JavaScript SEO is considered one of the most complicated fields of technical SEO. Fortunately, there is more and more data, case studies, and tools to make this a little bit easier, even for technical SEO rookies.
Why is crawling JavaScript complicated?
The answer to this question is somewhat complex and could just as well be a separate article. However, to simplify this topic, let’s just say that it is all about computing power. With HTML (PHP, CSS, etc.) based websites, crawlers can “see” the website’s content by analyzing the code.
With JavaScript and dynamic content-based websites, a crawler must read and analyze the Document Object Model (DOM). Such a website has to be fully rendered, too, after loading and processing all the code. The most straightforward tool we can use to see the rendered website is… a browser. This is why crawling JavaScript is often referred to as crawling using “headless browsers.”
Crawling JavaScript websites without rendering or reading DOM
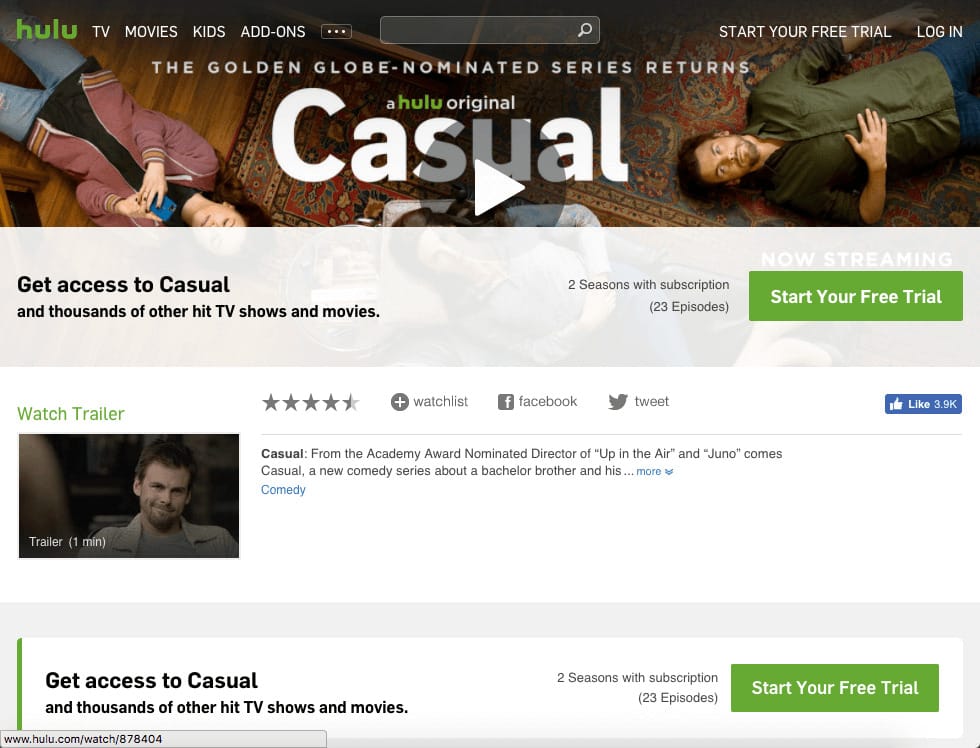
Before moving forward, let me show you an example of a JavaScript website that you all know: https://www.hulu.com/welcome. To make it even more specific, let’s have a look at the “Casual” TV show landing page – https://www.hulu.com/series/casual-22d27085-0f5e-42aa-949f-1b81ba5726d8.
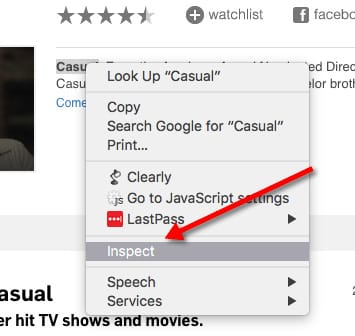
Here’s where it gets tricky. If you now use the right tools – e.g., the “Inspect code” feature in Google Chrome – you won’t see how it really appears. Instead, what you’ll see is DOM-processed & JavaScript Rendered code.
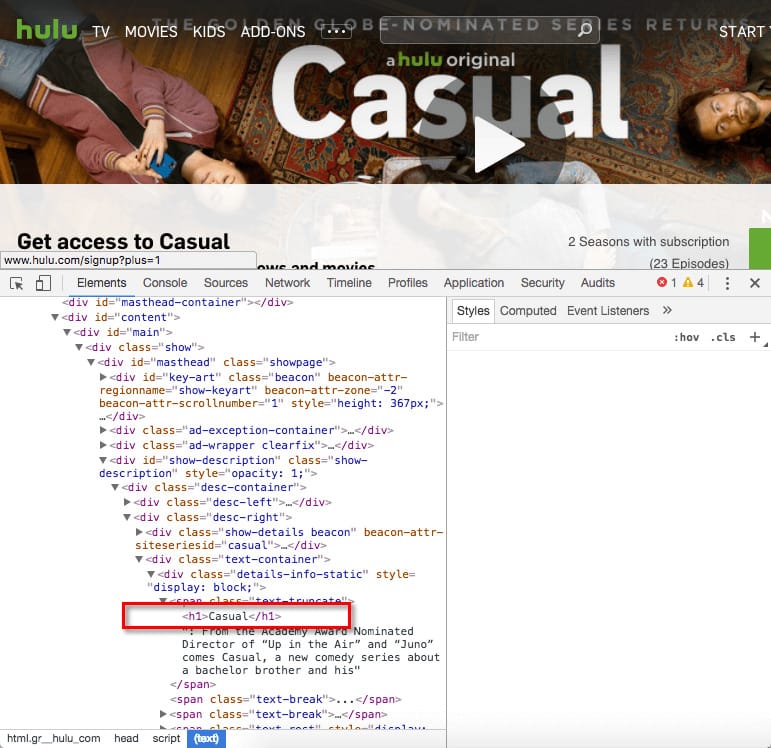
Basically, what you see above is code “processed” by the browser.
To see how the source code looked like before rendering, you need to use the “View Page Source” option.
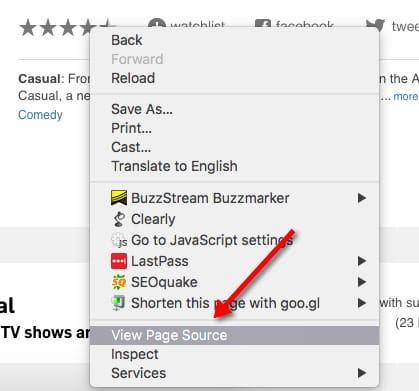
After doing so, you can quickly notice that all the content you saw on the page isn’t actually present within the code.
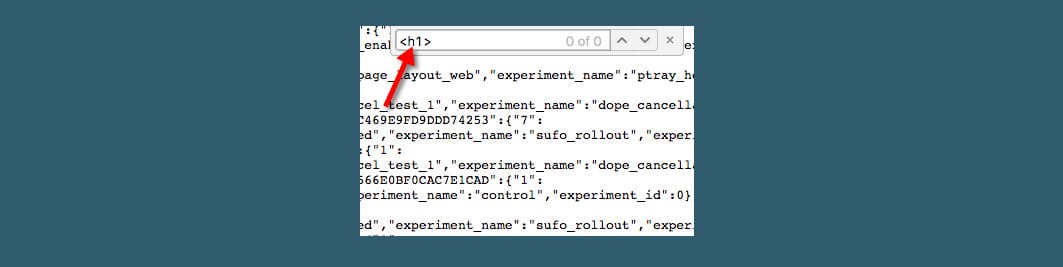
This is why crawling JavaScript websites without processing DOM, loading dynamic content, and rendering JavaScript is pointless.
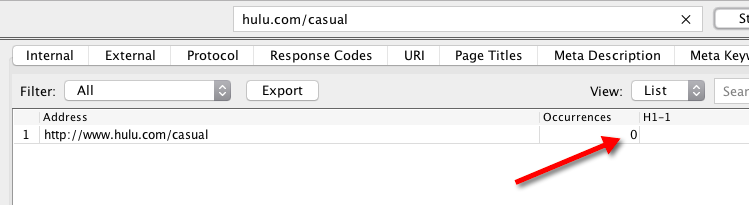
As you can see above, with JavaScript rendering disabled, crawlers can’t process a website’s code or content, and, therefore, the crawled data is useless.
Struggling with rendering issues? Contact us for Rendering SEO services to address any bottlenecks affecting your search visibility.
How to start crawling JavaScript?
The simplest possible way to start with JavaScript crawling is by using Screaming Frog SEO Spider. Few people know that, since version 6.0, Screaming Frog supports rendered crawling.
If you already have Screaming Frog installed on your computer, all you have to do is go to Configuration → Spider → Rendering and select JavaScript and enable “Rendered Page Screen Shots.”
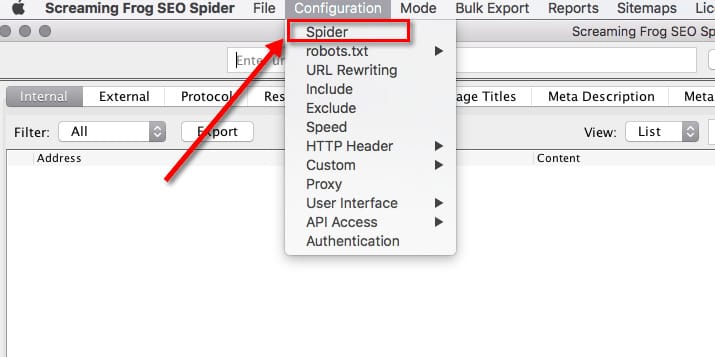
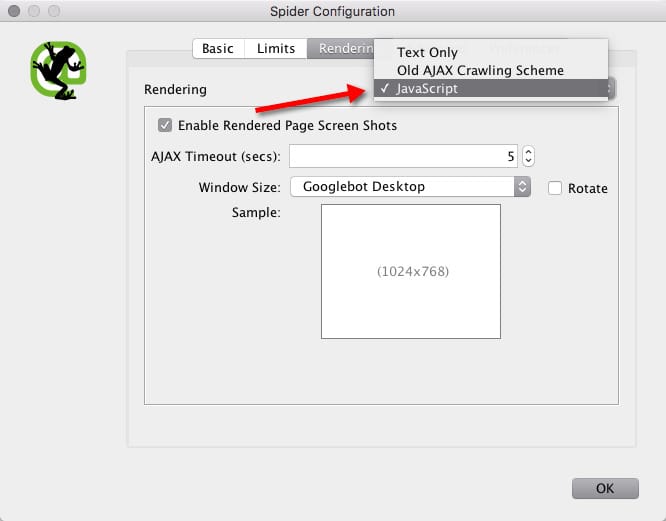
After setting this up, we can start crawling data and see each page rendered.
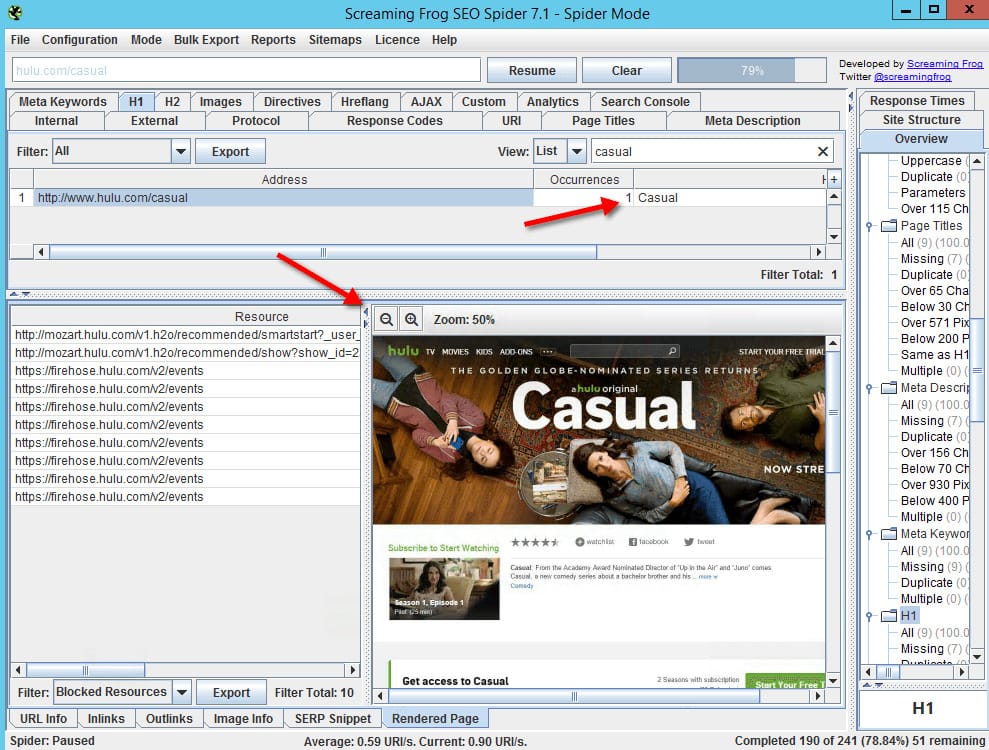
That’s – we are now successfully crawling JavaScript with Screaming Frog.
Word of warning
Please keep in mind that the data you get from Screaming Frog is basically how correctly rendered JavaScript should look like. However, Google doesn’t crawl JavaScript in the same way. This is why so many JS websites are investing in prerendering services.
Let me show you an example – as you saw above, Screaming Frog properly crawled and rendered this URL: https://www.hulu.com/series/casual-22d27085-0f5e-42aa-949f-1b81ba5726d8. However, this URL isn’t properly indexed by Google.
Here is proof. Google cache:
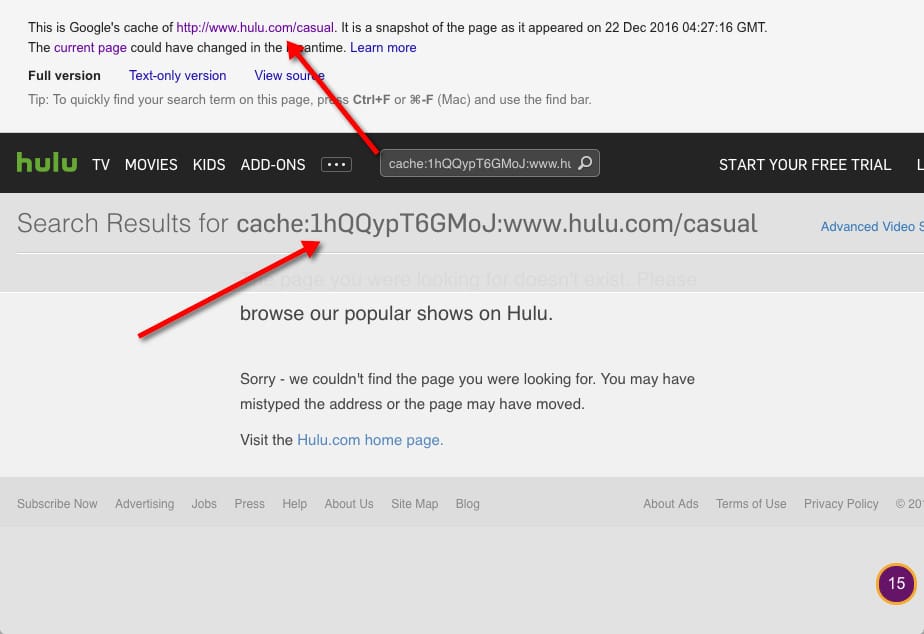
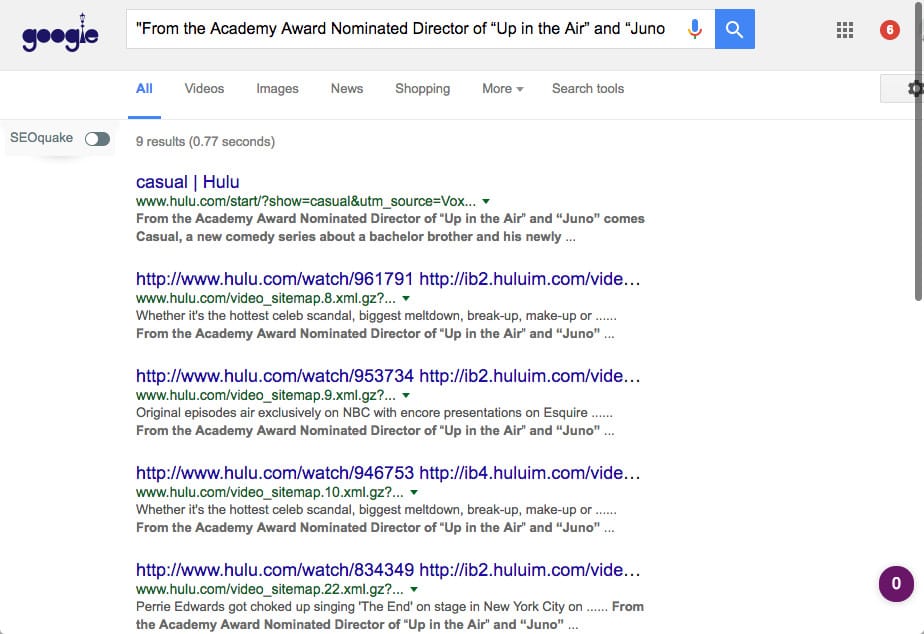
And – if you don’t believe that the screenshot above proves that Google isn’t always crawling JavaScript properly, let me show you one more example.
Let’s copy and paste content from the Casual TV show landing page:
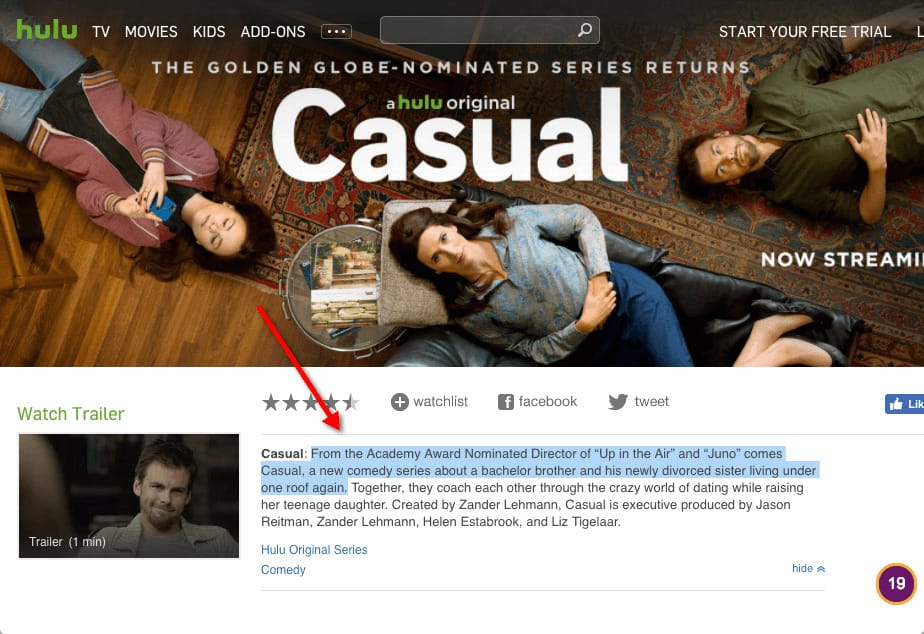
Unfortunately, content from this page isn’t indexed in Google.
Summary
JavaScript is here to stay, and we can expect more of JS in the upcoming years. JavaScript can get along with SEO and crawlers as long as it is consulted with SEOs in the early stages of designing your website’s architecture.
Feel free to contact us for JavaScript SEO services.

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!