides for user experience and flow – in other words, for the Googlebot budget. Server log analysis requires a bigger perspective than just the numbers. It is an investigation connected with a manual review of the sites’ structure, and it improves a lot of on-page decisions.
If this post was helpful – please, like it or share it! I will definitely appreciate it and prepare new stories on how server log analysis give our clients an edge over the competition.
If you would like to know more about server log analysis and how it can protect your site against future Panda attacks – contact us.

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!







