Blocked due to access forbidden (403) is a Google Search Console status. It means that some of your pages aren’t indexed because your server denied Googlebot access to them.
This isn’t typical, so this status may be a signal that your website requires a technical review.
The cause of Blocked due to access forbidden (403)
The usual indexing process starts with Googlebot discovering the URL. Google doesn’t include it in the index right away but crawls it to find out as much information as possible about its content.
Thanks to crawling, the search engine knows what queries it’s worth showing your pages for and whether they are valuable for users.
Google rarely indexes a page it hasn’t crawled. And when it does happen, it’s a negative thing for your SEO. Learn more by reading Justyna Jarosz’s article about the “Indexed, though blocked by robots.txt” status.
To crawl a page, Google must behave similarly to the user’s browser. Googlebot sends a request regarding the URL to your server. Servers respond to such requests with HTTP status codes, which tell browsers and crawlers if and how they can access the contents of that URL.
Status code 403 is one of the possible server answers. It means that:
- Your server understood the request. It knows where the page can be found,
- Browsers or crawlers making the request need permission to access this specific resource,
- Your server denied the request because the presented credentials didn’t warrant granting that permission.
Status code 403 may be a normal thing. It’s a way to protect sensitive data from unauthorized visitors. However, when your server returns this status code to Googlebot, it indicates a problem.
Googlebot never provides any credentials while making a request, so in its case, the 401 status code would be more fitting. The 401 code means that the request wasn’t completed due to the lack of valid authentication credentials.
So what does this error result from? There are two possibilities:
- No search engine and no server are perfect, so there could be a mistake where the server returns the 403 code instead of the more precise 401 code. The 401 page still wouldn’t be indexed, but the issue is fixable by changing server settings.
- Behind the 403 response, there is a deeper technical problem on your website, the source of which should be investigated.
The “Blocked due to access forbidden (403)” status indicates that your website may benefit from thorough server log analysis. Contact Onely and put an end to the mystery of your server’s struggles.
How to troubleshoot the “Blocked due to access forbidden (403)” pages?
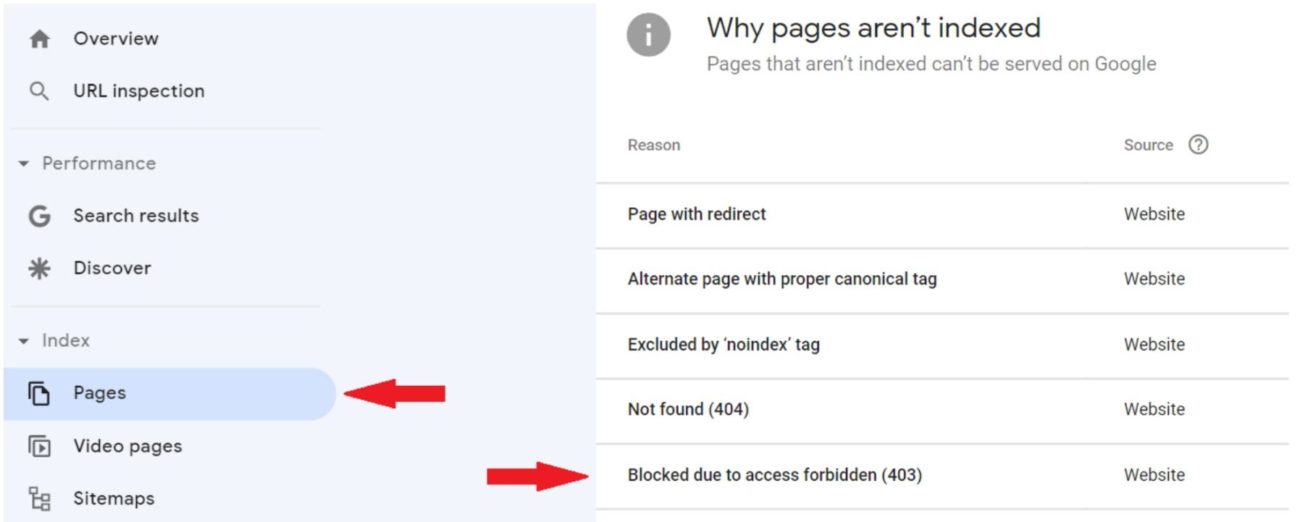
You can find your pages affected by the “Blocked due to access forbidden (403)” status in the Page Indexing report. It’s easy to access from the left navigation bar in your Google Search Console.
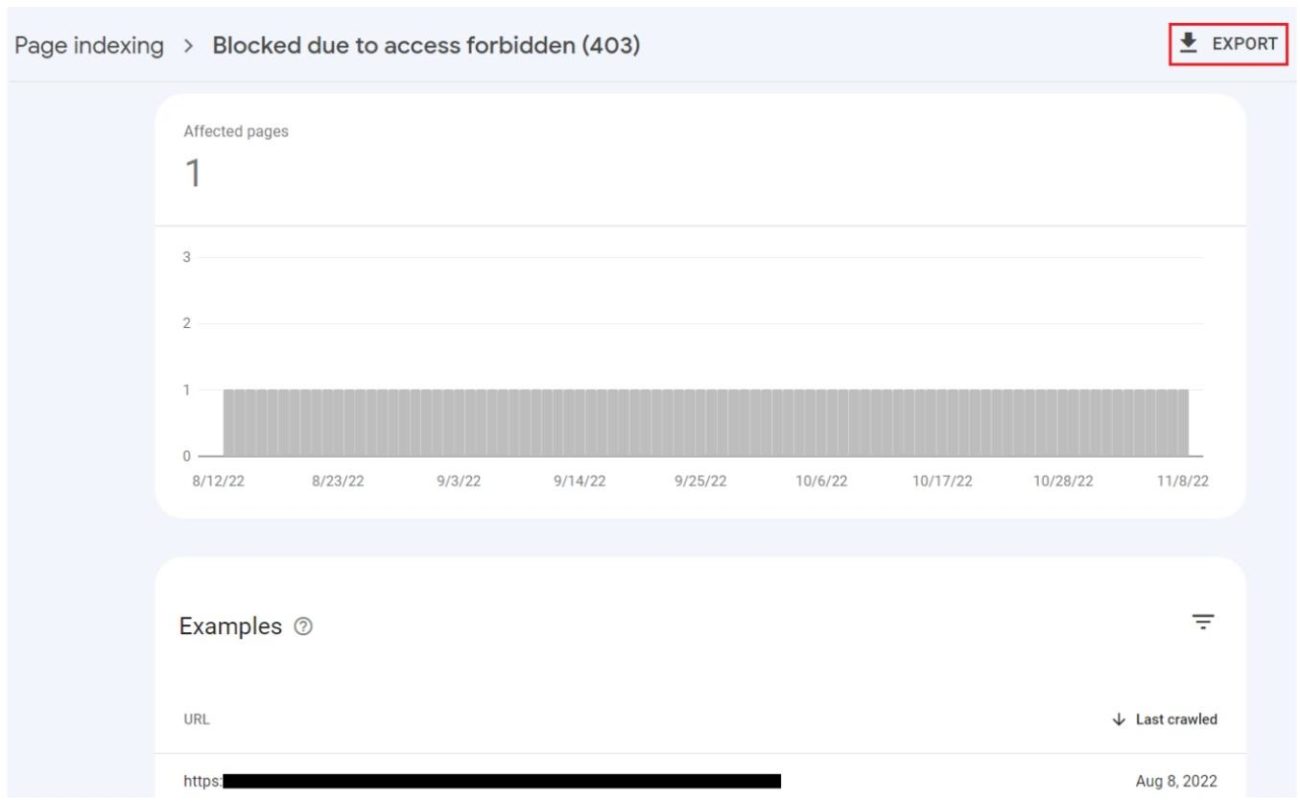
After clicking on the status name, you will see a graph showing how the number of affected pages has changed over time and a list of URLs. You can export the list using the button located in the right upper corner.
What’s very useful is that you can filter your pages only to those you have included in the sitemap before opening the list with the “Blocked due to access forbidden (403)” status.
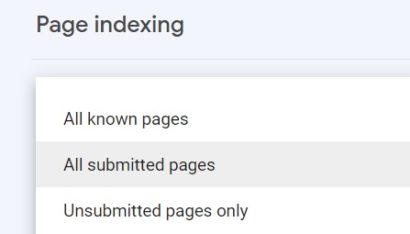
This way, you can easily spot the URLs that need immediate fixing. Since you’ve included them in your sitemap, they are strategically important to you and should be indexed in order to bring organic traffic to your site.
Should all your “Blocked due to access forbidden (403)” pages be indexed?
Assessing which URLs are the most critical brings us to the first step of troubleshooting the “Blocked due to access forbidden (403)” issue, which is deciding whether or not affected pages should be present in the Google index.
There are three possible scenarios:
1. You may want to avoid indexing of pages containing data that shouldn’t be found on Google Search.
However, returning a 403 status by your server is not the best way to keep them out of the index. If you want pages to remain unindexed without adding chaos to your site, block them with the noindex tag.
2. There may be pages on your website that you want to appear on Search but block the possibility of seeing all content by users who aren’t logged in. A good example is a paywalled news article.
Googlebot will never log into your website, so to get those pages indexed, you need to grant Googlebot access to your pages without blocking it with the login wall. That means changing your server’s settings and treating the crawler differently than users’ browsers.
It’s worth noting that Google is cautious about situations where you show Googlebot different content than users. This is why you need to provide structured data informing the crawler that it’s dealing with paywalled content.
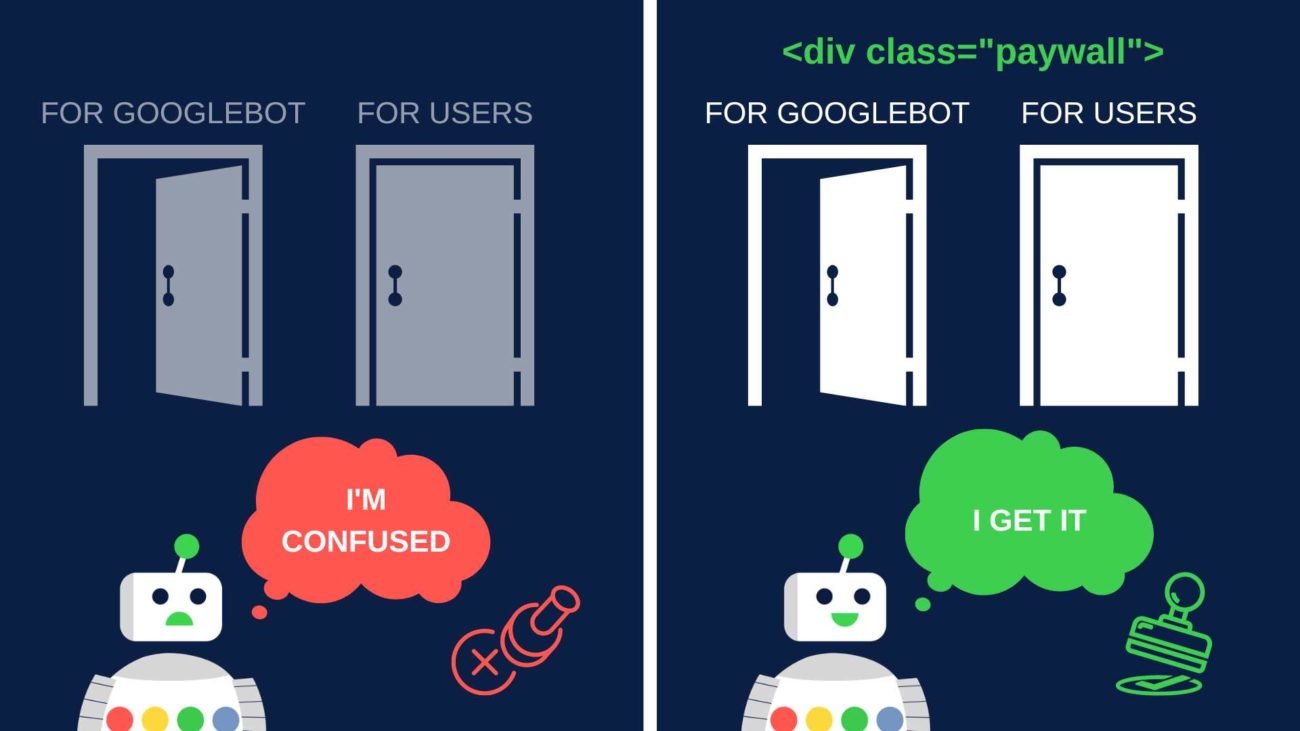
You can find instructions for adding structured data to subscriptions and paywalled content in Google’s guidelines. Without adhering to them, you risk getting hit by a manual penalty.
3. Finally, there may be pages on your site that you would like to be publicly available but they still return the 403 status code to Googlebot.
Fixing these pages can be the most time-consuming, as it’s not always possible to find the cause of the error right away.
Reasons for public pages returning 403 status code
| Possible cause | How to fix it |
| Errors in your .htaccess file | The .htaccess file provides configuration changes to your server when using shared hosting. Typically, your Content Management System creates it automatically.
Deactivate the old .htaccess file and create a new one. Next, crawl your pages with a Googlebot user agent to see your website from its perspective and make sure the problem disappears. |
| Faulty WordPress plugins | The “Blocked due to access forbidden (403)” status on WordPress pages may be caused by an incompatible plugin. Try deactivating your plugins one by one to find the root of the chaos. |
| Wrong IP adress | The error may occur if your domain name points to the wrong IP address. Verify your A record. |
| Malware infection | Scan your websites for signs of a malware infection. Malicious software can generate and sustain errors in your .htaccess file. |
The long-term solution to your indexing problems
The above solutions will help you take care of the indexing of specific pages and temporarily fix the “Blocked due to access forbidden (403)” status. However, they don’t guarantee that the issue won’t return.
The best way to maintain satisfactory index coverage is to conduct regular technical SEO audits. Let us help you nip any growing threats to your visibility in the bud.
Explore other 4xx client error statuses by reading our articles on: “Not found (404) vs. Soft 404,” and “Blocked due to other 4xx issue.”
Wrapping up
The “Blocked due to access forbidden (403)” error occurs when Googlebot can’t crawl your page because the server denied its request. It can be fixed by:
- Providing a noindex tag on pages that should stay deindexed,
- Changing your server’s settings and providing proper structured data for pages that you want to get indexed but stay protected by some login wall,
- Investigating your .htaccess file, WordPress plugins, A record, and website security breaches for pages that you want to get indexed and be visible to every visitor.
The “Blocked due to access forbidden (403)” status may be a sign of a more complex problem. Onely’s technical SEO services can help you to investigate and overcome issues holding back your website.

Hi! I’m Bartosz, founder and Head of Innovation @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with your organic growth – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!