
It’s been a while since I checked out the current JavaScript SEO status of Hulu.com. Now, while working on a few JS rich websites, I decided to look into Hulu’s situation again.
Why Hulu.com? Their website is unique and especially interesting from an SEO perspective, because it is often the only one that can terminate Hulu-related Google queries. It is in Google’s interest to rank and show Hulu.com. Let me show you an example.
Hulu.com is the only place where you can watch many popular US TV shows like “Casual”, “The Awesomes” and many more. You can find a full list of Hulu.com exclusive shows here. This gives Hulu the upper hand in SEO, but, unfortunately, this enormous SEO potential is not fulfilled.
Hulu SEO problems
Search query:
“The Awesomes” – this is Hulu’s original series.
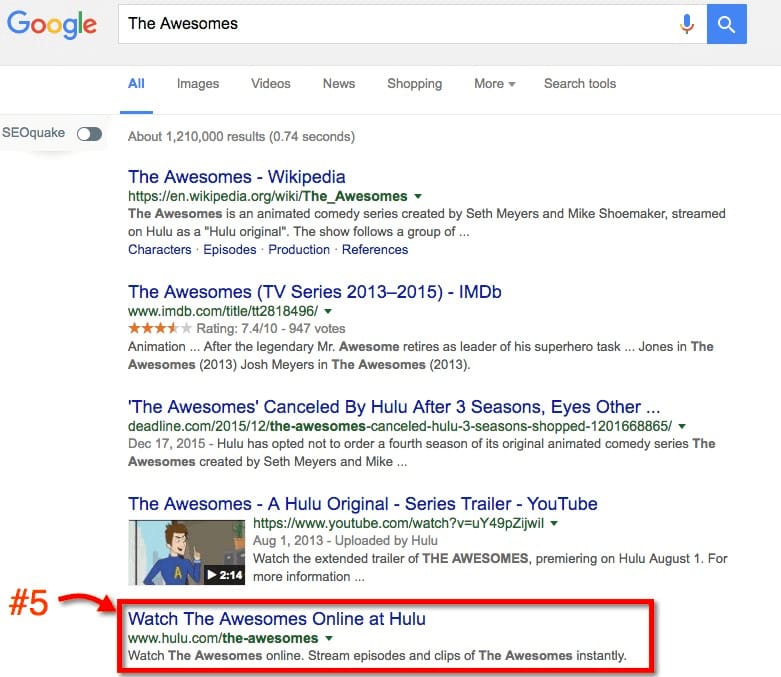
Let’s search for the title of the Hulu landing page we see above – “Watch The Awesomes Online at Hulu”.
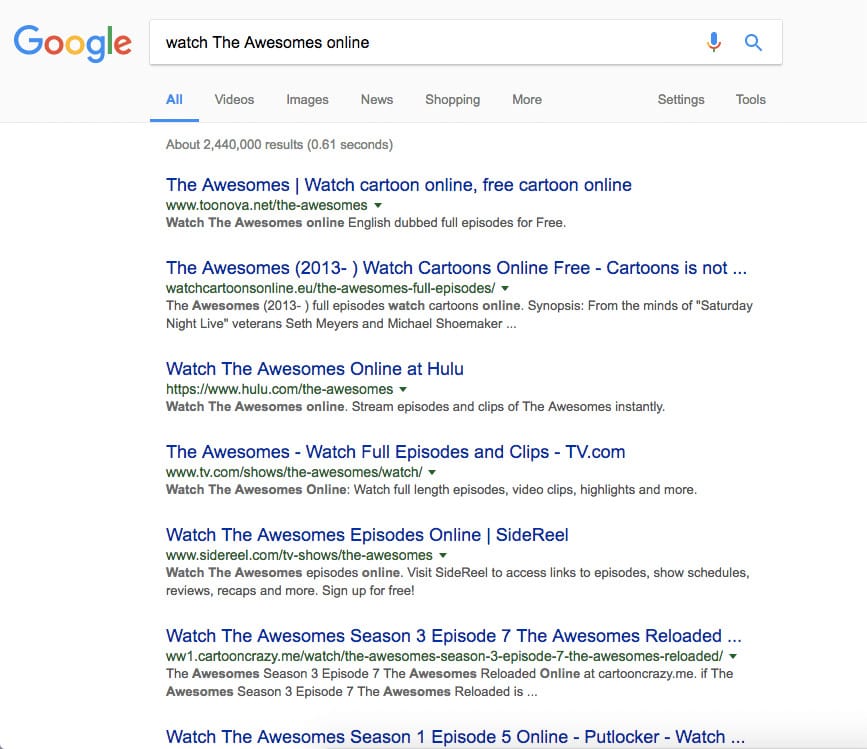
Hulu.com is losing hundreds of thousands of Google Organic visits, which actually helps websites like the one above to get more traffic. Why isn’t Hulu.com ranking for its own content? By looking at the data above, we can safely assume that Hulu has a major SEO problem and is underranked in Google. This is where JavaScript SEO can help to understand it better.
Hulu.com is a JavaScript based website, which means that you see JavaScript code rendered/processed by your browser if you look into Hulu.com.
Here is how the https://www.hulu.com/series/the-awesomes-c4d582d2-01ce-4639-a411-b0c903b88dcb landing page looks like:
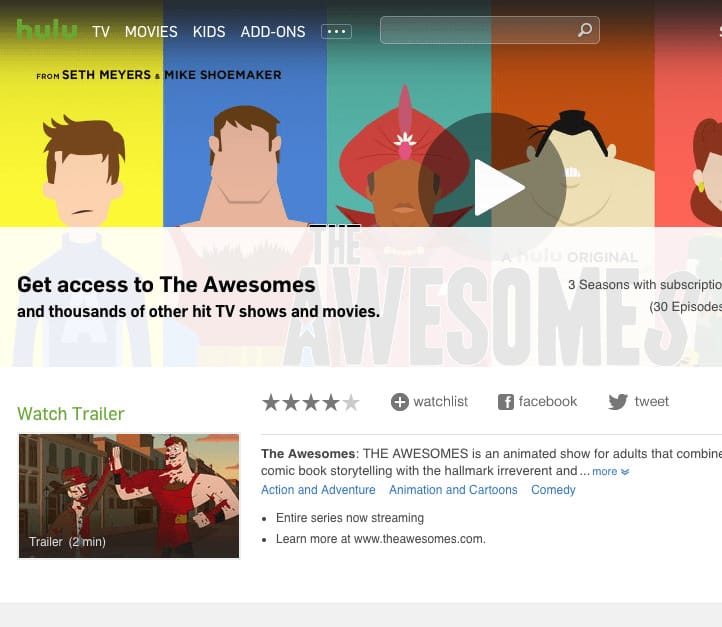
But when you look “under the hood” of this page, you won’t see the regular HTML code you would expect.
This is what you see when you click “View Source” (Chrome).
To see the code with processed DOM and rendered JavaScript, you need to use the “inspect element” option in Chrome.
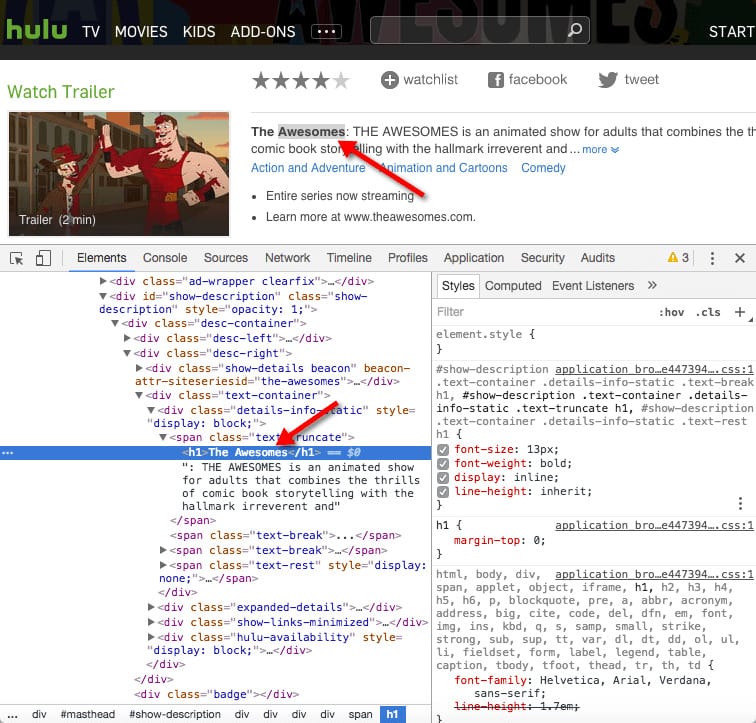
H1 and descriptions aren’t visible when looking into raw JavaScript code. They can only be seen after processing DOM and fully rendering JavaScript.
I almost hear some of you saying: “Bartosz, but Google is crawling and indexing JavaScript now”. It seems it is indeed, Google itself once admitted that here.
Times have changed. Today, as long as you’re not blocking Googlebot from crawling your JavaScript or CSS files, we are generally able to render and understand your web pages like modern browsers. To reflect this improvement, we recently updated our technical Webmaster Guidelines to recommend against disallowing Googlebot from crawling your site’s CSS or JS files.
How do you check if Google is crawling and indexing your website properly? This is where it gets complicated. Most people would recommend fetching and rendering your website using Google Search Console. However, there are two issues that need to be addressed to follow this recommendation:
- I obviously don’t have access to Hulu’s Google Search Console.
- Fetch and render is an awesome tool, but it is good to double check the fetch result with Google cache and Google index. How to do that?
Here comes the simplest and most obvious solution to check if Google can properly crawl and index Hulu.com. The awesome thing is that you can do this within a few seconds right now and see it for yourself.
How to check JavaScript indexation?
1. Go to the JavaScript rich website e.g. https://www.hulu.com/series/casual-22d27085-0f5e-42aa-949f-1b81ba5726d8
2. Find any unique content within a page and copy it
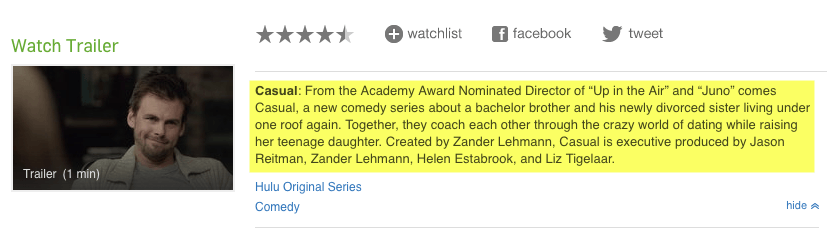
3. Search for the content and see if the URL from step 1 is ranking (unique content should rank #1)
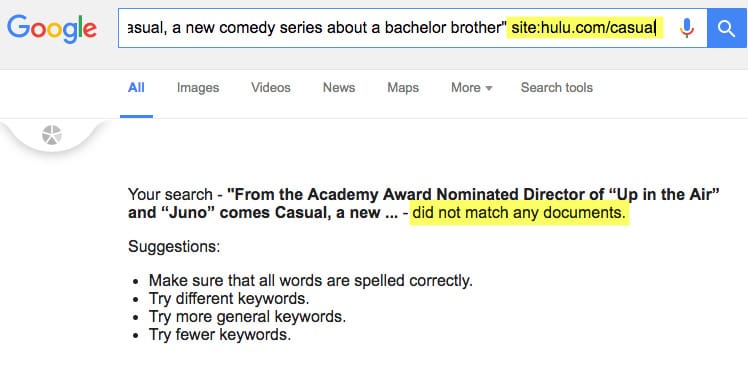
Did Hulu.com pass the test?
Unfortunately, Google never indexed Hulu’s content:
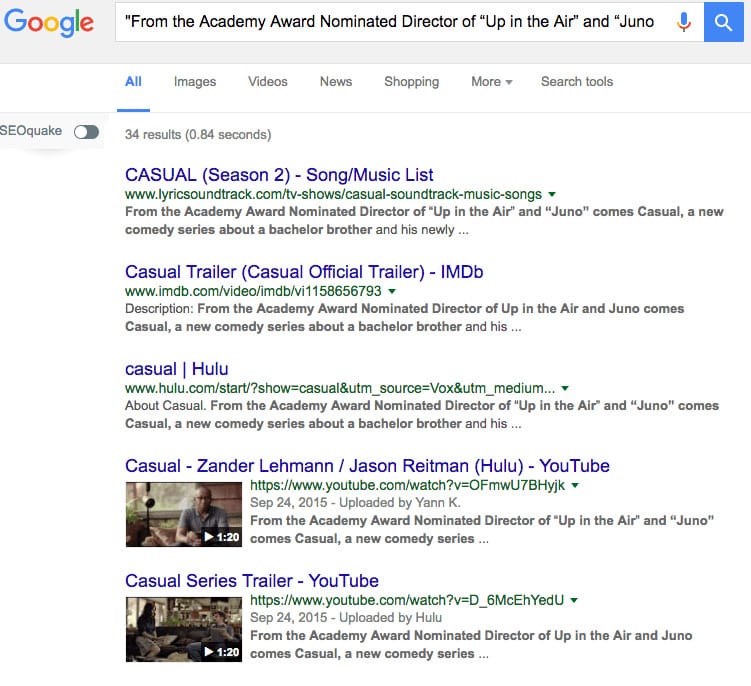
Now if you want to be SUPER sure, you can take it one step further and search for the page’s content only within a specific page.
How to do this? Go to Google and search for “website’s content” site:hulu.com/casual
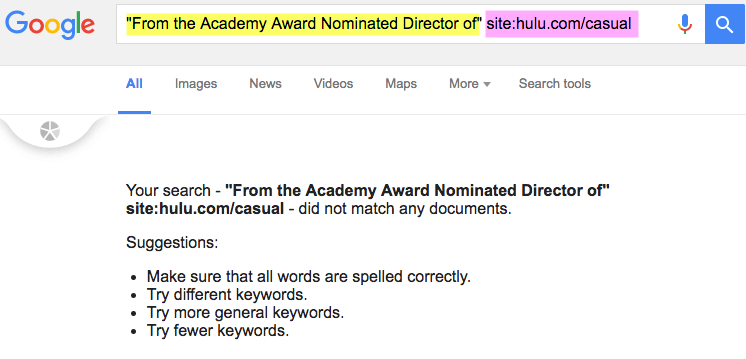
Unfortunately, Google has never seen this content.
We can shorten the query to see if Google indexed at least short pieces of content from Hulu.com.
Again, no luck. We are now 100% sure that Google never indexed Hulu’s content.
You probably think hulu.com/casual URL isn’t indexed in Google. Let’s check this out.
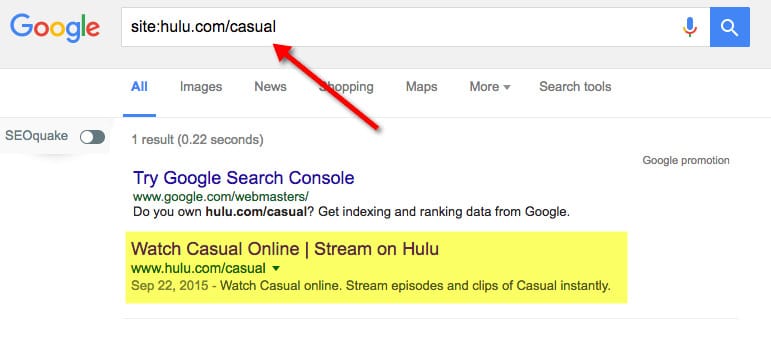
As you can see, the URL is in Google index. This also means that Google had to find SOME content there to index it.
This leads us to another question. What did Google crawl and index?
Fortunately, we can analyze this valuable data in Google Cache.
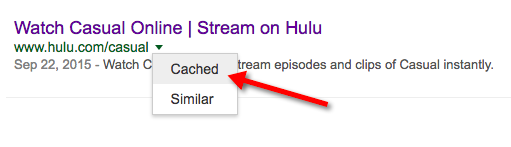
Unfortunately, as you can see below, there is a bug in Hulu’s code, which is blocking Google Cache from being presented properly.
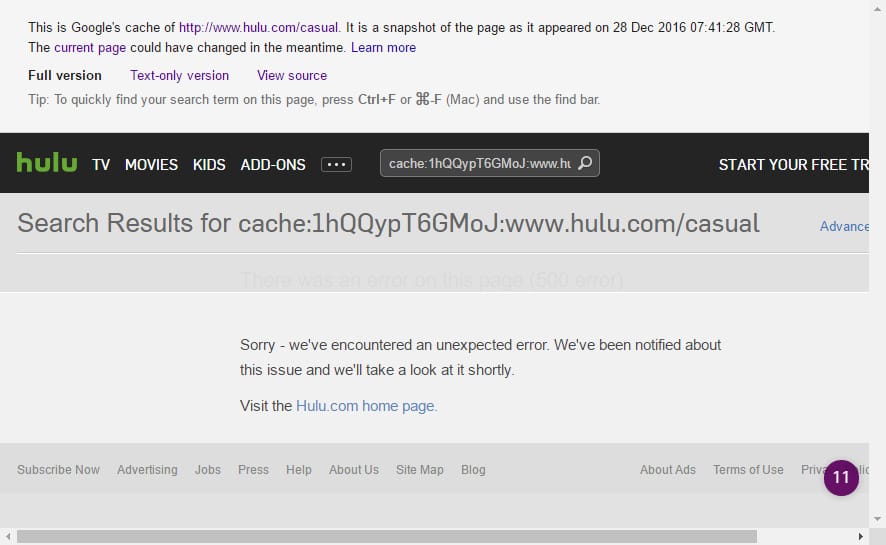
Yeah, you are not wrong. What you see above is a … code 500 error page.
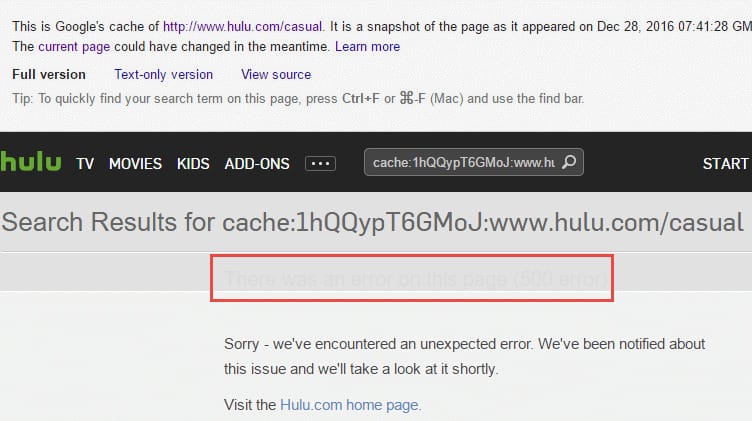
What we see above comes from a bug in Hulu’s code causing Hulu.com to search for the slug from Google’s cache URL.
Let me explain. This is Google’s cache URL:
http://webcache.googleusercontent.com/search?q=cache:1hQQypT6GMoJ:www.hulu.com/casual+&cd=1&hl=en&ct=clnk&gl=en
Due to the bug in the code, Hulu.com takes a piece of the code “search?q=cache:1hQQypT6GMoJ:www.hulu.com/casual” and performs a search.

This is how it should look:
http://www.hulu.com/search?q=cache:1hQQypT6GMoJ:www.hulu.com/casual
Hulu is protecting its content from being displayed on different domains; this content we see above won’t be displayed in Google’s cache. Here is an example, if I try to load hulu.com from my own domain, the content isn’t showing up and is returning a code 500.
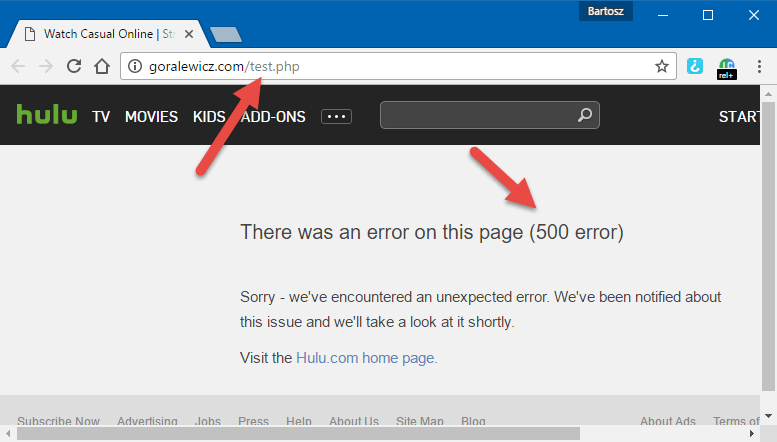
This solution protects Hulu from being scraped and from launching their content from other websites (movies, shows etc.) This is definitely a good move, but it should be disabled for Google Cache.
What is interesting, however, is that some of the pages from hulu.com return 404 error codes when looking into cache.
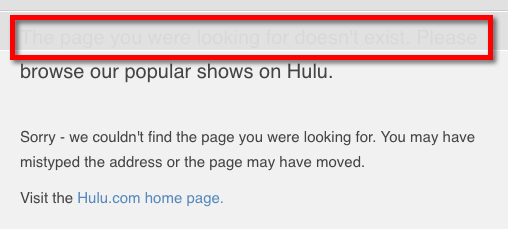
Enough about cache, let’s move on.
Risks for Hulu.com
Hulu.com is not getting the organic traffic it could easily get, which is the main, yet not the only, issue here. Having a lot of unique content that is neither crawled nor indexed leads to more potential problems. Hulu.com has a lot of unique content that is not indexed by Google. The only thing that is preventing scrapers from stealing this content is … JavaScript. If Hulu’s content is going to be scraped and published on any other website, Google will consider that scraper website as an original source of the content. We’ve already seen such problems before and that’s why we know, for a fact, that to reverse them on a large scale is almost impossible (in both a legal and technical way).
2.Google updates
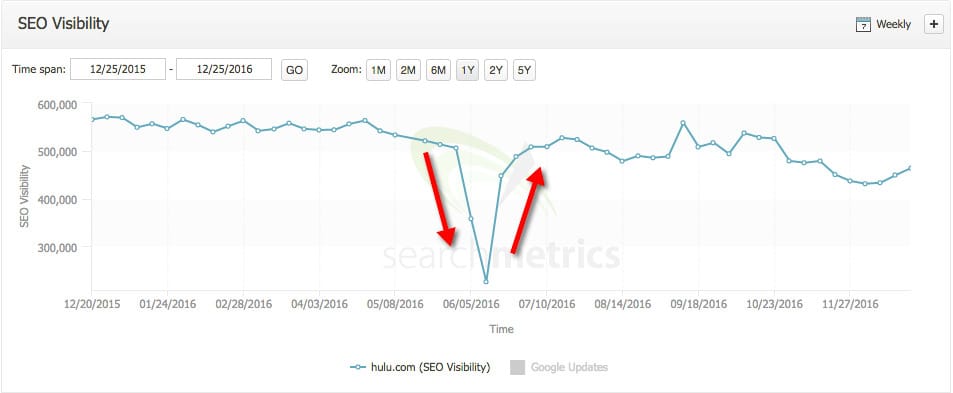
With thousands of thin content pages indexed (in a crawler’s eyes), Hulu is a perfect target for Google Panda, Phantom, and other algorithms that target thin/poor content. This is a very likely reason why Hulu.com ranks so badly right now, with a constant downtrend in visibility.
How to solve Hulu’s problems with JavaScript indexing?
Problems:
Hulu has two problems as far as crawling by search engines is concerned.
1. Hulu’s internal search algorithm interferes with Google crawler making it impossible for Google to see the same content the visitors see.
2. Displaying actual content (show titles, descriptions, etc.) requires JavaScript to be enabled,
which may prevent crawlers from seeing that content.
Potential solutions:
When it comes to solving those problems, here are two proposed solutions aimed at improving the crawling effectiveness of hulu.com:
1. The search algorithm should be modified in order to strip “cache:www.hulu.com/” from the search criteria string (if present) so that the request performed by Google crawlers can be understood properly and relevant content can be returned.
First and foremost though, we need to make sure that the actual requests performed by Google crawlers are properly understood and return the expected data (what I mean by actual requests are requests performed by the actual crawlers, not only those emulated in the browser by prepending the address with “cache:”).
2. Once #1 is addressed, Google may be able to circumvent problem #2 (relying on JavaScript for rendering the page) and the crawling effectiveness will already improve. This would be good because modifying the search algorithm, as opposed to the changes described below, should be a fairly simple change.
If it turns out that solution #1 didn’t fully solve the problem and Google cannot run the Hulu JavaScript well enough to actually see the content (either on the search results page or on other pages), a change would have to be made to actually render more data on the server.
As a result, the content (TV show’s title, description, etc.) would be sent in the initial HTML file and would be immediately visible to search engine crawlers (without the need to use JavaScript). Only then would JavaScript be used to enrich the user interface and, consequently, improve the user experience. This, unfortunately, would be way more involving than the first step.
Of course, each case is different and largely depends on the website’s code architecture. I won’t go through every option, as it is a topic for another post. I guess that Hulu.com uses jQuery and cannot simply use services like prerender.io. Still, for JavaScript rich websites, one of the simplest solutions is using prerender services, but it gets tricky when content is loaded dynamically (e.g., websites with a lot of ad listings). If the content is generated each time a page is requested, prerender can slow it down. Prerender services work best for websites with fairly static content (such as, e.g., Hulu.com).
What is prerender?
You can find a lot of info about prerender online, but I will give you a simplified version, which I think is enough to understand the process. Prerender services take the JavaScript code, such as the one below:
And they change it into nice looking HTML, as can be seen on the screenshot below:
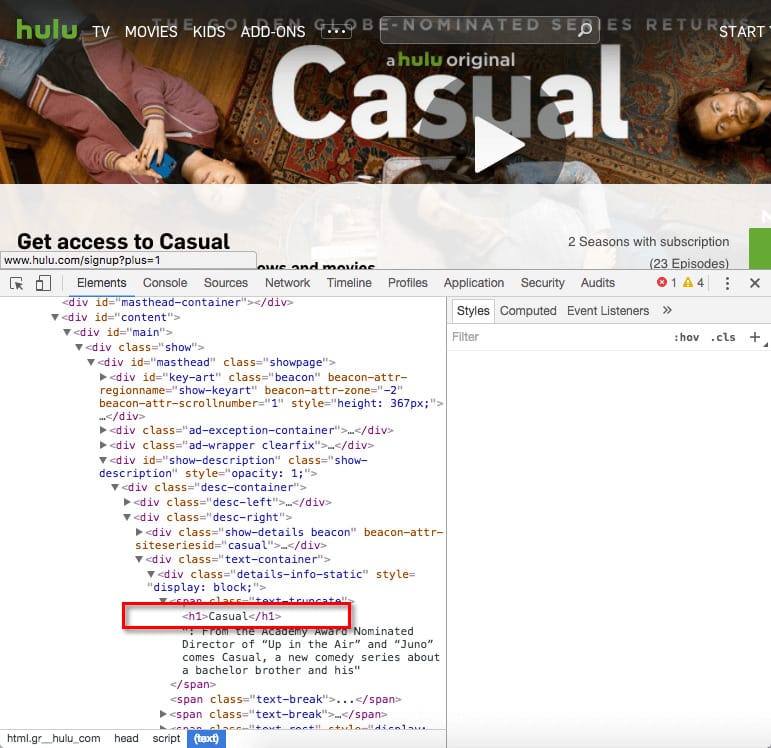
Basically, we do what every browser does on the server side. Thanks to that, we don’t leave rendering to Google. Our website gets crawled and indexed properly, it ranks better, and everyone is happy.
Hope
With so many problems and so much content never seen by Google, Hulu.com is a perfect case for spectacular SEO recovery. I wonder why Hulu’s team isn’t tapping this potential yet. Most likely, we can’t see all their issues from the outside, and, as it often happens, fixing their JavaScript indexing problems requires a lot of development work.
I hope that after reading this post, you can see that JavaScript SEO isn’t that difficult to understand and can be done well with just a little extra effort.







