
Can Google crawl JavaScript content? Sure.
But does it crawl JavaScript content just like it does HTML? Not by a longshot. I just ran an experiment that demonstrates it.
The result: Google needed 9x more time to crawl JavaScript pages vs plain HTML pages.
This demonstrates the existence of a rendering queue within Google’s indexing pipeline, and shows how waiting in this queue can drastically affect how fast your content gets crawled and indexed.
And it’s one more reason to push as much of your content as possible into plain HTML.
The experiment
I wanted to check how long it would take Google to crawl a set of pages with JavaScript content vs regular HTML pages. If Google could only access a given page by following a JavaScript-injected internal link, then I could measure how long it took for Google to reach that page by looking at our server logs.
So together with Marcin Gorczyca, we created a subdomain with two folders. Each folder had a set of pages like this one:

The copy was generated by AI.
One of the folders (/html/) contained pages built only with HTML. Meaning Googlebot could follow the internal link to the next page (in the case above, “Ostriches”) without fetching additional resources or rendering anything.
At the same, the /js/ folder contained pages which loaded all their content using vanilla JavaScript (without using any JavaScript frameworks). So until Google fetched an additional JavaScript script file (which was used across all pages in the folder) and rendered those pages by executing the JavaScript, it would see a mostly blank page:

After rendering JavaScript, Google would discover AI-generated copy, similar (but different!) to the copy in the /html/ folder, as well as an internal link, just like with the HTML pages.
In both folders, there were a total of seven pages, six of them only accessible via those internal links.
We pinged Google about the existence of the first page in each folder, and we then waited for all pages to get crawled.
Results
It took Google 313 hours to get to the final, seventh page of the JavaScript folder.
With HTML, it took just 36 hours. That’s nearly 9 times faster.
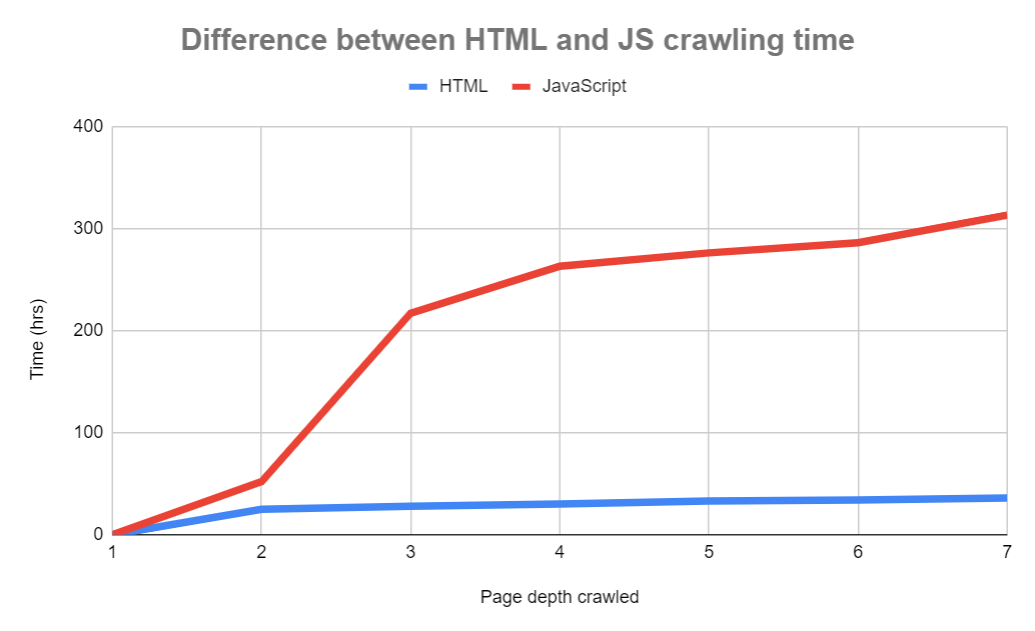
The delay varied depending on how deep Googlebot got into the experimental pages, but it was always substantial. Even with the first JavaScript-injected internal link, it took Googlebot twice as long to follow it as opposed to the HTML link (52 hours vs 25 hours). As it got deeper into the folders, the delay got more extreme.

Takeaways
To be honest, I didn’t expect the results to be that different for JavaScript and HTML.
In 2019, I wrote an article responding to Google’s claims that the delay between crawling and rendering is 5 seconds on median. But back then, our research at Onely mainly focused on the delay between content getting published and getting indexed.
In this simple experiment, we measured something different. Essentially, we measured how long it took for Googlebot to follow a link in content loaded with JavaScript versus a link in regular HTML content.
So now we know there’s a very significant difference. But the question remains: why?
Normally, crawl budget would be a possible explaining factor. Every additional file needed to render a page is an additional request that Googlebot needs to make, which contributes towards your crawl budget. As Erik Hendriks from Google said during WMConf 2019, “crawl volume is gonna go up by 20 times when I start rendering.”
But in the case of our experiment, there was just one JavaScript file that was needed for rendering across all pages. Google only requested that file when crawling the first and second pages inside the /js/ folder. It doesn’t seem reasonable that this one additional request would cause Google to take 9x longer to crawl the /js/ folder.
Going back to my ancient article about the rendering delay, Martin Splitt said the following during the November 2019 Chrome Developer Summit:
If this is in fact true, then it would mean the following happened with my experiment (let’s talk about Googlebot getting from the second to the third page in the /js/ folder, just to make the example clear):
- The second page was crawled.
- 5 seconds later (at median — let’s make it one hour!) the second page was rendered and Google found the link to the third page.
- The third page was crawled after waiting in the crawl queue for 164 hours.
At the same time, the third page in the /html/ folder got crawled three hours after the second page was discovered. After 165 hours, it’s been 129 hours since Googlebot discovered the final, seventh page in that folder!
One might conclude that Google gives less priority to crawling pages that are linked with JavaScript-injected links. But this makes zero sense — why would Google give less priority to crawling links which were already discovered anyway?
So to me, there is just one explanation left
Rendering queue
There’s a significant delay between a page being crawled and being rendered, and that’s why it took Google so long to discover and crawl consecutive pages in the /js/ folder.
As rendering takes additional computing resources, pages that require rendering have to wait in a rendering queue in addition to the crawl queue which applies to all pages.
Of course, Google may assign higher rendering priority to popular pages, and the delay may not be always so significant. But before you assume this isn’t an issue for you, run an experiment on your website and check how much time your pages spend in the rendering queue.
Here is my main takeaway: the rendering queue is very real and can significantly slow down Googlebot’s discovery process on your website. Especially for websites that push out tons of content and need it indexed quickly, like news sites, this is a critical issue.
If you’re using JavaScript to generate ANY content, it’s probably better to render it all server-side. We’ve known it for years, but this experiment is just one more argument for choosing server-side rendering for the sake of JavaScript SEO.







