
Canonical tags let you specify which among multiple duplicate pages is the primary, preferred version of a page.
Any website can suffer from duplicate content issues – and you might not be aware that some of your content is viewed as duplicate.
Without the canonical tag, you are at the mercy of search engines – they will select the canonical version themselves. And, they may very well choose one that you don’t view as representative of the given content. This can severely impact your search visibility and rankings.
This guide explains the characteristics and SEO-friendly practices for using canonical tags to address duplicate content issues on your website.
What is a canonical tag?
A canonical tag is a snippet of code that is used to tell search engines that a particular URL should be treated as the main (canonical) version of a page.
Canonical tags are a crucial element an SEO strategy – it help manage duplicate content, avoid keyword cannibalization, and, as a consequence, have a higher position in Google.
Canonical tags can be implemented both in HTML code, as well as within the HTTP Headers.
According to the Google documentation on canonical, there are also other canonical signals, such as redirects or sitemap inclusion. They all ads up to let Google decide which page should be treated as a canonical version.
The most common technique to implement canonical tags is to add the following snippet of code to the HTML of a page:
<link rel=“canonical” href=“https://example.com/sample-page/” />
The code signifies that the canonical page is located at the specified URL.
Canonical tags are used to address duplicate content issues – but what content do search engines consider duplicate, and how do they treat it?
Search engines and duplicate content
Issues with duplicate content arise from the simple fact that search engine crawlers look at pages differently than users.
For a search engine crawler, each of the following URLs is different:
- http://site.com
- https://site.com
- https://site.com/index.php
- http://site.com/index.php
- http://www.site.com
While a user pays attention to the content on a page, crawlers perceive each URL address as a separate entity, even when multiple pages have identical content.
Duplicate content issues tend to be particularly severe for eCommerce sites but are not limited to them. Many modern websites automatically add tags and parameters to URLs, e.g., for sorting or filtering pages, and they often utilize numerous paths leading to the same content.
Multiple versions of your URLs can also exist if you use different URL structures – e.g., your URLs come both as www and non-www, with and without trailing slashes, with HTTP and HTTPS protocols, and in any other formats.
This can lead to duplicate content, which search engines are reluctant to index.
Specifically, when search engines come across duplicate content, they struggle to decide:
- Which page should be indexed,
- Which page should rank for relevant keywords, and
- Whether they should consolidate ranking signals under one URL or split it between multiple pages.
Though search engines can deduplicate pages for ranking purposes, it’s risky to let them choose the canonical URL – they may select a page that is not the most representative version of your content.
How does Google choose canonical pages?
It’s important to note that Googlebot will not always follow your canonical tags, as they only serve as suggestions for how a given URL should be treated.
Google looks at many other on-page factors when choosing the canonical version.
These factors include, among others:
- Redirects,
- Internal and external linking,
- Sitemaps,
- Clean URL structure,
- The use of the HTTPS protocol.
You can check whether Google respected your canonical tag or selected a different one using the URL Inspection tool.
Watch this video that explains how Google chooses canonical URLs.
A proper strategy for using canonical tags is essential for your website’s success on Google, which is why it’s an integral part of Onely’s technical SEO services.
Don’t forget that simply adding canonical tags won’t fix all problems with duplicate or thin content.
Your main objective should be to eliminate the core problems that cause these issues. Focus on analyzing whether you can remove or improve the content on duplicate pages to make it more unique and perhaps provide more value to the user.
Nonetheless, accurately marking up your pages with canonical tags is a step forward in dealing with duplicate content.
Let’s analyze how you can benefit from canonical tags and when to use them.
By adding canonical tags, you can:
Specify which page should appear in search results
Search engines aim to provide the best user experience – that’s why they will rarely show more than one version of the same content in search results.
Canonical tags give you a chance to enhance the search visibility of the most representative page version which can increase organic traffic to this page and translate into business benefits.
Consolidate ranking signals for duplicate pages
Other sites may link to different duplicate versions of your pages, diluting the signals that search engines consider during ranking.
When you use a canonical tag, you tell search engines that the ranking signals from duplicate URLs should flow to the canonical page.
Discourage crawling of duplicate pages
If you implement canonical tags, it’s less likely that search engines will keep crawling the canonicalized pages knowing they are copies.
At the same time, the canonical version should be crawled more regularly.
This is an opportunity for your canonical pages to be crawled more efficiently which can positively affect your website’s indexing status.
Let’s go through the specific content for which you should select a canonical page.
The following content types and aspects typically add no value to your website and can result in increased amounts of duplicate content.
Syndicated content
Content syndication means that a piece of content was republished on another domain.
Implementing a canonical tag can help attribute the ownership of the piece to the original publisher.
Product filtering and sorting
Filtering and sorting options, typical for eCommerce sites, usually utilize query strings that are added to URLs – this can create massive amounts of duplicate content. Canonicalizing filtering and sorting pages will help your canonical version rank higher and prevent search engines from unnecessarily crawling duplicate content,
Redundant parameters in URLs
Parameters can be redundant for a page if they are not used for tracking, don’t change the content, and add no meaningful information to the URL.
Instead, they can lead to inefficient crawling of your site.
Product variants
A product may come in different variants, where the only characteristic that changes is its color, size, or any other applicable attribute. Canonicalization can help you select the main product variant.
However, consider whether the product remains the same. For example, in the tech niche, different variants of products, like smartphones, may actually contain other functionalities and thus should all appear in search results.
Tracking parameters and session IDs
Tracking parameters can track a campaign or user journey, and they don’t change a page’s content, so should also be canonicalized.
You may be wondering how canonical tags compare to other solutions that may affect how search engines index pages and whether they index them at all.
Let’s compare the characteristics and SEO use cases of canonical tags, noindex tags, and 301 redirects.
Noindex tags are used to exclude pages from the index, not to manage which page should be chosen as canonical.
You should never use the noindex tag to prevent search engines from selecting a canonical page.
Canonicalized pages generally consolidate ranking signals under one URL, unlike noindex tags – this is caused by Google treating long-term noindex, follow tags as noindex, nofollow.
The rule of thumb is that a page shouldn’t be both noindexed and canonicalized. For instance, pages canonicalized to noindexed URLs will be dropped from the index.
John Mueller clarified during SEO Office Hours that there is no risk of a noindexed and canonicalized page transferring the noindex onto its canonical destination, which would subsequently remove both addresses from the index.
However, using both noindex and canonical tags sends mixed signals to Google. This means that Google can interpret the tags however it chooses, and the outcome might be undesired to you.
Is your page “Excluded by noindex tag” in Google Search Console?
Read our article to ensure you added the noindex tag on purpose.
Search engines and users perceive canonical tags and 301 redirects very differently.
If you use a 301 redirect, users will be automatically taken to the destination page and won’t see the original page. 301 redirects also help you save your crawl budget because they limit the number of URLs that need to be crawled.
Meanwhile, with a canonical tag, users will still be able to visit both URLs. Moreover, the duplicate URLs still get crawled by search engines, so the number of crawlable pages doesn’t decrease.
Though canonical tags tend to pass ranking signals to the primary version of a page, 301 redirects are a stronger indication for Google that ranking signals should be transferred to the destination URL. This happens because Google sees no intermittent content, as it does with canonical tags.
Let’s clarify when a 301 redirect will be more suitable than a canonical tag.
It’s best to use 301 redirects to consolidate URLs:
- Containing lower- and uppercase letters,
- With and without trailing slashes,
- HTTP or HTTPS protocols,
- Existing both with and without www.
If you are making changes to your content – such as during website migration – and your URLs change, you should 301 redirect legacy URLs to the new ones. Apart from redirecting, ensure the new destination URL has a self-referential canonical tag.
Another situation where 301 redirects will be optimal is when products are accessible under many URLs.
In this case, change your URL structure, so it doesn’t include the name of the category the products were assigned to. Then, 301 redirect the legacy URL. If any categories are redundant, you can remove and redirect them to relevant alternative pages.
Overall, use a 301 redirect if only one URL should still be accessible to users.
Looking for some more specific answers to redirect dilemmas? Check our articles on JavaScript redirects and fixing the “Redirect error” issues in Google Search Console.
There are two main methods of specifying canonical pages – in a page’s HTML or HTTP headers. You can implement them manually or use one of the tools that can help you automate it.
For example, you can go for an SEO plugin if you are using a CMS. Plugins with the functionality to specify canonical pages include Yoast SEO or All in One SEO.
If you are using Shopify, you can set custom canonical URLs if needed – Shopify’s default setting is to add self-referencing canonical URLs for products and blog posts.
No matter which method you choose, don’t forget to only implement canonical tags in one place – don’t use these methods simultaneously. If Google discovers multiple declarations of the canonical tag, it will likely ignore all of them.
HTML tag
Adding a canonical tag in your HTML is the most common way to implement it.
Add the following code to a duplicate page’s <head> section of the HTML and paste the URL of the canonical version:
<link rel="canonical" href="https://example.com" />
This method only works for HTML pages, so use the HTTP header if you want to canonicalize other types of files.
HTTP header
You can implement the “rel=canonical” HTTP header to indicate the canonical version of a URL:
Link: <http://www.example.com/downloads/white-paper.pdf>; rel="canonical"
Use the HTTP header to specify a canonical for non-HTML documents, such as PDF files.
To use this solution, you need access to your website’s server. It also requires some technical skills, as this method is more error-prone and difficult to implement than the HTML.
Following canonical tags best practices helps mitigate the risk of search engines seeing the wrong version of the page as canonical.
Here is my list of recommendations for canonical tags:
Use absolute URLs
In theory, Google should recognize both relative and absolute URLs. However, absolute versions of URLs are less error-prone and easier to debug.
You can use either, but I'd recommend using absolute URLs so that you're sure they're interpreted correctly.
— E-e-eat more user-agents (@JohnMu) October 24, 2018
In other words, use a full URL in a canonical tag:
<link rel=“canonical” href=“https://example.com/sample-page/” />
And refrain from only including the URL path:
<link rel=“canonical” href=”/sample-page/” />
Though it’s not required, it’s recommended to use canonical tags that point to the pages they are located on.
It’s essential to implement it if you utilize parameters to track campaigns – doing so should make all URLs with a campaign parameter canonicalized to the static URL by default and stop them from getting indexed.
Here is what Google’s John Mueller said during SEO Office Hours regarding self-referential canonicals:
We use a number of factors to pick a canonical URL, and the rel=canonical does play a role in that. So, in particular, things like URL parameters, or if the URL is tagged in any particular way – maybe you have links going to that page that are tagged for analytics, for example – then it might happen that we pick that tagged URL as a canonical […]
Send clear signals to search engines
Sending clear signals consists of specifying only one canonical per page.
Avoid specifying a URL as canonical and, at the same time, redirecting said URL to a different destination.
Another case concerns canonicals added using JavaScript.
If no canonical page is specified in the HTML and a canonical tag is added with JavaScript, Google should respect it during rendering. But, if a canonical is set in the HTML and JavaScript changes it, you are sending mixed signals to Google.
Sending mixed signals can result in search engines incorrectly interpreting your canonicals or choosing the wrong version as canonical.
To avoid it, read more about rendering JavaScript in the ultimate guide to JavaScript SEO on our blog or contact us for Rendering SEO services.
Make sure you use the correct URL when linking internally
When placing internal links on your site, make sure you link to the canonical URL rather than the duplicates.
As mentioned, Google may not respect the canonical if stronger signals point to another URL. One of such signals could be increased linking to a duplicate URL which Google may view as the master version instead.
You can contact Onely and quickly fix your internal linking structure using our services.
Don’t point the canonical tag to the first page of the pagination
It’s a common mistake to only aim to index the first page of pagination. You may want to use it to prevent users from accessing the subsequent pages from search results but it’s the wrong approach. Search engines may ignore canonicalization as these pages are usually not duplicates. But if they respect the canonical tags, the pagination may be canonicalized.
If pagination contains links to unique products and there is no other linking between the product pages, the links to product pages in the pagination may be disregarded. In other words, indexable product pages won’t have internal links from other pages.
Instead, paginated pages should have self-referential canonical tags. The content on these pages is not identical and, by including self-referential tags, you tell search engines that each page is unique. If you don’t want these pages to be indexed, use noindex tags.
Point to the desktop version of a page
If your mobile site is located on a subdomain, the canonical tag should be pointing to the desktop version of the page.
Although Google does not view different versions of the same content translated into other languages as duplicate, you should still use canonical tags.
Tell search engines what the canonical page is in the same language or the best substitute language. The language variants should be self-canonical.
Find out more about hreflang tags in our International SEO article.
Prevent crawl budget issues
Canonicalized URLs may still use up your crawl budget, even if canonical tags are implemented correctly.
Though the crawl rate of canonicalized URLs should decrease over time, search engines may still focus on fetching the duplicates instead of crawling and indexing new pages.
Check your server logs to see how Googlebot behaves on your site and identify any potential crawling issues.
For crawl budget optimization you should generally:
- Reduce internal linking to non-canonical URL versions,
- Use the URL Parameter tool in Google Search Console to tell Googlebot to crawl the static versions of the URLs.
But keep in mind that crawl budget issues occur on very large sites – Google states that most sites will never need to worry about it.
I recommend that you read Google’s article on common mistakes when implementing “rel=canonical” to learn what other things to avoid.
For your canonical tags to be picked up, you need to ensure that a page has a canonical tag that points to the right page.
Below are a few useful ways to audit your canonical tags.
You also need to check whether the page is crawlable and indexable – it shouldn’t be blocked by robots.txt or marked with a noindex tag.
Google Search Console contains some helpful tools to audit your canonical pages: the Index Coverage report and URL Inspection tool.
The Index Coverage report
The Index Coverage report in Google Search Console is a valuable source of information about your indexing condition – which URLs are indexed and which are non-indexable, and why.
To analyze your site’s canonicals, navigate to the Excluded category.
That’s where you can find a few statuses that are relevant for you:

Alternate page with proper canonical tag
URLs marked with this status indicate pages for which Google respects your canonicalization to a URL.
You can expect the number of these URLs to go up if you recently canonicalized some pages. You can use this section of Google’s report to check if Google is not crawling the duplicates more than necessary.
Otherwise, these URLs do not require your attention.
Read how you should approach this status in our guide on how to fix “Alternate page with proper canonical tag” in Google Search Console.
Duplicate, Google chose different canonical than user
The status indicates that Google ignored your self-referring canonical or canonicalization to another canonical. This may occur if stronger signals are pointing to other URLs – for example, there may be increased internal linking to other pages.
This issue can also point to content problems. For example, it’s possible that the unique part of the content failed to load or you picked the wrong page to canonicalize to, e.g., because there is no sufficient content parity between duplicate and canonical pages.
If you can’t determine how to solve this problem, go straight to our guide on how to fix the Duplicate, Google chose different canonical than user issue.
Duplicate, submitted URL not selected as canonical
It means that Google found pages in your XML sitemaps that it considers duplicates. Go through your sitemap and ensure all the URLs found in it should be indexed.
Duplicate without user-selected canonical
These are duplicate URLs without any specified rel=canonical URLs – determine the most suitable canonical pages for them and add them.
Look for more tips in our guide on how to fix the Duplicate without user-selected canonical issue.
URL Inspection tool
You can use the URL Inspection tool to further investigate how Googlebot views the URLs excluded from the index.
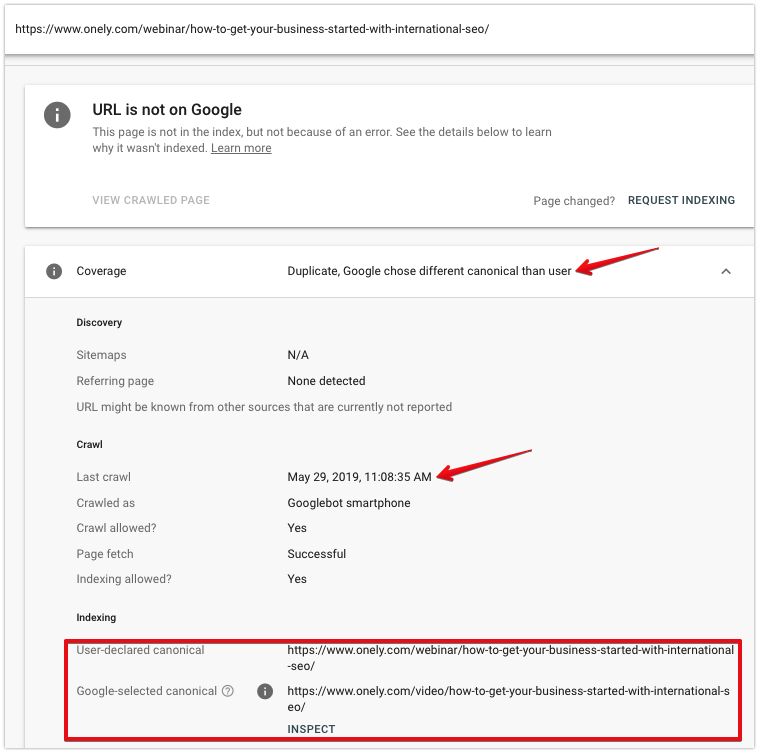
When inspecting a page, look at:
- Date of the last crawl – Last time Googlebot fetched the page. If a canonical tag was added recently, it’s likely that Googlebot has not crawled the URL since then.
- User-declared canonical – This should show the URL you selected – check if it’s the correct URL.
- Google-selected canonical – If Google chose a different canonical page, you can see which URL was selected.
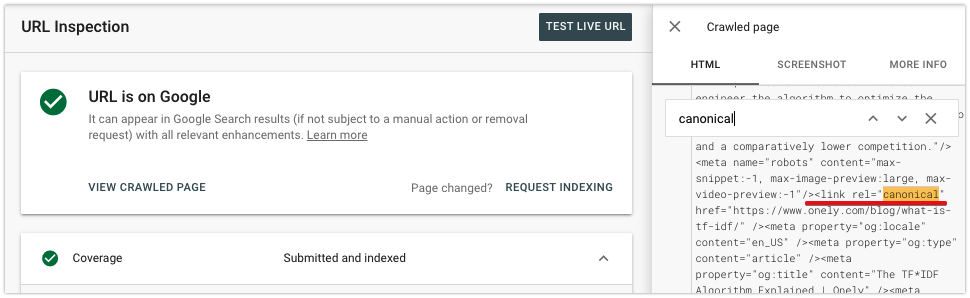
You can also check whether the canonical tag was added correctly. Click on View crawled page to examine the rendered content and search for the canonical tag in the <head> section.
In the More info tab, you can check the HTTP response header that Googlebot received.
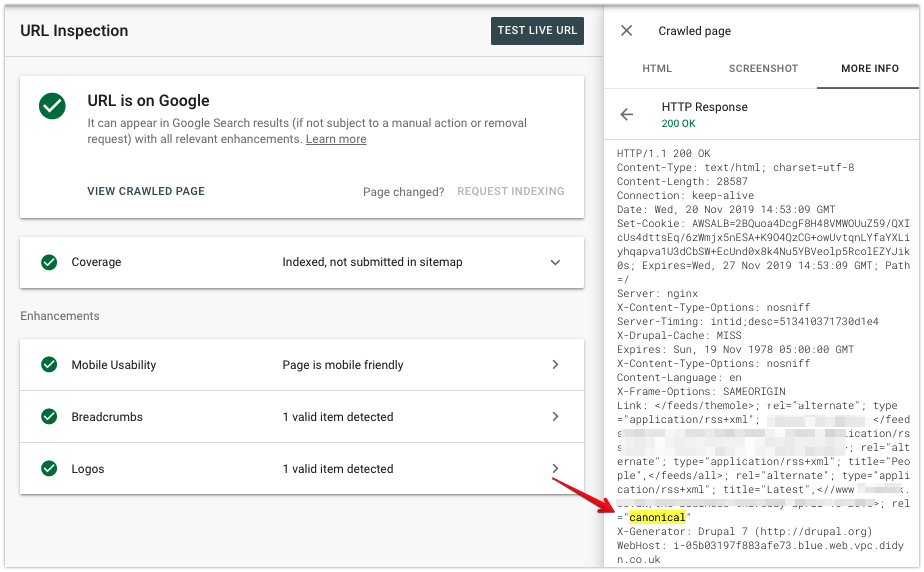
Ensure it aligns with the desired configuration, even if you are using rel=canonical in the HTML of a page.
A website crawl can help you uncover issues with your canonical tags.
Website crawlers provide you with details on the canonical vs. non-canonical ratio. They will alert you of any incorrect canonicals, such as removed/missing pages (HTTP 4xx), server errors (HTTP 5xx), or redirects (HTTP 3xx) in canonical tags. Generally, you should investigate any status codes other than HTTP 200.
Follow this guide to learn how to audit your canonicals using Screaming Frog’s SEO Spider.
Here’s what you can do now: Still unsure of dropping us a line? Read how technical SEO services can help you improve your website.NEXT STEPS
Wrapping up
Implementing canonical tags gives you the possibility to tell search engines which URL represents the best version of each piece of content. You may then influence which pages appear in search results – and which ones are treated as secondary.
Canonicals are mere signals that search engines don’t need to respect. But, in many cases, you can increase the chances of your canonical tags being respected. How?
Follow the outlined best practices – here is a condensed list of my recommendations:
- Identify duplicate content on your pages and choose which page version should be primary – e.g. because it’s the most representative or valuable page,
- Ensure you send consistent signals to search engines regarding your canonicals,
- Use self-referential canonical tags,
- Make sure your implementation of the robots.txt file, noindex tags, and the sitemap aligns with your canonicalization,
- Ensure there is sufficient content parity between duplicate and canonical pages,
- Limit the internal linking to the duplicate pages.

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!







