Google Cache is an extremely useful feature. Simply speaking, it is a copy of a website created when search engine robots accessed it last. I believe it is safe to say that most internet users had a chance to benefit from the cache when the website they were trying to view was down for some reason. Also, many SEO experts strongly depend on the cache while trying to detect possible indexation problems. However, it is not meant to be used for such purposes. Keep reading to find out why.
How to access Google Cache
The cache is accessible in two ways:
By clicking on the green arrow next to the URL in a search engine result page and then choosing the “Cached” option:

By adding the “cache:” string at the beginning of the URL that you see in your browser:

You can also find some Chrome plugins that will allow you to see the cached version of a page within a click (Web Cache Viewer, for example).
I can’t see the cache of my website. Is this bad?
Note that there is a directive for meta tags that can exclude pages on your website from being cached:
If you can’t access the cached version of your website make sure there is no content=“noarchive” attribute in its source code. Of course, when the page itself is non-indexable or blocked from crawling in the robots.txt file, you shouldn’t expect it to be cached either. Also, if a particular page is new and has just been indexed, it may take a while for the cache to be available. Just be patient and give it a few extra hours to show up.
The important information here is that not having your website in Google Cache shouldn’t negatively affect its online visibility. Some tests regarding the cache removal using noarchive have already been made and no harm was observed, neither for the rankings nor for the traffic. Actually, some would say that disabling the cache will give you more control of what the users will see on your website as they won’t be able to access the outdated version.
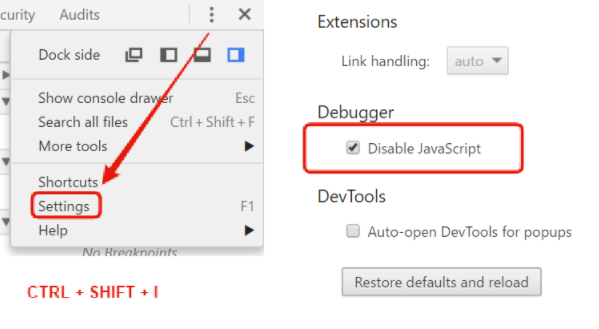
When the cache is not available, you can get the most similar view when you disable JavaScript. You can do this in Chrome Developer Tools (it works only in the Incognito mode). Just go to Settings and mark the appropriate option in the Debugger section.
But why is it similar? We’re getting to the bottom of the case.
What exactly does Google Cache show you?
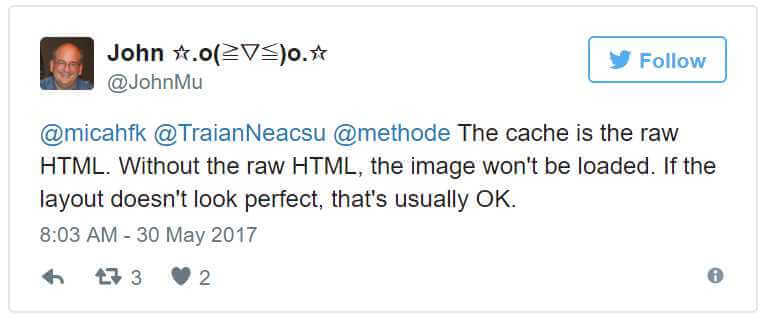
The cached version of a website is not an exact copy. Actually, it is much less than that. Let’s see what John Mueller, Google’s Webmaster Trends Analyst, has to say about it:
We can find even more details on this topic in two of the Google Hangouts (they are fairly up-to-date):
20.09.2016 – 46:50
If you have javascript framework website that’s something where the cached version will reflect the HTML page that you serve, not specifically the rendered version.
[…]
Again, with regards to JavaScript frameworks sites, single page apps, those kind of things – I wouldn’t use the cached version of a page as a representative of the page itself, because that’s not really that suitable for something where JavaScript needs to be executed, in order for the content to be visible.
26.08.2016 – 11:29
In general, the cache is not always representative of what we have actually indexed for a page. So that’s something to kind of keep in mind. That’s not really where you need to go to double check that we’ve actually indexed this content. What I might do instead is to do something like a site: query for that URL or for some keywords that you’ve changed, you’ve modified on that page, to see that we can actually pick that content up properly.
[…]
If this is the JavaScipt-based website then we have to actually render those pages to pick them up for indexing and those are things that we wouldn’t show at all in the cache. So if it is the site that uses JavaScript framework like Angular or Polymer, any of the other frameworks out there, where the HTML page itself is essentially pretty plain, not something that contains the content, then you wouldn’t see that in the cached page. One thing you could do in a situation like that, if you want to take the extra step and make sure that GoogleBot can actually pick up that content, you could use something called isomorphic JavaScript, which is a way of rendering your pages on the server and sending the rendered version to users.
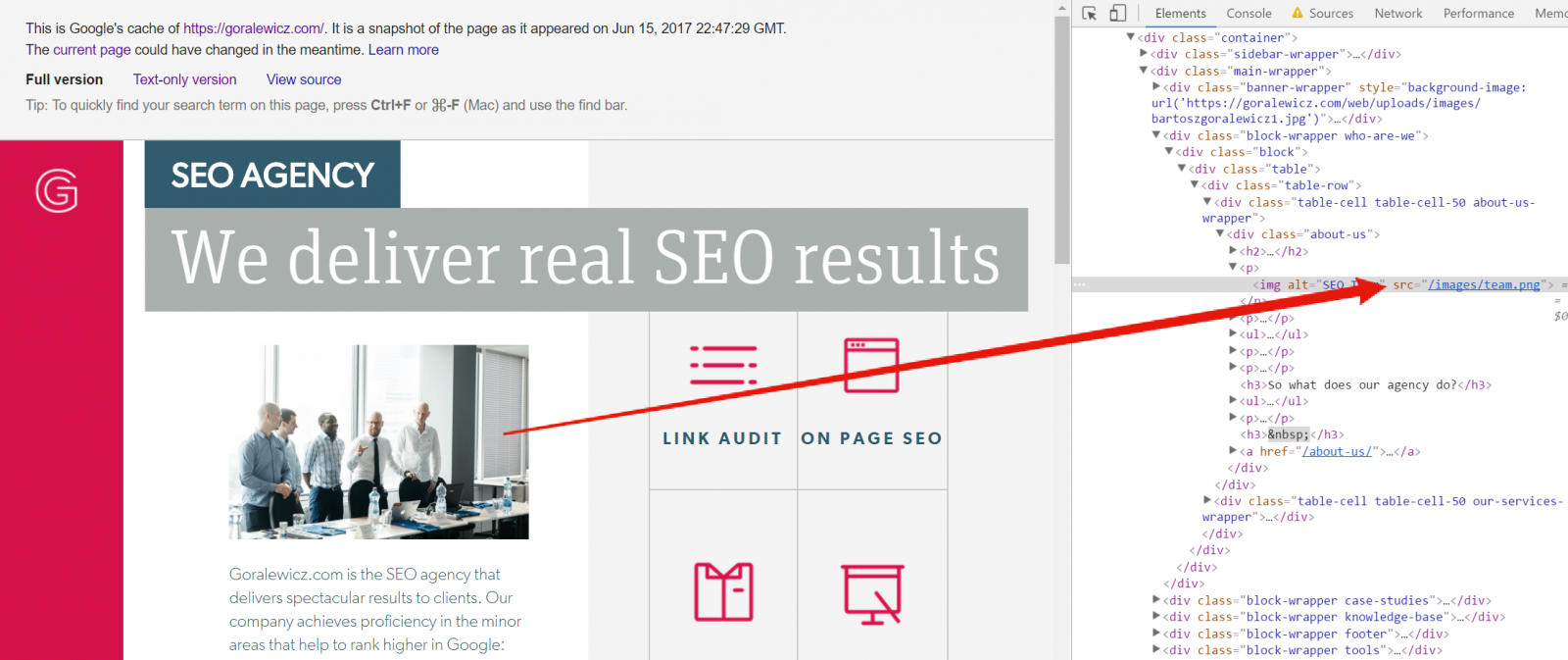
So, what we can see in the cache is just the part of a website that is written in plain HTML. By having a look at the source code we can also see that all the resources are served from the original URL. Therefore, in the case of the page being down, they are accessible to a limited extent.
What we don’t see at all (or at least we shouldn’t, based on what was said in the Hangouts) is the content generated by JavaScript. This is the case when you use highly popular frameworks such as Angular or React.
However, the latest experiment on how Google crawls JavaScript content by Bartosz Góralewicz and Kamil Grymuza shows that this is not entirely true. Their test page has content generated by Angular2 and it still shows up in Google Cache:
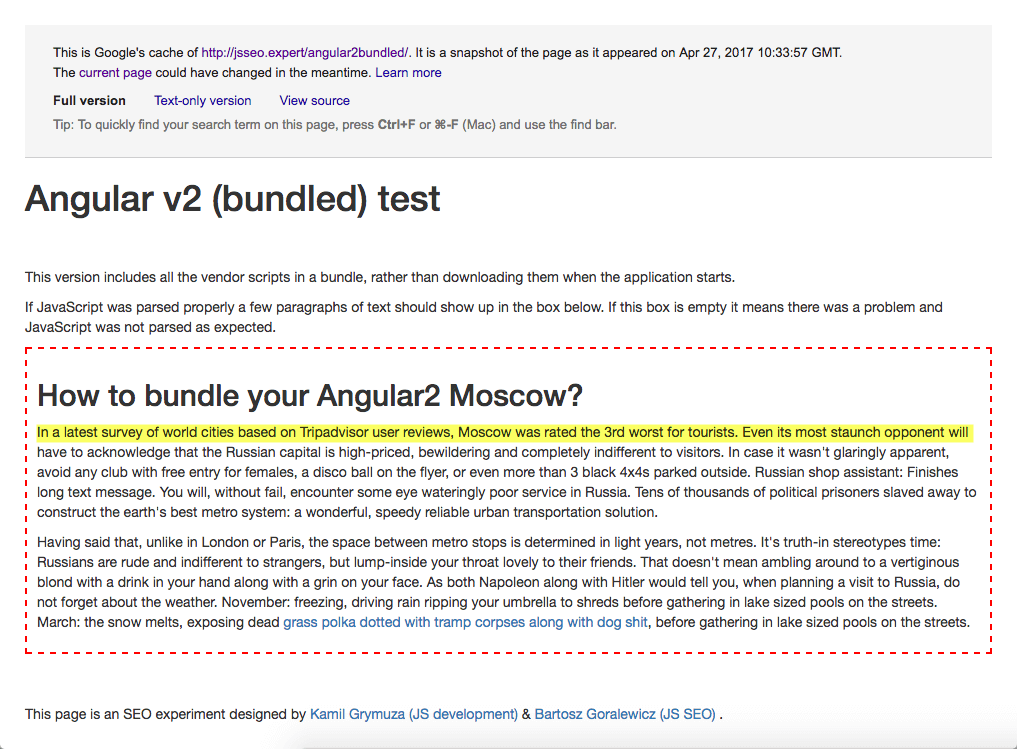
However, when you go to the text-only version of the cache, the content is gone:
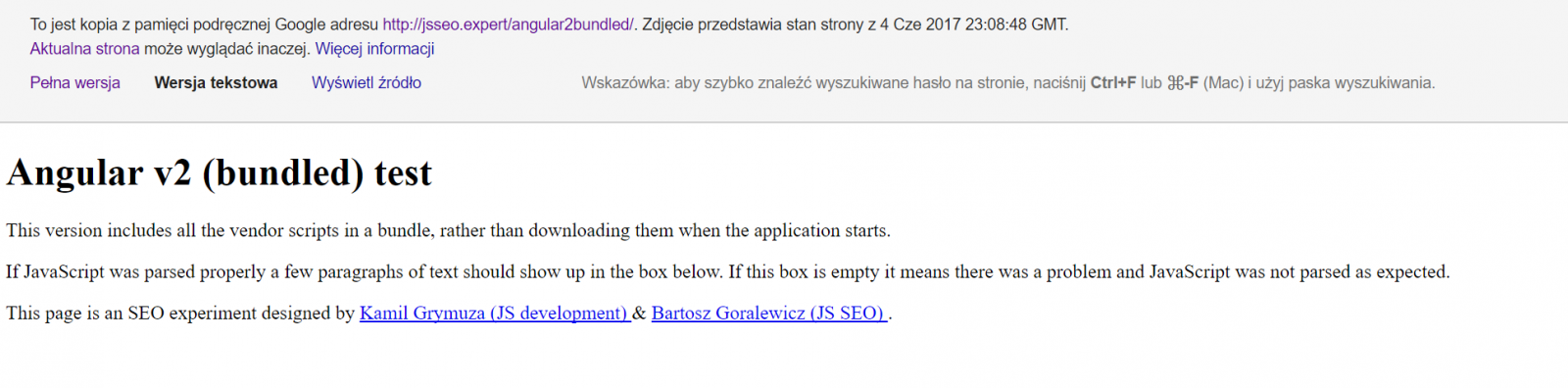
Reach out to us for Angular SEO services for better crawling, rendering, and indexing of your JavaScript content.Want to optimize your Angular usage?
How does Googlebot see my website?
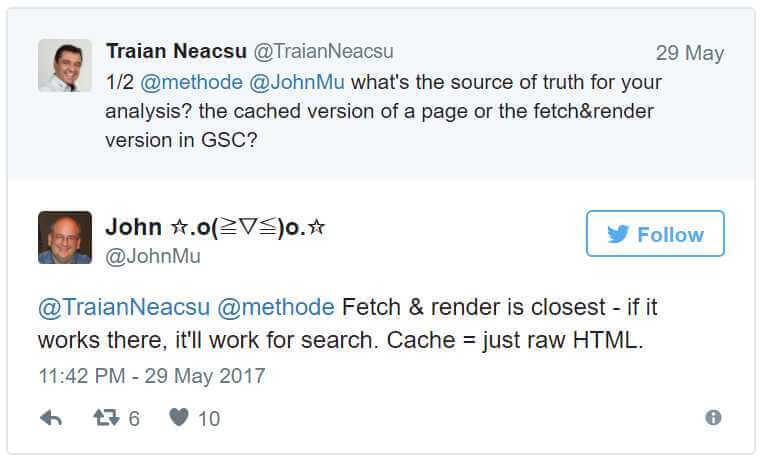
This is a frequently asked question and we can never be entirely sure. Generally, I think what we see in the text-only view should be indexed. To find out how Google sees the JavaScript-generated content, you should use the Fetch And Render tool in Google Search Console. According to John Mueller, this is the closest you can get:
You can have final confirmation of whether the content was indexed by using the following query:
site:example.com “This is an example fragment of the content I want to verify the indexation status for.”
If something shows up in the SERP, then you can be sure the content is properly seen by Googlebot.
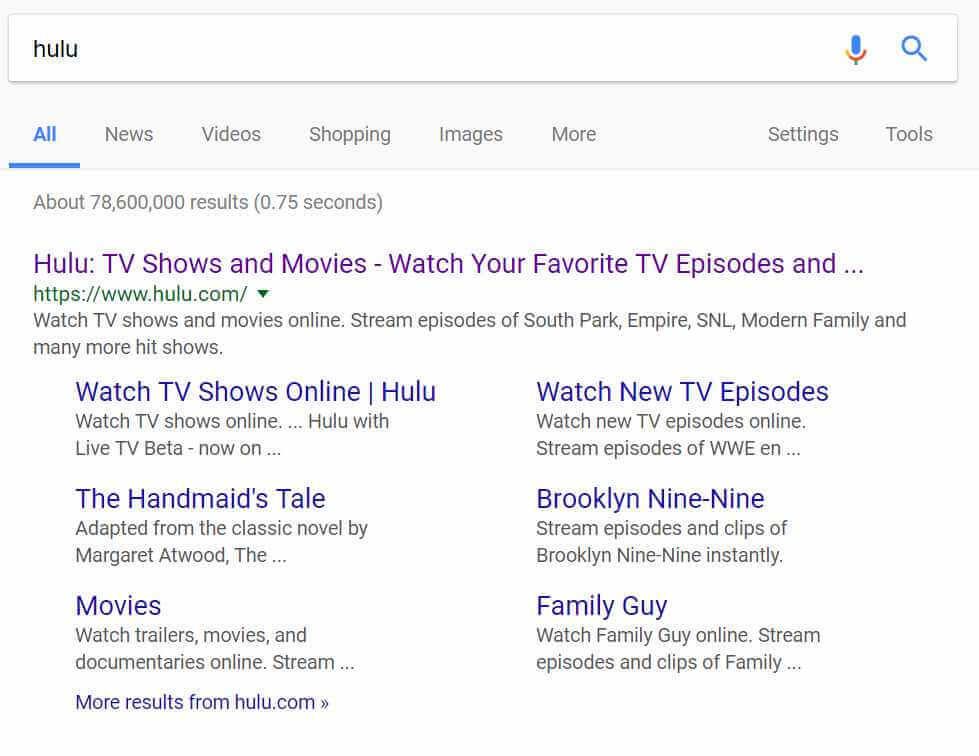
There are cases that prove that sometimes what you see in the cache is completely different from what will be indexed eventually. Let’s take a look at Hulu’s homepage in Google Cache:
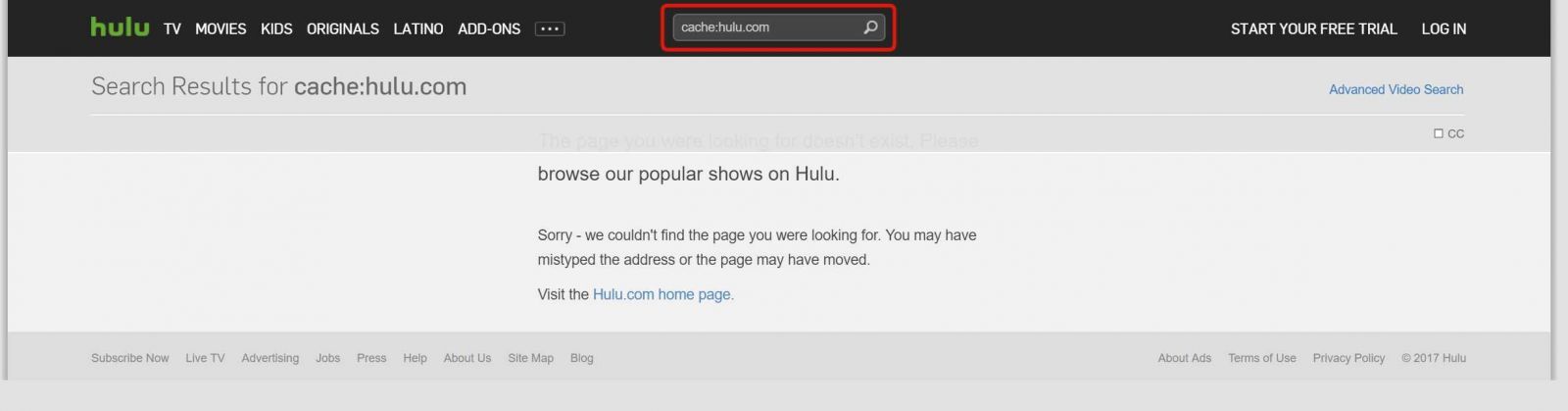
As you can see, the cache itself shows the search results for the query “cache:hulu.com”. At the same time, the result for “hulu” in Google looks nothing but normal:
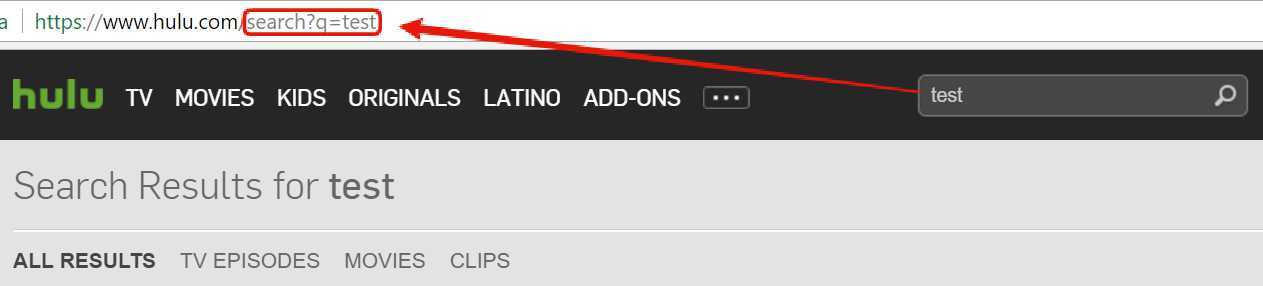
Here’s what probably happened. Hulu is using the same string in URL for internal search queries like the one generated in Google Cache:
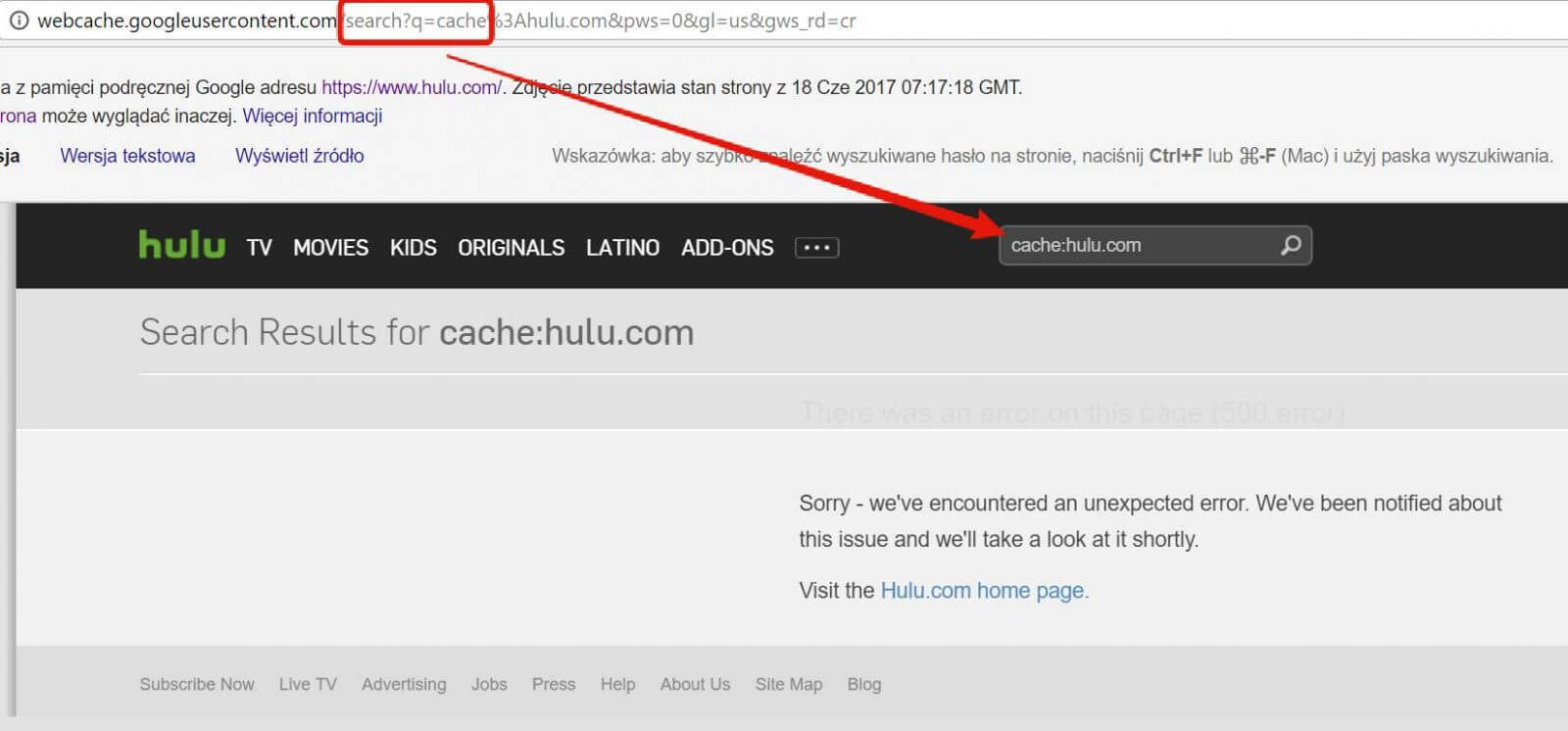
At some point (probably at the time of crawling), Hulu took that string and treated it as an attempt of making a search for something. This results in the page that we eventually see, which is drastically different from what is indexed. Hulu strongly relies on JavaScript, but I believe the same situation could happen on a plain HTML website as well because all search queries are served on the server-side. This leads to the conclusion that Google Cache is something you should treat rather as a curiosity, not as a serious SEO diagnostics tool.
As a follow-up reading on how Google sees your JavaScript-based content, take a look at our ultimate guide to JavaScript SEO.
What else can I use the cache for?
There is one more situation when you could find the cache helpful. It often happens that you need to see when a particular page was last visited by Googlebot, but you don’t necessarily have access to server logs. In the past, Google Cache showed a date of the last time the content of a page was successfully fetched. This means that if this page returned a 304 status code, telling Googlebot that the content hadn’t been updated, the date in the cache remained unchanged.
What many people might not know is that as of September 2006 Google Cache shows the date of the last time a page was visited (regardless if the content was fetched or not). Therefore, in this case, you can rely on the cache simply by taking a look at the heading:

Hope you found this article helpful. If you need more detailed guidance or advice for your website, you can use Onely’s technical SEO services.
TL;DR
Google Cache shows you a snapshot of a website constructed solely on what is served in plain HTML. The JavaScript-generated content is usually inaccessible there, which doesn’t necessarily mean it was not indexed. To see how Googlebot sees your website, use the Fetch And Render tool in GSC instead. You can make sure your content was indexed by making a search query using the site: operator and a fragment of this content. Google Cache is also a good place to go if you need to know when was the last time a particular page was visited by Googlebot.