
We wanted to know how much JavaScript Googlebot could read, crawl and index. To achieve that, we built a website – https://jsseo.expert/. Each subpage had content generated by different JavaScript frameworks. We tracked server logs, crawling, and indexing to find which frameworks are fully crawlable and indexable by Google.
JavaScript SEO Experiment Findings:
- Inline vs. External vs. Bundled JavaScript makes a huge difference for Googlebot.
- Seeing content in Google Cache doesn’t mean it is indexed by Google.
If you want to know which frameworks work well with SEO, but don’t want to go through the experiment’s documentation, click here to scroll straight to the results section and see the charts presenting the data.
Why I Created This Experiment
In recent years, developers have been using JavaScript rich technology, believing Google can crawl and index JavaScript properly. In most cases, developers point to this Google announcement as proof that Google’s technical guidelines allow JavaScript rich websites.
Yet, there are multiple examples online of such decisions going badly. One of the most popular examples of JavaScript SEO gone bad is Hulu.com’s case study.
Even though there are tons of data and case studies clearly showing Google’s problems with JavaScript crawling and indexation, more and more websites are being launched with client-side JavaScript rendering (meaning that Googlebot or your browser needs to process JavaScript to see the content).
I believe Google’s announcement was widely misunderstood. Let me explain why.
Most developers reference this section of Google’s blog post:
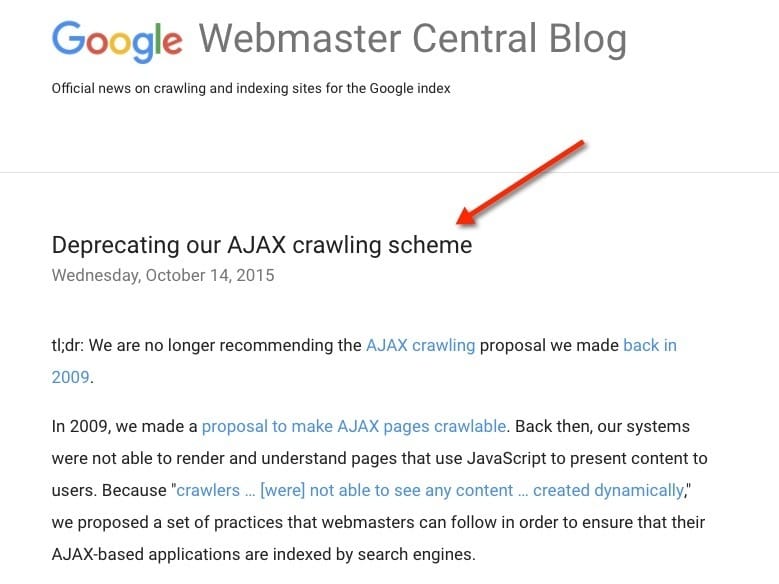
Times have changed. Today, as long as you’re not blocking Googlebot from crawling your JavaScript or CSS files, we are generally able to render and understand your web pages like modern browsers. To reflect this improvement, we recently updated our technical Webmaster Guidelines to recommend against disallowing Googlebot from crawling your site’s CSS or JS files.
In the same article, you will find a few more statements that are quite interesting, yet overlooked:
Sometimes things don’t go perfectly during rendering, which may negatively impact search results for your site.
It’s always a good idea to have your site degrade gracefully. This will help users enjoy your content even if their browser doesn’t have compatible JavaScript implementations. It will also help visitors with JavaScript disabled or off, as well as search engines that can’t execute JavaScript yet.
Sometimes the JavaScript may be too complex or arcane for us to execute, in which case we can’t render the page fully and accurately.
Unfortunately, even some well-respected websites in the JavaScript development community seem to be overly optimistic about Google’s ability to crawl and index JavaScript frameworks.
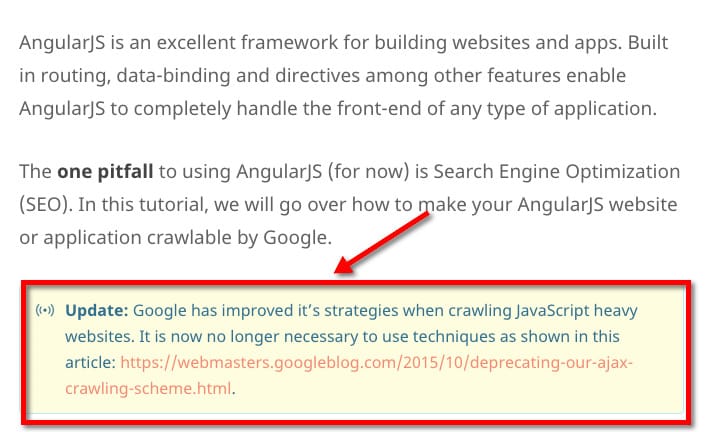
Source: https://scotch.io/tutorials/angularjs-seo-with-prerender-io
The best web developers are well aware of JavaScript indexing issues, and if you want to see it first-hand, watch just a few minutes from the video below:
Jeff Whelpley
Angular U conference, June 22-25, 2015, Hyatt Regency, San Francisco Airport
“Angular 2 Server Rendering”
If you search for any competitive keyword terms, it’s always gonna be server rendered sites. And the reason is because, although Google does index client rendered HTML, it’s not perfect yet and other search engines don’t do it as well. So if you care about SEO, you still need to have server-rendered content.
Jeff Whelpley was working with Tobias Bosch on server rendering for Angular 2. Tobias Bosch is a software engineer at Google who is part of the Angular core team and works on Angular 2.
Unfortunately, I didn’t find any case studies, documentation, or clear data about how Google crawls and indexes different JavaScript frameworks. JavaScript SEO is definitely a topic that will soon become very popular, but there is no single article explaining to JavaScript SEO beginners how to start diagnosing and fixing even basic JavaScript SEO problems.
[UPDATE: Google acknowledged that they use Chrome 41 for rendering. It has since made the debugging process a lot easier and faster.]
This experiment is the first step in providing clear, actionable data on how to work with websites based on the JS framework used.
Now that we have discussed the why of this test, let’s look at how we set it up.
Setting Up the Website
The first step was to set up a simple website where each subpage is generated by a different framework. As I am not a JavaScript developer, I reached out to a good friend of mine and the smartest JavaScript guy I know – Kamil Grymuza. With around 15 years of experience in JavaScript development, Kamil quickly set up a website for our experiment:

The core of the website was coded 100% in HTML to make sure it is fully crawlable and indexable. It gets interesting when you open one of the subpages:
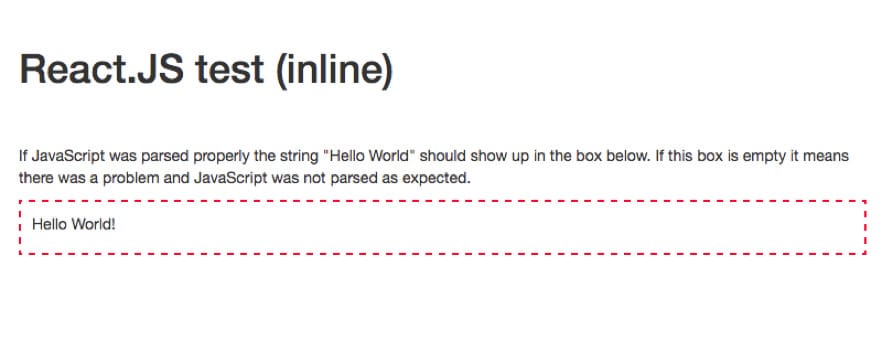
The structure of the subpages was dead simple. The whole page was plain HTML with a single red frame for JavaScript generated content. With JavaScript disabled, inside the red frame was empty.
JavaScript Enabled:
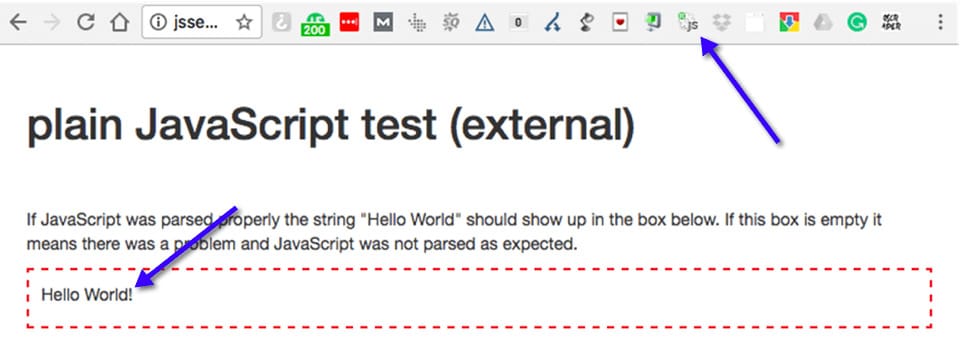
JavaScript Disabled:
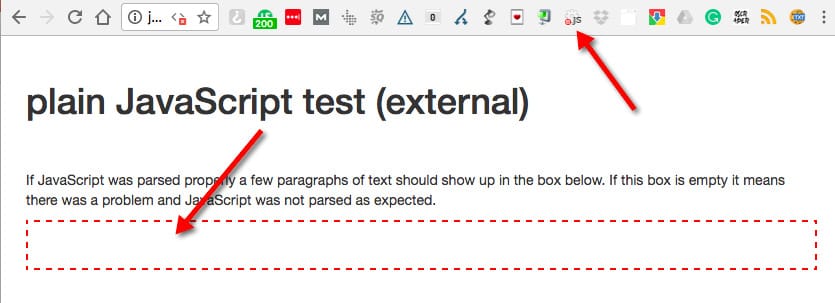
At this point, our experiment was more or less ready to go. All we needed now was content.
Content
Our “Hello World” pages got indexed a few hours after we launched the website. To make sure there was some unique content we could “feed” Googlebot, I decided to hire artificial intelligence to write the article for us. To do that, we used Articoloo, which generates amazing content written by AI.
I decided the theme of our articles would be based on popular tourist destinations.
This is how the page looks after adding the content. Everything you see in a red frame is generated by JavaScript framework (in the case of the screenshot below – by VUE JS).

Having indexed content is only half the battle, though. A website’s architecture can only work properly if Googlebot can follow the internal and external links.
JavaScript Links
Links were always a problem with client-rendered JavaScript. You never knew if Google was going to follow the JS links or not. In fact, some SEOs still use JavaScript to “hide links”. I was never a fan of this method; however, does it even make sense from a technical point of view? Let’s find out!

We’ve found a very simple method to find out if Google was following the JavaScript generated links of a specific JS framework. We added a link into each framework’s JavaScript generated content, creating a kind of honeypot for Googlebot. Each link was pointing to http://jsseo.expert/*framework*/test/.
Let me show you an example:

To make it even easier to track, the links pointed to the *framework*/test/ URLs.
The link generated by the Angular 2 page (https://jsseo.expert/angular2/) would point to https://jsseo.expert/angular2/t e s t/ (spaces added to avoid messing up the experiment with a live link!). This made it really easy to track how Googlebot crawls /test/ URLs. The links weren’t accessible to Googlebot in any other form (external links, sitemaps, GSC fetch etc.).
Tracking
To track if Googlebot visited those URLs, we tracked the server logs in Loggly.com. This way, I would have a live preview of what was being crawled by Googlebot while my log data history would be safely stored on the server.
Next, I created an alert to be notified about visits to any */test/ URL from any known Google IP addresses.
Methodology
The methodology for the experiment was dead simple. To make sure we measured everything precisely and to avoid false positives or negatives:
- We had a plain HTML page as a reference to make sure Googlebot could fully access our website, content, etc.
- We tracked server logs. Tools – Loggly for a live preview + full server logs stored on the server (Loggly has limited log retention time).
- We carefully tracked the website’s uptime to make sure it was accessible for Googlebot. Tools – NewRelic, Onpage.org, Statuscake.
- We made sure all resources (CSS, JS) were fully accessible for Googlebot.
- All http://jsseo.expert/*FRAMEWORK-NAME*/test/ URLs were set to noindex, follow, and we carefully tracked if Googlebot visited any of /test/ pages via custom alerts setup in Loggly.com.
- We kept this experiment secret while gathering the data (to prevent someone from sharing the test URL on social or fetching it as Googlebot to mess with our results). Of course, we couldn’t control crawlers, scrapers and organic traffic hitting the website after it got indexed in Google.
EDIT 5/25/2017
After getting feedback on this experiment from John Mueller and seeing different results across different browsers/devices, we won’t be continuing to look at cache data while proceeding with this experiment. It doesn’t reflect Googlebot’s crawling or indexing abilities.
JavaScript Crawling and Indexing Experiment – Results
After collecting all the data, we created a simple methodology to analyze all the findings pouring in.
There were five key checks we used for each JavaScript framework.
Experiment Checklist
- Fetch and render via Google Search Console – does it render properly?
- Is the URL indexed by Google?
- Is the URL’s content visible in Google’s cache?
- Are the links displayed properly in Google’s cache?
- Search for unique content from the framework’s page.
- Check if ”*framework*/test/” URL was crawled.
Let’s go through this checklist by looking at the Angular 2 framework. If you want to follow the same steps, check out the framework’s URL here.
1. Fetch and render via Google Search Console – does it render properly?
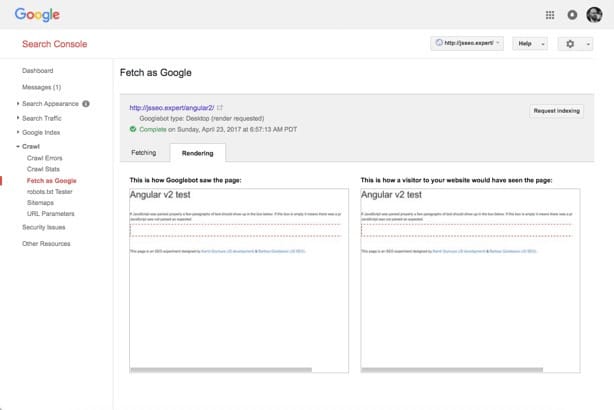
As we can see, Google Search Console couldn’t render the content within the red frame (JavaScript generated content) so the result of this test is obviously: FAIL.
[UPDATE 09/28/2017: It turned out that because of errors in the Angular.io Quickstart that we populated in our experiment, Google was not able to render this page.
In the Angular.io Quickstart, there were examples of a code written in ES6 syntax: “let resolvedURL = url”. Google Web Rendering service doesn’t support ES6, so it was not able to render the code. It was not only Google, as Internet Explorer <= 10 was not able to render it as well.
If you are a developer, you might assume that Babel should take care of this. Well, not exactly 🙂 The error was apparent in the Angular loader which job was to load Babel. Seems like a paradox, doesn’t it?
As a result, the content was not indexed. It affected not only the experiment subpage, but also all the websites that were based on the Angular 2 Quickstart Guide.
After fixing the error, we were able to index the content.
You can read more about it in my article “Everything You Know about JavaScript Indexing is Wrong“.
There is a lot of evidence that a single error in your code can make Google unable to render and index your page. Here is an example taken from “The Ultimate Guide to JavaScript SEO” by Tomek Rudzki:
“In December 2017, Google deindexed a few pages of Angular.io (the official website of Angular 2). Why did this happen? As you might have guessed, a single error in their code made it impossible for Google to render their page and caused a massive de-indexation.
The error has since been fixed.
Here is how Igor Minar from Angular.io explained it (emphasis mine):
“Given that we haven’t changed the problematic code in 8 months and that we experienced a significant loss of traffic originating from search engines starting around December 11, 2017, I believe that something has changed in crawlers during this period of time which caused most of the site to be de-indexed, which then resulted in the traffic loss.”
Fixing the aforementioned rendering error on Angular.io was possible thanks to the experienced team of JavaScript developers and the fact that they implemented error logging. Fixing the error let the problematic pages get indexed again.”
2. Is the URL indexed by Google?
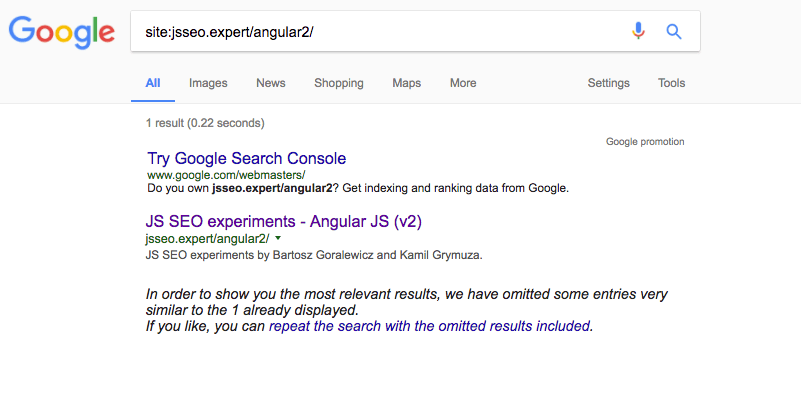
The URL is properly indexed by Google, so this is obviously: SUCCESS!
3. Is the URL’s content visible in Google’s cache?
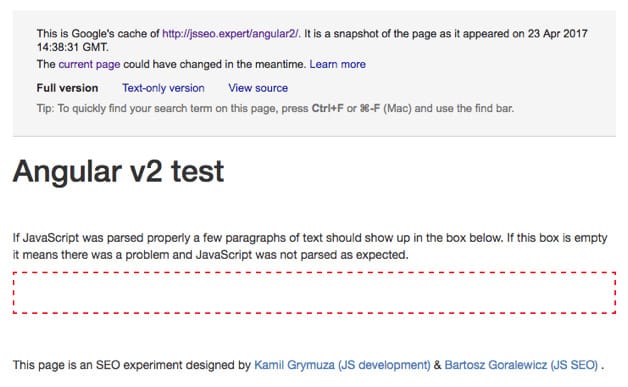
Results:
Google Cache didn’t parse the JavaScript properly and isn’t showing the content within the red frame. This is obviously: FAIL!
4. Are the links displayed properly in Google’s cache?
Same goes for links. We can’t see either the content or links generated by JavaScript. This test is also: FAIL!
5. Search for unique content from the framework’s page
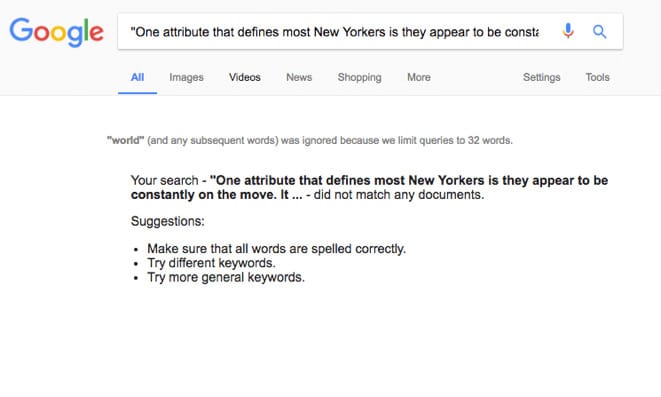
Google couldn’t find any of the JavaScript generated content. We can also mark this step as: FAIL.
6. Check if ”*framework*/test/” URL was crawled
The goal of this step was to check if Googlebot is able to crawl JavaScript-generated links. To check that, we had JavaScript generated links pointing to http://jsseo.expert/*framework*/test/ URL. In this case, the link was going to https://jsseo.expert/angular2/ T E S T /(Again, not a working link as it would mess up the results for our test).
To track Googlebot’s crawling we used Loggly, and to double check the data we manually went through the logs.
Here are the results for Angular 2:
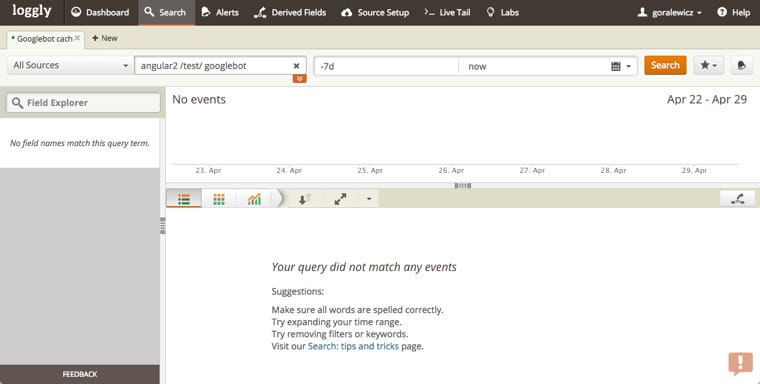
At this point, you probably saw this result coming. Googlebot didn’t see JavaScript generated content, thus it couldn’t follow the JavaScript generated link within the content. This step is definitely: FAIL.
Reach out to us for Angular SEO services for better crawling, rendering, and indexing of your JavaScript content.Want to optimize your Angular usage?
You are probably curious how did Googlebot do with other JavaScript frameworks. Let’s go through the final results.
JavaScript Crawling and Indexing – Final Results
Let’s start with basic configurations for all the frameworks used for this experiment.
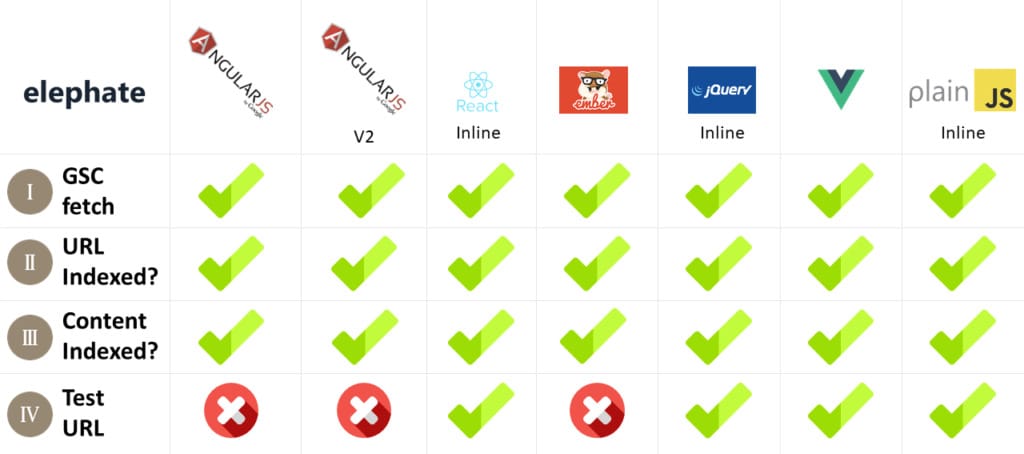
[UPDATE: This image was updated to reflect additional further information and research.]
What is really interesting is that Googlebot is fully processing some of the major JavaScript frameworks, but isn’t doing very well with Angular 2, when it’s built by Google.
[UPDATE: As you can see, Google Fetch and Render was able to render the page properly, but the content was not indexed. If you’re curious to why this happened, read “JavaScript vs. Crawl Budget: Ready Player One“.]
The valuable takeaway from this experiment is that Googlebot is fully equipped to crawl and index React (inline), jQuery (inline), Vue, and plain JavaScript (inline). It’s processing JavaScript, parsing JavaScript generated content, and crawls JavaScript generated links. You need to remember, though, whether those links pass PageRank or not is a whole other topic – and an exciting experiment idea.
This is not the end of the experiment, though. The most exciting part of the results is still ahead of us.
Let’s have a look at how Googlebot parses different JS frameworks depending on JavaScript location. Let’s start with jQuery.
Experiment Results – jQuery – Internal vs. External vs. Ajax call
When designing this experiment, I went through a lot of Google patents related to crawling efficiency. I was expecting that Google may try to optimize processing JavaScript, as crawling JavaScript requires more resources compared to plain HTML and CSS.
External JavaScript files were hosted on the same server and within the same domain.

Looking at the results above, this is when things get both exciting and complicated. We can clearly see that Googlebot is saving resources. Crawling inline JavaScript code is probably much more efficient from Google’s perspective than processing all the extra requests and Ajax calls.
This also changes what we usually recommend to our client’s developers. Making JavaScript code external may not be the best solution if that code is responsible for generating internal links. Externalizing JavaScript code can mess up a website’s architecture! We can safely assume that if Googlebot isn’t following the links, they also don’t pass PageRank or any other signals.
Let’s have a look at the React JavaScript framework created by Facebook.
Experiment Results – React – Inline vs. External

I was surprised to see that Googlebot is parsing Facebook’s JavaScript framework this well. I would expect Google to be fully compatible with Angular (built by Google). This experiment proved otherwise. Again, JavaScript’s placement makes a huge difference, and making JavaScript external blocks crawling of /test/ URLs exactly the same as in the case of different JavaScript frameworks.
Speaking of which, let’s have a look at plain JavaScript, which should, theoretically, be the simplest to crawl.
Experiment Results – Plain JavaScript – Internal vs. External

Again, not much to add here. I think you start to see the interesting pattern this experiment exposed. Inline code is fully crawlable and indexable, when external somehow blocks Googlebot from visiting /test/ URL.
And last but not least, Google’s own JavaScript framework – Angular JS.
Experiment Results – Angular JS 1 and 2 – Inline, vs External vs. Bundled

In the SEO community, we are used to Google making things complicated, so I won’t elaborate on this topic. Suffice to say that Google’s framework was the most complicated and difficult to diagnose. Fortunately, it also delivered the most exciting results.
After presenting the results of this experiment, Angular JS is always the most discussed JavaScript framework. Let me elaborate a little bit about the results above.
We can clearly see that none of the Angular frameworks are SEO-friendly “out of the box”. Now, this is interesting – they weren’t designed to be SEO-friendly without server side rendering.
Googlers know and admit that.
The problem with client rendered Angular websites comes from the lack of expertise of some Angular JS developers. Let me quote a few very smart Angular JS guys, who also happen to be responsible for creating and developing this framework.
During my research, I found a short YouTube video that explains it all.
If you search for any competitive keyword terms, it’s always going to be server rendered sites. And the reason is because although Google does index client-side rendered HTML, it’s not perfect yet and other search engines don’t do it as well. So if you care about SEO, you still need to have server-rendered content.
Jeff Whelpley
Angular U conference, June 22-25, 2015, Hyatt Regency, San Francisco Airport
“Angular 2 Server Rendering”
Jeff Whelpley worked with Tobias Bosch (Google engineer, part of the core Angular team). You can find profiles of both Jeff and Tobias here: https://angular.io/about/.
I think the quote and video above explain it all. If you work with an Angular JS website, I highly recommend watching the whole thing and, of course, sending it over to your client’s developers.
The takeaway here is really hard to argue with and gives us (SEOs) a powerful argument against client rendered Angular websites. I don’t know about you guys, but I had a lot of my clients considering such solutions.
If you are making an Angular website, it has to be server rendered.
Not doing so is simply poor development. It is only OK to use client rendered Angular for content that isn’t publicly accessible (not accessible for Googlebot). For example, your website’s CMS panel, etc.
[UPDATE 3/5/18: Here is an updated version of the above experiment results:

Experiment Results – Inline, External, or Bundled?
As it turned out, the placement of JavaScript code (inline, external, or bundled) really matters for Googlebot. It was really surprising to me, as we usually advise our clients to externalize JavaScript wherever possible. On the other hand, we know that crawling JavaScript is MUCH more expensive for Google, compared to crawling plain HTML/CSS websites. I can only guess that downloading external JavaScript is an extra step/cost for Googlebot.
Technical things aside, this experiment gave us a little extra info we didn’t expect. Info that sheds some light on how Google’s crawling and indexing works.
Google Cache vs. Google’s Index?
Googlers have mentioned several times that Google cache works a bit different than Google index. Still, I find it quite interesting to see that the content can be cached, but NOT indexed.
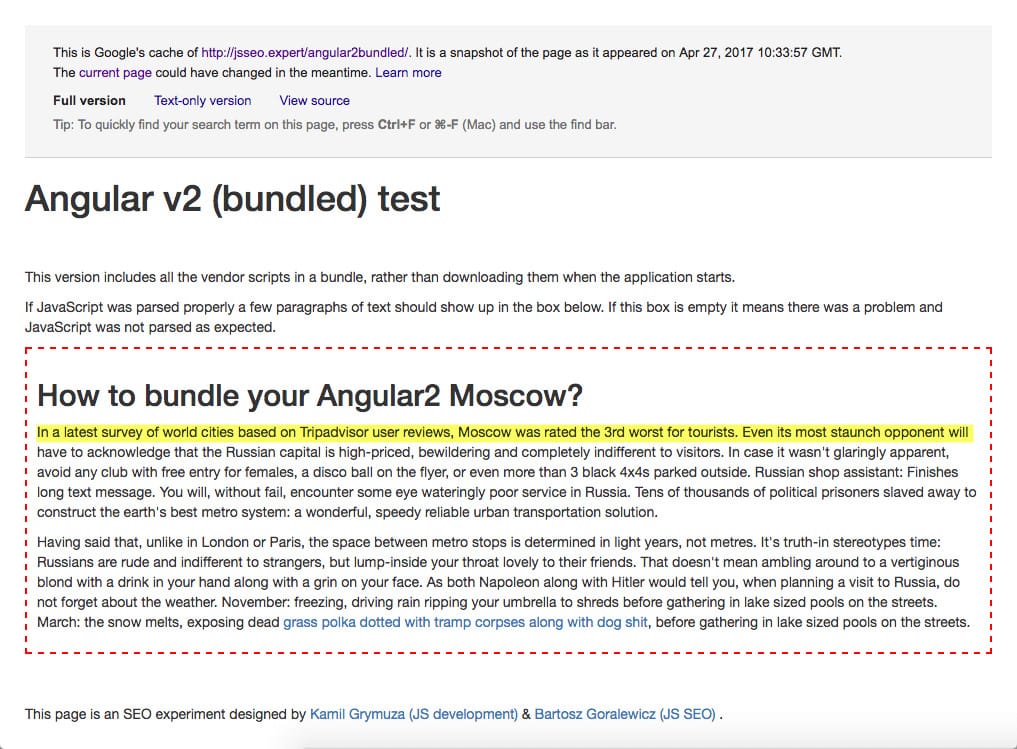
https://www.google.com/search?q=%22n+a+latest+survey+of+world+cities+based+on+Tripadvisor+user+reviews%2C+Moscow+was+rated+the+3rd+worst+for+tourists.+Even+its+most+staunch+opponent%22&oq=%22n+a+latest+survey+of+world+cities+based+on+Tripadvisor+user+reviews%2C+Moscow+was+rated+the+3rd+worst+for+tourists.+Even+its+most+staunch+opponent%22&aqs=chrome..69i57.699j0j4&{google:bookmarkBarPinned}sourceid=chrome&{google:omniboxStartMarginParameter}ie=UTF-8
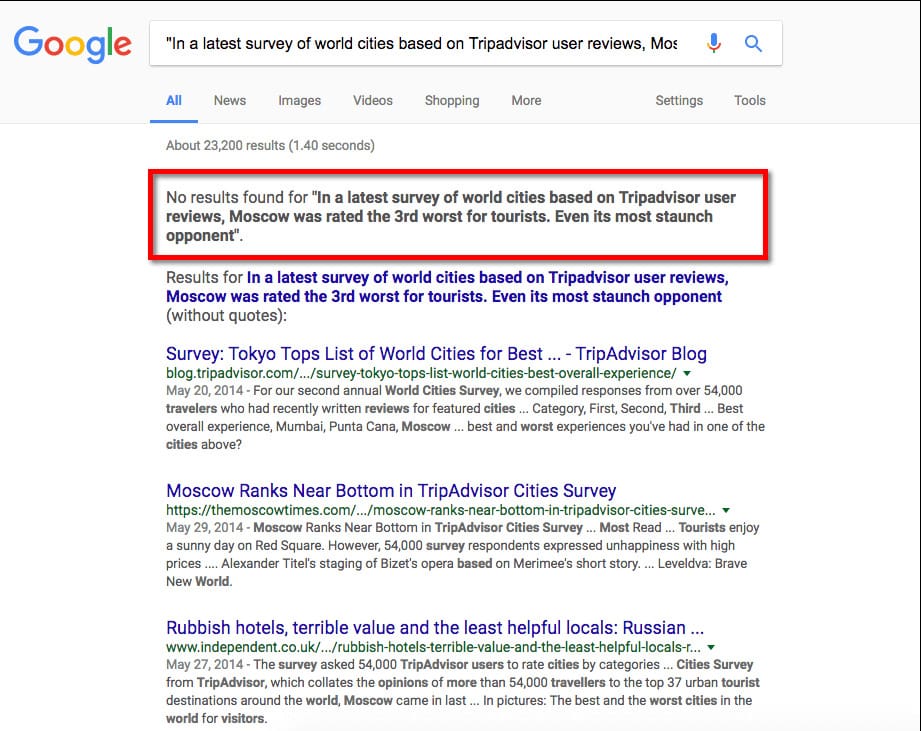
This really puts a huge question mark on even looking at Google’s cache while diagnosing potential technical SEO issues, and definitely confirms Google’s stand on Google cache being a separate entity from Google’s Index.
[UPDATE 5/25/2017: After getting feedback on this experiment from John Mueller and seeing different results across different browsers/devices, we won’t be continuing to look at cache data while proceeding with this experiment. It doesn’t reflect Googlebot’s crawling or indexing abilities.]
Methodology Behind the Experiment
1. The goal of the experiment was to achieve 100% transparency and accuracy of the results achieved. To make sure this was the case, we focused on multiple metrics.
2. The experiment was setup on a separate, brand new domain with no external links, no history, etc.
Before deploying the website live, we configured:
- Loggly (to access server logs easier)
- Server log storing (Loggly stores server logs for a limited period of time)
- NewRelic – we used it to make sure there are no anomalies, downtimes, etc. that could affect crawling and indexing
- OnPage.org – we use OnPage.org for technical SEO but in this case we used it to track uptime
- Statuscake.com – also for uptime monitoring. Undocumented downtime could affect our crawling data and we wanted to make sure it is not the case
- Google Search Console – for fetching URLs as Googlebot
- Google Analytics
3. We made sure the experiment was kept secret when we were gathering data. Making it public would open an option to temper the log and crawling data (e.g., external links to /test/ URLs, tweets, etc.).
4. We checked if the frameworks’ URLs were indexed properly to make sure that Googlebot had a chance to crawl and index the content on those URLs.
5. We added one page that was 100% HTML generated to have a “control group” URL where we could check if our methodology and tests added up.
To make sure we are even more transparent, we published the code used for our experiment on Github.
Github – experiment’s documentation
This experiment only makes sense if we are fully transparent about the code and methodology we used. You can find full Github repository with all the code used to build our experiment here https://github.com/kamilgrymuza/jsseo.
The Experiment Continues
I am really excited about what we’ve managed to achieve with this simple experiment, but I know it is just the start.
I believe this experiment is the first step to building an open communication between JavaScript developers and SEO. JavaScript frameworks will only get more popular, but at the same time, SEO is not going away.
We are all aware that Google isn’t making this process any easier, and experiments like the one presented here can save hundreds of thousands of dollars spent on website development resulting in poor SEO results.
Feel free to contact me or Kamil with your questions. If you are a developer, it would be awesome if you could contribute to our Github repository JS framework/configuration. Just drop me a line and we’ll get it done so you can be sure your code is SEO friendly.
[Update #1]
Within few days from the first tweets (I presented this case study at Search Marketing Summit, Sydney and Big Digital, Adelaide), John Mueller created a JavaScript SEO group. It is great that John is taking this direction. JavaScript is causing massive SEO issues when not implemented properly. Initiatives like this one can sure help a lot of webmasters.
We're putting together a group to discuss JavaScript sites/frameworks & search. Join us, if you make one! https://t.co/DQUGK4sdHn
— John has updated his unnamed profile name #stapler (@JohnMu) May 12, 2017
You can join the group here to follow the JavaScript SEO discussions. I’ve already got tons of valuable feedback on this experiment from John. I will make sure to use it when continuing our experiment and research.
[Update #2]
If you’re interested in knowing the next step in my journey and whether or not the results in this experiment were right or wrong, then you need to read “Everything You Know About JavaScript Indexing is Wrong” right away.
Also, I strongly recommend you read “The Ultimate Guide to JavaScript SEO“.
And if you’re struggling with optimizing JavaScript on your own, learn how our JavaScript SEO services can help you improve your website.

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!







