
Search engines cannot discover and index every page on the web – they need to make choices in that regard. And, though all search engines serve the same purpose, they use different criteria for which pages to index.
That being said, it’s generally good if a search engine can crawl and index as much valuable content as possible – it increases the odds that it will show users what they’re looking for.
I was curious about which search engine – Bing or Google – indexes more content in general.
This article describes the different aspects of my research, and though I’d need more data to draw definite conclusions, I still managed to gather many unique and valuable insights.
Here is what I discovered about how Bing and Google index web pages.
Analyzing indexing data: methodology and results
Index Coverage of a random sample of WordPress sites
The first step of my research was to collect a sample of pages to check their indexing statistics.
I decided that a good starting point would be to use a sample of websites using the Yoast SEO WordPress plugin. There was a practical reason behind choosing this plugin: it divides sitemaps by sections, which would let me analyze which sections are indexed the most.
I found a list of websites that use the Yoast SEO plugin on builtwith.com, a site reporting on websites using given technologies or tools. I chose a random sample of 200 websites from a list of sites using Yoast SEO.
Then, I checked the indexing statistics of those websites using ZipTie.dev, and the data that came out is very interesting.
Bing indexed more web pages than Google.
Take a look at the charts below that show the indexing statistics for given sitemap categories:
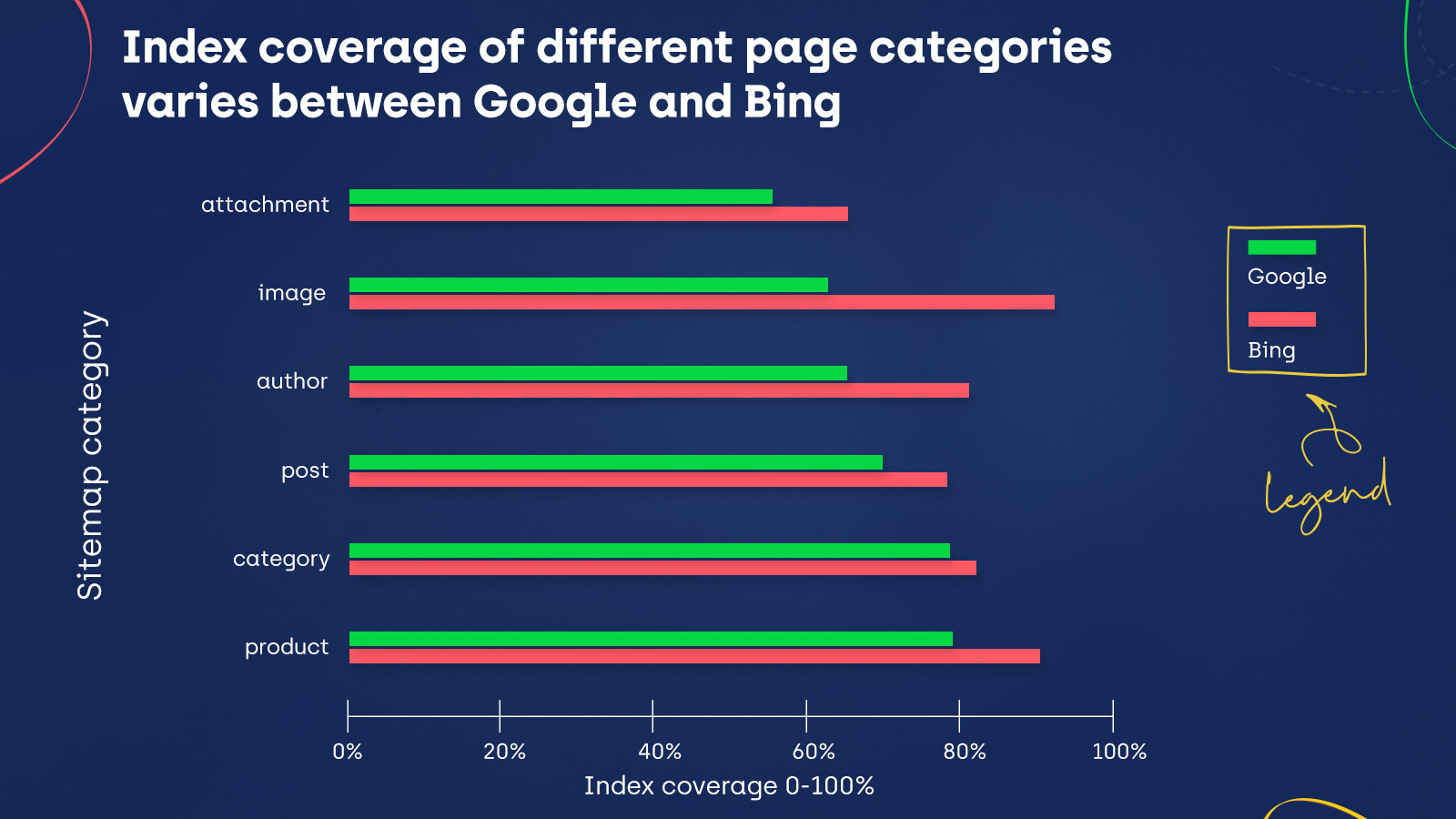
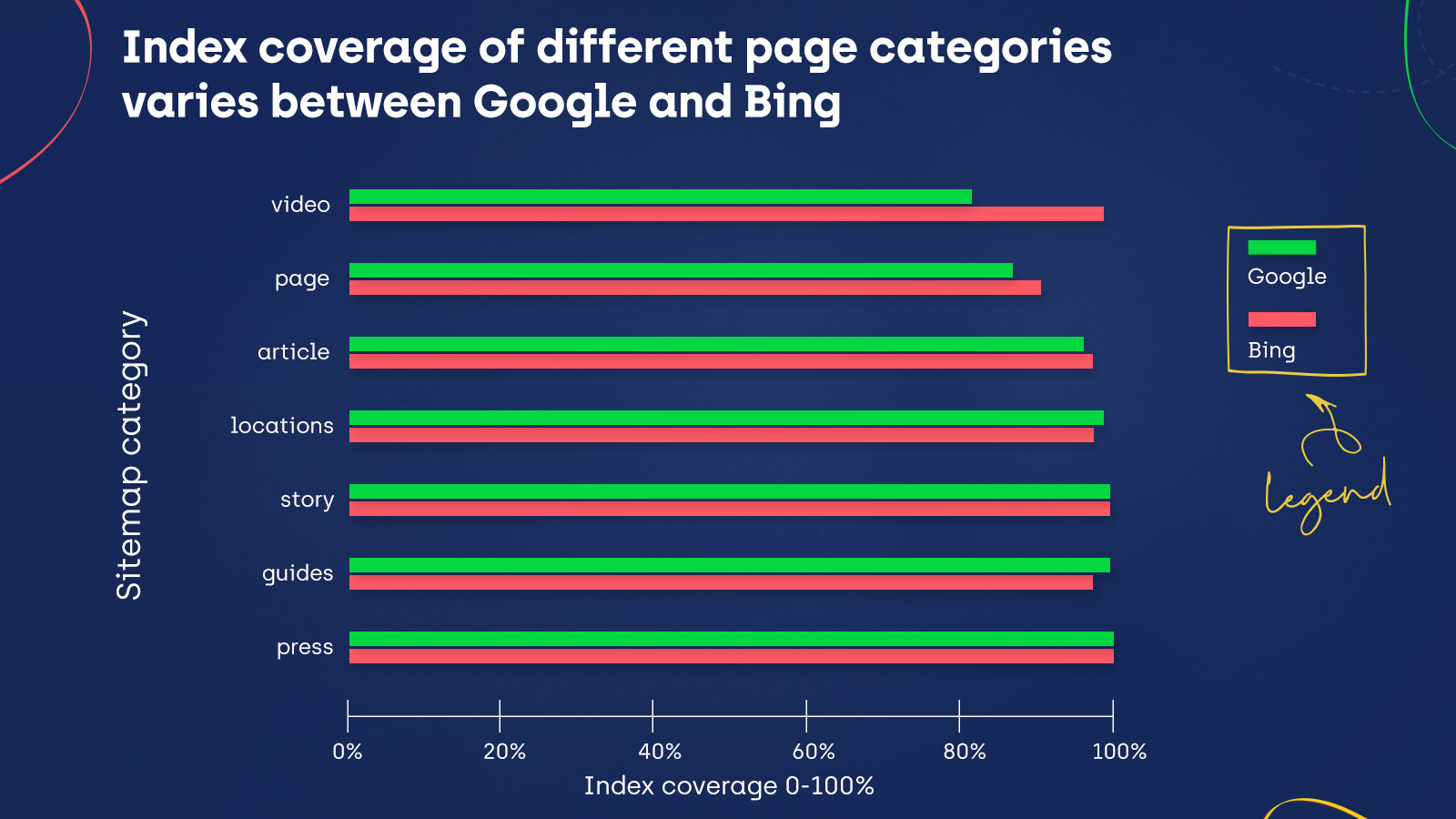
Index Coverage is the same for Bing and Google for the story and press categories. Moreover, Google did index more content in guides and locations. However, in all the remaining sitemap categories, Bing’s indexing exceeds Google’s – including important categories, like posts, products, and images.
But does this mean Bing is also able to crawl more pages than Google? Or do they crawl similar amounts of content but have different preferences when it comes to indexing?
Crawling data for a sample of our clients
To extend my findings, I checked the data for a few of our clients in both Bing Webmaster Tools and Google Search Console.
These tools show the pages that the respective search engine knows about for a given domain.
In Google Search Console, I looked at the All known pages appearing in the Index Coverage report and checked the number of URLs for all four statuses (Errors, Valid, Valid with Warnings, and Excluded).
In Bing Webmaster Tools, in the Site Explorer section, which contains indexing data for the pages on a given domain, I filtered the view to display All URLs.
This showed me all the discovered URLs for each domain I analyzed.
After comparing the data I got in both of these tools, I noticed that Google discovered more pages than Bing.
On the other hand (assuming these findings are consistent across both tested website samples), we already know that the pages discovered by Google and Bing are more likely to get indexed by Bing.
Keep in mind that these results are only for a small sample of sites and may not represent the whole web.
Index Coverage of a sample of popular sites
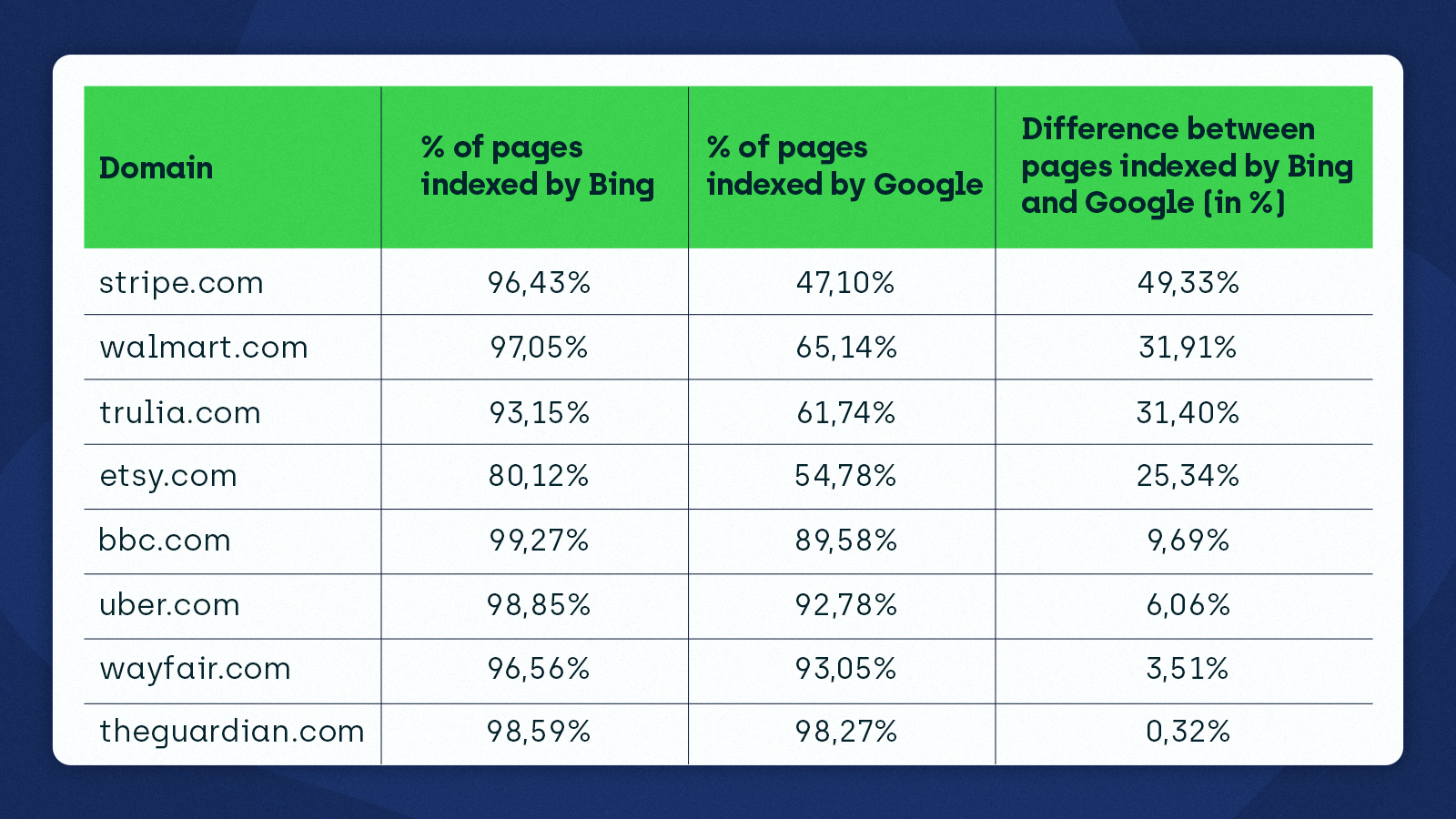
The third aspect of my research was to check the indexing status of a few popular websites using ZipTie to see how it varies between Bing and Google.
I learned that Bing is much more eager to index these sites than Google. This confirmed my earlier findings for the sample of WordPress websites using YoastSEO.
Take a look at the data I got:
Bing vs. Google indexing – initial observations
Can we tell that Bing is a better search engine based on the data?
Although Bing indexes more content, we cannot point out a single winner just by looking at the indexing statistics. We don’t know why Bing is indexing more than Google.
My hypothesis is that Google might be “pickier” than Bing. It’s no mystery that index selection is a thing.
We’ve been saying it for years – getting indexed by Google is becoming increasingly more difficult.
We also know that search engines crawl pages at different rates.
Here is what John Mueller said about how often Googlebot crawls pages:
I also found some interesting ideas in Bing’s documentation:
Bing may not want to go deep when crawling websites as doing so could provide little value and cause their KPIs to drop.
We know that Bing has been working on making crawling more efficient. For instance, Bing attempted to optimize the crawling of static content and identify patterns that would reduce the crawling frequency across many websites.
Also, consider the differences in how Google and Bing indexed the random WordPress websites – they were much smaller. In the case of very popular websites, they are much more significant.
This leads me to think that, in line with the fact that Bing openly admits they use user behavior data in their algorithms, Bing heavily prioritizes indexing websites that are popular, while for Google, popularity is less of a factor.
Introducing IndexNow
Recently, Bing took it a step further by adopting the IndexNow protocol. You can use IndexNow to inform Bing and Yandex about new or updated content.
Through our tests, we found out that Bing will typically start crawling a page between 5 seconds and 5 minutes from when it’s submitted using IndexNow.
We will continue to learn and improve at [a] larger scale and adjust crawl rates for sites implementing IndexNow. Our goal is to give each adopter the maximum benefit in terms of indexation, crawl load management and freshness of the content to searchers.
IndexNow allows websites to get their content indexed faster and use fewer resources for crawling. As a result, businesses can create a better experience for their customers by giving them access to the most relevant information.
We created a tool that will help you submit URLs or sitemaps to IndexNow even faster and easier.
Crucially, IndexNow is an opportunity for smaller search engines like Bing and Yandex to add to their indexes from an extensive database of content. IndexNow addresses the issue that search engines, including Google, struggle with today – having to crawl and render growing amounts of content.
Time will tell if Google adopts the IndexNow protocol or creates an alternative solution that will allow site owners to submit pages for indexing.
Optimizing how pages are crawled and indexed
Another takeaway from my indexing analysis is how important it is to simplify crawling and indexing for search engines.
First, you need to create and maintain sitemaps that include your valuable URLs. Sitemaps are helpful for Bing and Google for discovering the content they should index.
Search engines will struggle to pick up which pages are relevant and should be indexed if you fail to submit an optimized sitemap. For more details on setting up a sitemap and what pages to include, read our Ultimate Guide to XML Sitemaps.
Additionally, you need to have a robots.txt file containing correct directives for bots and properly implemented ‘noindex’ tags on pages that shouldn’t be indexed.
Wrapping up
To define a clear pattern in Bing’s and Google’s indexing, I would have to inspect many more websites, but there are certain ideas we can get from my samples of data:
- Bing indexes more content than Google.
- Google discovers more content than Bing, suggesting that Google is pickier with indexing. The guiding principle for Bing is to crawl less and focus on the content that has been added or updated.
- Bing prioritizes indexing of popular websites, while popularity is less of a factor for Google.
We can also see that content quality and optimizing your site’s crawling and indexing are vital aspects of Technical SEO, and they can’t be underestimated or neglected. Moreover, these factors will likely continue to be crucial as the web grows and search engine algorithms become more sophisticated.

Hi! I’m Bartosz, founder and Head of Innovation @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with your organic growth – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!







