
Since Google announced the availability of SGE in search labs, our R&D team has been diligently working to understand how this generative AI in search operates.
This research targeted one of the areas we aimed to explore.
Our questions were “What kind of content does SGE fetch to build its response?” and “Is SGE capable of fetching JS-dependent content?”.
Interested?
Continue reading to find the answers.
The purpose of research
The purpose of this research was to check what kind of content SGE fetches to build its response. Is it only content from the HTML body or is it a mix of JS-dependent and HTML body content?
We analyzed the type of content SGE retrieves by examining the text fragments linked to most responses. These fragments are designed to direct users to specific webpage sections but also indicate what part of the content SGE took to build the response.
What is a text fragment?
For those who don’t know what a text fragment is, here’s a quick explanation. Text fragments are used to shift users to specified parts of the webpage. In the following example from the image, the browser would shift users to the part of the content where the snippet:
|
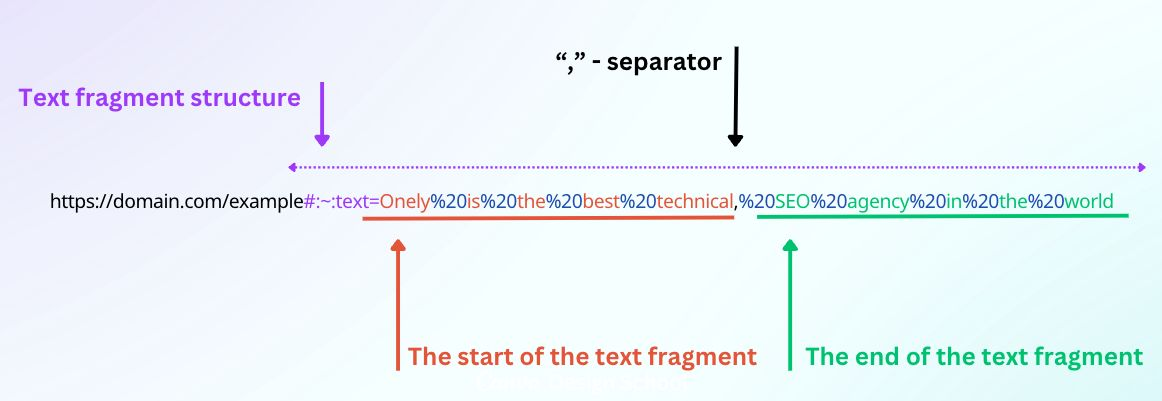
Research assumption
Initially, we thought that if we could not find the text fragment in the website source code, it meant the content needed JavaScript execution.
Our idea was mostly right.
However, during the research, we learned that the SGE can also find text fragments from different areas. This is important to address because my script wasn’t designed to search for text fragments different than HTML body content.
But don’t worry! Overall, this didn’t really change my findings.
Before we dive into finding, please get familiar with the data that we processed and analyzed.
Input data – an overview of what we analyzed.
To provide a concise overview, here is the key data we analyzed.
Our team created a list of 32 verticals, from which we extracted 35k keywords.
Below is a list of a few examples of verticals.
- Arts
- Banking
- Beauty
- Books
- Health
- Finances
- Real estate
- Technology
- Investing
- Online services
You can find the full list of verticals at the bottom of the article.
So, the big question was “What kind of content does SGE mainly fetch?”.
Our investigation aimed to clarify this.
From the selected verticals and keywords, I analyzed nearly 140,000 SGE sources featuring text fragments. My analysis indicates that 88% of text fragments were retrieved from the HTML body.
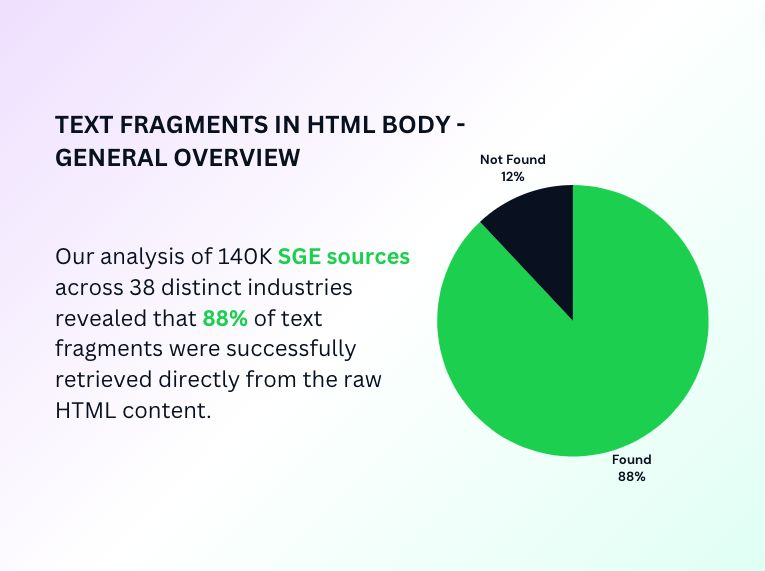
You might be curious about what the “Not found” segment contains.
Don’t worry; I have also taken a closer look at it.
What’s hiding under the “Not found” slice?
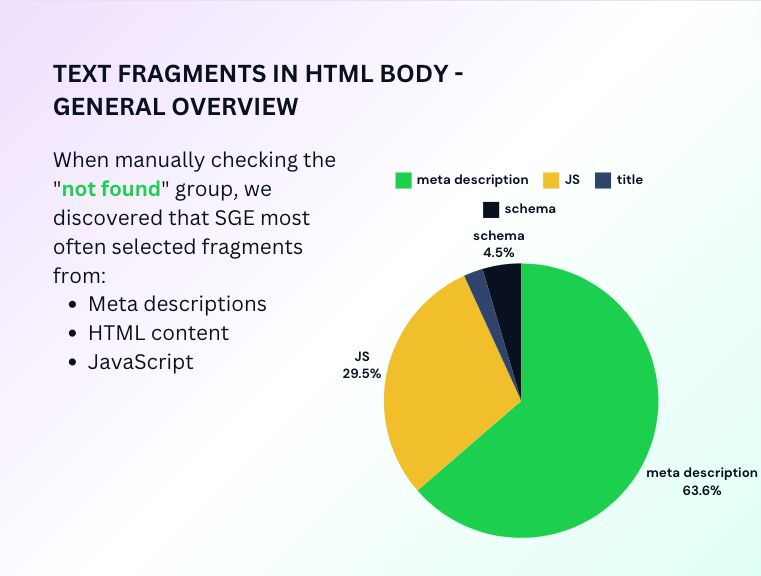
I conducted further manual analysis on the “Not found” segment, as we do not yet have a script capable of processing it in bulk, to discover what other content SGE selects for its responses beyond HTML, and the findings are quite intriguing.
Apart from HTML content, SGE is capable of utilizing fragments from the following areas:
- Description of the page – 64%
- JS-dependent content – 30%
- Schema markups – 5%
- Title – less than 1%
Based on these findings, I can estimate their overall contributions as follows:
- Description is around 7.5%
- JS-dependent content is around 3.5%
- Schema markups are less than 1%
- The titles are less than 1%
However, I want to make this clear: the research on the “Not found” category was conducted manually on a small sample. Therefore, the estimates may not be accurate or represent the true proportion of the “Not found” category.
Even if the average for all industries is 88% for content fetched from pure HTML in SGE responses, some of them may have a completely different share.
Analyzing all 32 verticals, we see that the disparity between the industry with the highest share of HTML content and the lowest can be up to 35%.
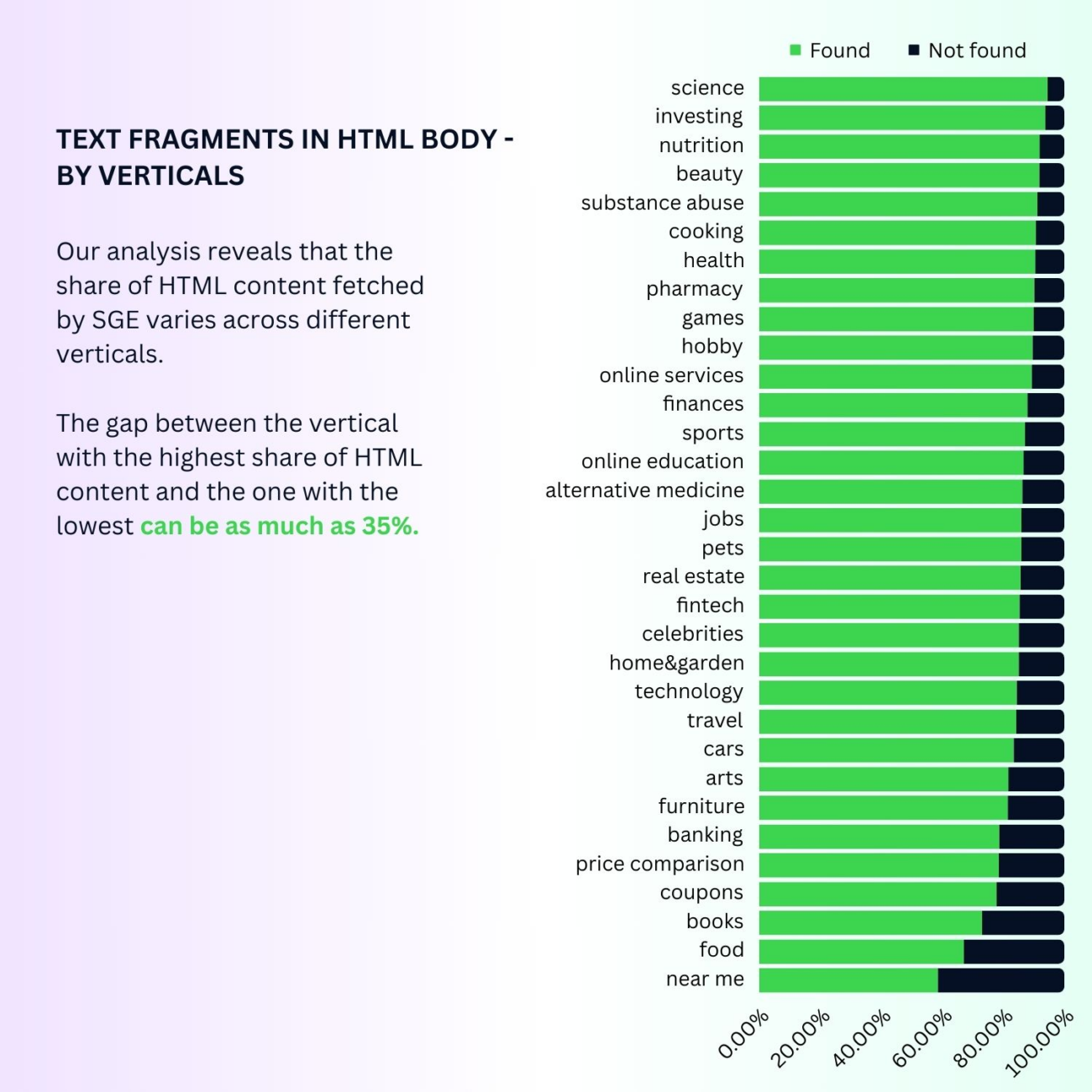
Why might there be so many differences between verticals?
It is really difficult to say at this stage. It might be because some of the verticals:
- Are time-sensitive like coupons – some of them during the scrape could not be available
- Others, like food, might have a higher share of schema markups (recipes).
For sure, it will be valuable to modify the script so we will also be able to check the elements of the title, description, JS, or schema markups and reestimate the share of JS-dependent content fetched by SGE.
What should you do next?
Although we’ve observed that SGE can handle JS-dependent content, we recommend the following steps:
- If your website relies on JS, identify which elements are most affected by it.
- Consider tools like ZipTie and WWJD that can help you with the analysis.
- Ensure Google can crawl, render, and index your main content without issues.
- Whenever possible, incorporate your main content directly into the HTML.
- Follow us to stay updated on SGE developments. 😉
Final thoughts
SGE is mostly building its response on HTML content, and from our point of view, it was something we expected.
Why?
Firstly, HTML content is less expensive compared to JavaScript.
One of our experiments demonstrates that Google requires 9 times more time to crawl pages with JavaScript-dependent content. More time means more resources that Google needs to use, or in the worst-case scenario, it results in no indexing in the SERPs and, consequently, no visibility in SGE. (https://www.onely.com/blog/google-needs-9x-more-time-to-crawl-js-than-html/)
Secondly, since SGE is still in development, its resources are likely more limited than they will be upon its official launch.
SGE utilizes a completely different algorithm to generate responses. For Google, this implies reallocating some of the available resources to support SGE’s functionality.
From Google’s perspective, if competing pages offer roughly the same value to users but differ in the cost of crawling and rendering, Google will opt for the more cost-effective option.
Why? SGE is still in the lab. Its resources are very limited.
Then, HTML content is cheaper compared to JavaScript, so it is easy to crawl, render, and index. We would be very surprised if SGE built its response based on content that depended on JavaScript – which is expensive.
Is SGE more likely to use HTML than JS?
We can not simply answer yes or no. It’s because we don’t know yet what the share of pages with high JS dependency was. We are working to answer this question.
Will the meta description become more significant once SGE goes live?
The description could play a role.
Our data indicates that it is the second primary source SGE utilizes to construct responses. I don’t want to claim it will become one of the main ranking factors to concentrate on. However, I do want to emphasize that it shouldn’t be overlooked.
Full list of verticals
- Arts
- Banking
- Alternative medicine
- Beauty – package 1
- Beauty – package 2
- Books
- Celebrities – package 1
- Celebrities – package 2
- Cooking
- Hobby
- Health
- Finances
- Furniture
- Home & Garden
- Games
- Coupons
- Food – package 1
- Food – package 2
- Fintech – package 1
- Fintech – package 2
- Cars
- Online education – package 1
- Online education – package 2
- Nutrition
- Near me – package 1
- Near me – package 2
- Jobs
- Real estate
- Travel
- Pharmacy
- Technology
- Investing
- Online services
- Pets
- Substance abuse
- Price comparison
- Sports
- Science

Hi! I’m Bartosz, founder and Head of Innovation @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with your organic growth – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!



