PageRank was an algorithm initially developed by Google’s founders, Larry Page and Sergey Brin over 20 years ago. It was the core of Google’s ranking system. PageRank measures a webpage’s importance by evaluating the number and quality of links leading to the page. The original formula of PageRank has evolved over the years and is no longer available to the public. As we read in the Guide to Google Search ranking systems, “it has evolved a lot since then, and it continues to be part of our core ranking systems” which makes it clear PageRank is still used and plays an important role in how Google ranks websites.
PageRank’s initial purpose was to help Google generate highly relevant search results compared to the alternative search engines of the time by employing an additional, innovative factor.
Why is PageRank crucial for SEO?
The original idea of Larry Page and Sergey Brin was to create an algorithm that would see links as votes that pages cast for each other, expressing trust and endorsement. According to this logic, the more links a given web page gets from other web pages, the more important it is deemed — pages with a higher PageRank score are considered more useful for web users and should appear higher on Google’s search results page.
While it’s far from the only ranking factor that Google uses, it’s definitely an important one.
PageRank is a recursive algorithm — the value assigned to links from a given page depends on the number and quality of links that a given page itself has received. Therefore links from reputable sites pass more PageRank value.
However, if a given page links to many other pages, those pages will only receive a fraction of a given page’s authority due to PageRank dilution. Links on a page share the value of that page’s PageRank between them. The more links there are on a page, the less value each of them can pass.
These features of the algorithm have two consequences when it comes to SEO.
- It pays to get your content linked by other reputable websites.
- The number of links on your pages may be a strategic choice.
Nowadays, Googlers rarely discuss PageRank, but it’s hard to imagine Google without it. PageRank helped Google conquer the web and tremendously impacted the SEO industry.
History of PageRank
Over the last two decades, Google has reaped the benefits of using PageRank while having to fight various methods of abusing it by website owners simultaneously.
Learning the history of PageRank is not only absorbing but also offers a helpful context for planning a coherent SEO campaign.
Larry Page and Sergey Brin introduced PageRank in 1998 in their patent titled “The anatomy of a large-scale hypertextual Web search engine.” The patent described their idea for an innovative search engine called Google and explained how it would produce more relevant results than competing systems. The authors claimed that the exceptional accuracy of Google Search would result from using PageRank — being able to rank pages based on links exchanged between them.
The following years showed that PageRank was indeed a breakthrough, and not just for search engines.
John Mueller, Google’s Search Advocate, said on Twitter that PageRank is currently used in biology, neuroscience, chemistry, and physics.
Search engine dilemmas before PageRank
Let’s take a quick trip back in time to when PageRank was first created.
The web of the time was smaller than today, but it grew more chaotic with each passing day. The first website appeared in 1991; three years later, almost 2,800 websites were live. In 1998, when PageRank was born, the Internet grew to over 2 410 000 pages.
If you got hungry back in 1998 and wanted to find a recipe for a quick spaghetti sauce among those 2.4 million pages, you could use the help of fledgling search engines, such as AltaVista.
Back then, search engines trying to find the fastest and tastiest recipe for spaghetti sauce were primarily guided by keywords. The more a given page mentioned spaghetti sauce, the more they thought it should rank high. This led website owners to stuff their pages with keywords in order to rank higher and attract more search traffic. So instead of the most satisfactory result, you would likely get the most keyword-stuffed one.
An alternative solution was to search for a recipe in a human-made web directory, such as Yahoo Directory. These indices were curated, which meant people manually ranked their search results. The hungry searcher could count on more accurate, verified results using a human-curated index. But as the web grew, it became clear that humans won’t keep up with the pace. There were simply too many websites for anyone to keep track of manually.
The solution
It became apparent that only fully automated information retrieval systems could go through the ever-expanding web quickly enough. The problem was that computers couldn’t understand and evaluate web content as well as humans. The algorithms needed new metrics beyond keywords.
People decided that links were fit for being such metrics and started experimenting with the hypertextual nature of the Internet. They rightly assumed that pages linking to a given page provide additional information about the content of that page. Some hints needed by the algorithms were contained in anchor text. Besides, pages on similar topics would link to each other more extensively.
PageRank’s authors drew on this idea and went a step further. They decided to use links to measure the importance of pages. They thought that authoritative sites could pass their authority on to pages they link to, and then the search engine would be able not only to identify the most appropriate results but also to rank them in terms of usability.
PageRank original formula
So, how would one go about measuring the importance of a given web page? That’s where PageRank comes into play.
Meet Joe, the random surfer
The easiest way to understand how PageRank works is to imagine a surfer randomly following the links between pages. Let’s call him Joe and assume he has a vast appetite for spaghetti.
Hunger drove Joe to a blog about Italian cuisine, which links to a recipe for bolognese sauce and a recipe for carbonara sauce.
The carbonara page refers to a completely different pizza site.
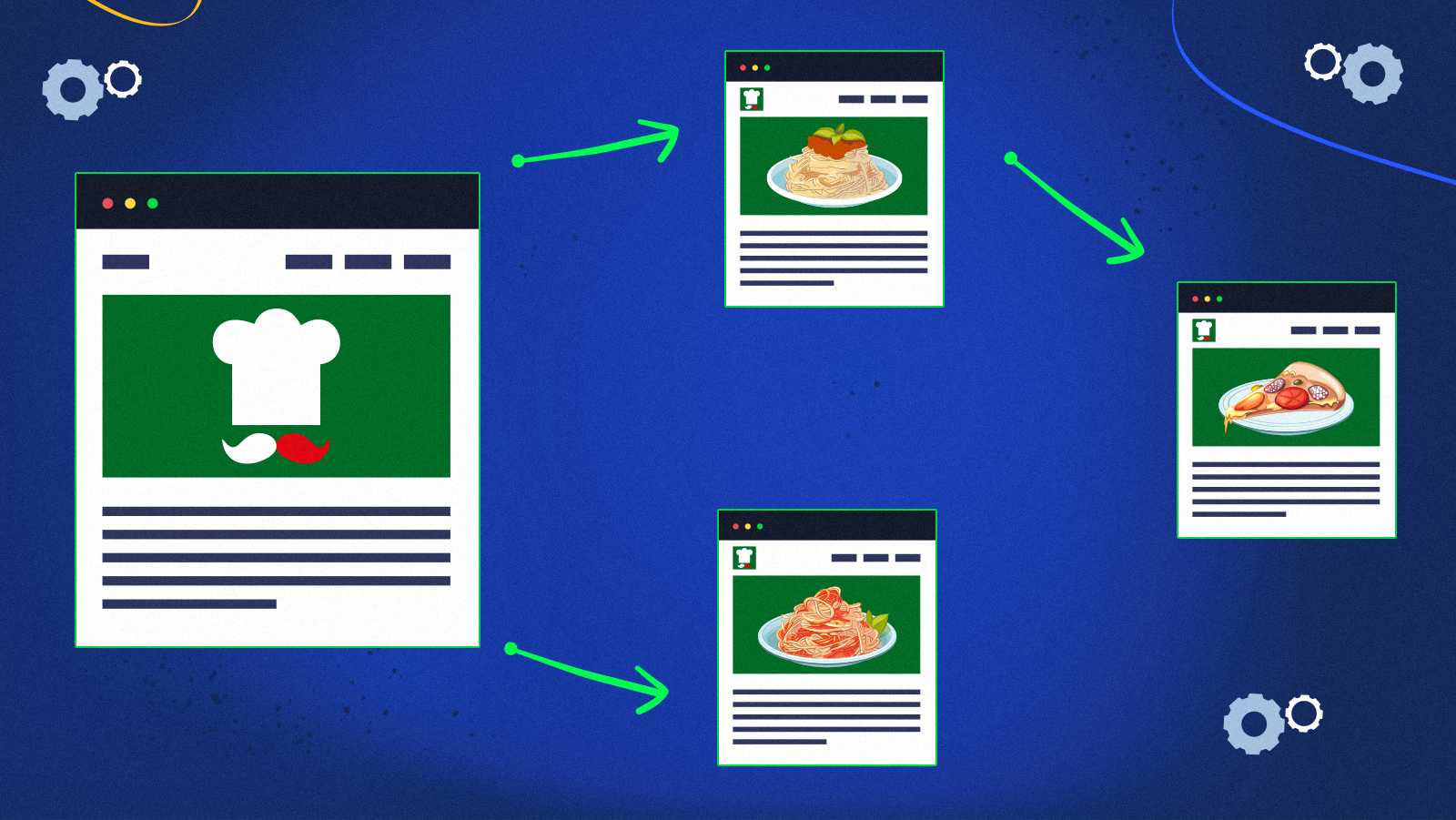
The pizza page links to the blog Joe started with and an already familiar carbonara recipe.
Beginning at the bolognese page, Joe can jump to the pizza page or the carbonara page.
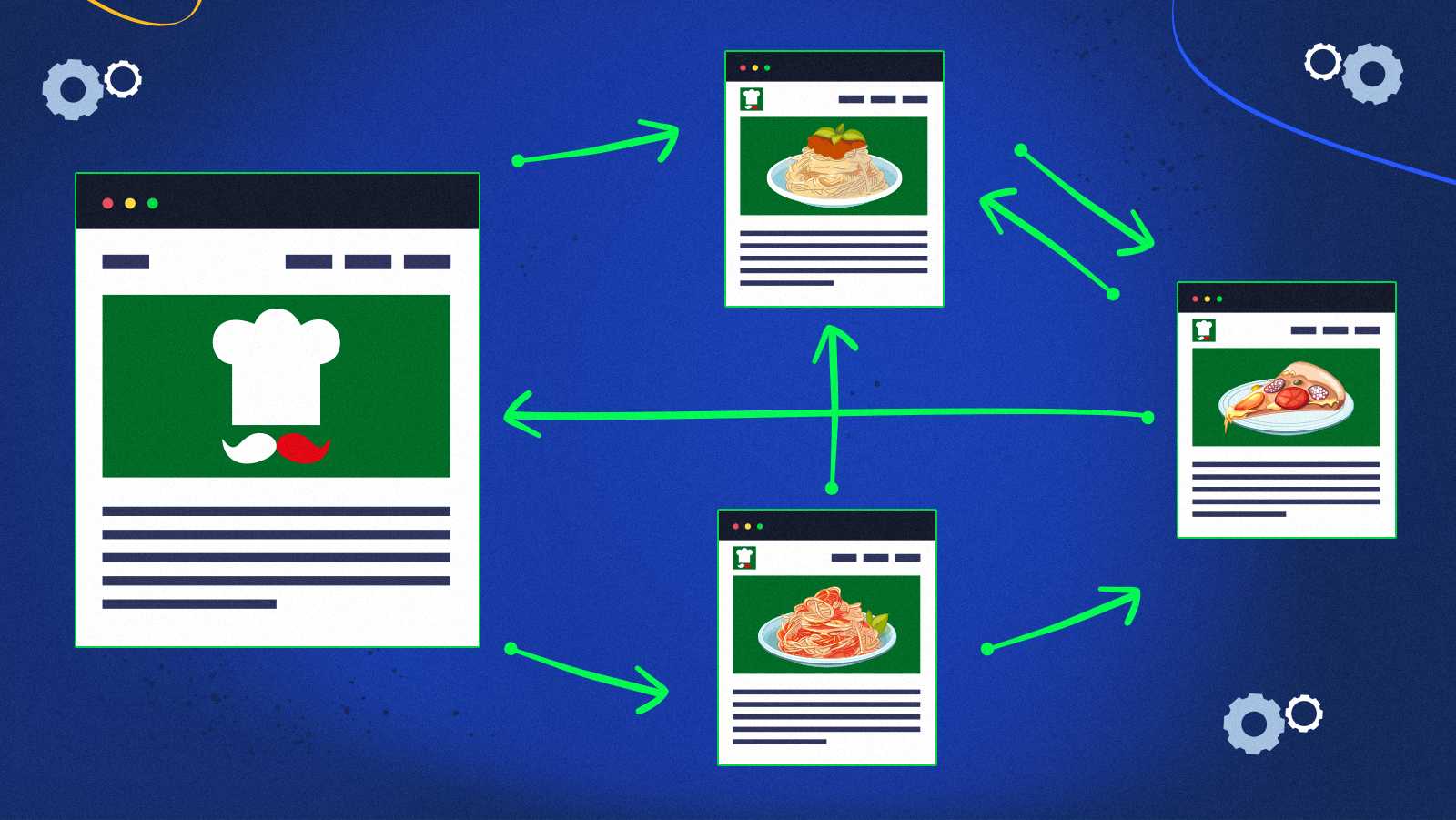
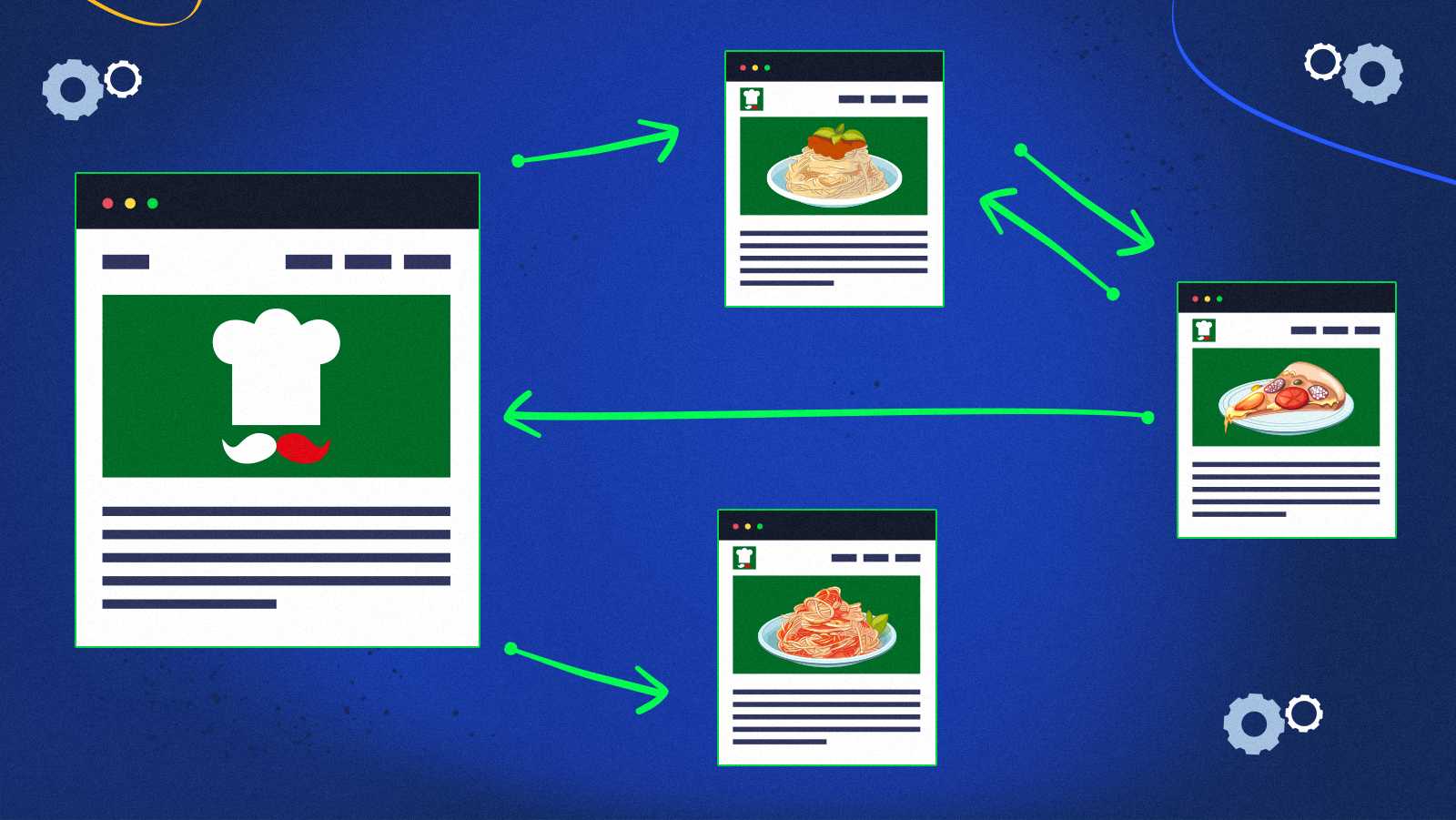
Joe is a very hesitant person. He clicks endlessly between these four pages.
Interestingly, this makes the probability of visiting each of these pages change.
When Joe reads the blog (let’s assume it’s a one-page blog), there is a 50% chance he’ll open the bolognese recipe and a 50% chance he’ll open the carbonara recipe. However, when he is on the spaghetti carbonara site, he has no choice but to move to the pizza site. Then he can jump back to the carbonara recipe or back to the blog and repeat the cycle. The probability for both of these options is 50%.
For Joe to get to a spaghetti bolognese website with the first click, two things must be true. First, there is a 25% chance that he will start browsing from the blog, and then there is a 50% chance that he will click the proper link.
When we multiply these probabilities, we find there is a 12.5% chance that Joe will read the recipe for bolognese sauce after the first click. For comparison, the possibility that Joe’ll end up on a website about carbonara sauce after the first click is 37.5%.
PageRank recursivity
We can roughly predict how much time Joe will spend on each of the four pages. On the second round of clicks, Joe’s odds of starting up on different sites are no longer 25%, but they vary. By multiplying the numbers many times, we notice that links from frequently recommended pages increase the likelihood of going to the page linked by them.
This is called PageRank recursivity, and it’s why sites with a high PageRank score pass more of the PageRank score to other sites, so links from them are valued in SEO.
PageRank dilution
The Random Surfer model is also a great illustration of PageRank dilution. The page with the carbonara recipe had the most authority in the example provided above. It linked only to the pizza recipe page, allowing the pizza recipe page to get the whole PageRank value because the random surfer had no choice but to move there.
However, if the carbonara page contained two additional links, the pizza page would receive one-third of the initial PageRank value. There would then be a one to three chance that a random surfer would use a link to the pizza page.
Damping factor
Of course, the random surfer described in the Google patent cannot get stuck on four pages that link to each other because their job is to measure the importance of websites across the whole Internet.
So let’s imagine that the indecisive Joe hesitates whether he would prefer to eat a Chinese dish. If he decides to save eating pasta for tomorrow, he’ll completely abandon his browsing journey. Following this scenario helps us understand the damping factor: the chance that Joe’ll keep following the link structure instead of abandoning the given four pages and browsing a different web corner.
In the original patent, Larry Page and Sergey Brin suggested using a damping factor of 0.85, meaning that with every visited page, there’s a probability of 85% that the random surfer will continue clicking links on the page and not entirely abandon the process.
PageRank mathematical formula
We can present everything described above as a single mathematical formula for calculating PageRank. In its simplest form, if the web only contained four pages, it would look like this:
PR(A) = \frac{PR(B)}{L(B)} + \frac{PR(C)}{L(C)} + \frac{PR(D)}{L(D)}where PR(B) stands for the PageRank score of page B, and L(B) stands for the total number of links on page B.
The equation states that the PageRank of page A is equal to the sum of PageRank scores of pages B, C, and D, each divided by the number of links originating from these pages.
But to get a complete picture of how the algorithm works, we also need to consider the damping factor d.
PR(A) = \frac{1-d}{N} + d \left( \frac{PR(B)}{L(B)} + \frac{PR(C)}{L(C)} + \frac{PR(D)}{L(D)} \right)The letter N represents the number of documents in the given collection. In this scenario, N equals four.
If you’re interested in more advanced transformations of the PageRank formula, check out the Wikipedia article about PageRank.
What was the PageRank toolbar, and why was it removed?
PageRank became everyone’s obsession in 2000 when Google introduced a toolbar installable in the browser. One of Google Toolbar’s features was displaying PageRank. Its developers described it as follows: “Wondering whether a new website is worth your time? Use the Toolbar’s PageRank to know how Google assesses the importance of the page you’re viewing.”
The highest PageRank a page could get on the toolbar was 10. Zero meant that a page was utterly unworthy of trust and attention.
Admittedly, this number was easy to understand and track, and many SEOs focused on improving it as a key success metric for all websites.
This turned out to be terrible for the quality of content on the web. Instead of making better, more useful websites, people focused on building as many links as possible to improve their PageRank scores. Needless to say, most of those links weren’t created to help users — their purpose was to trick Google.
Googlers themselves tried to convince web admins to focus on other metrics but with little success. Although PageRank was constantly recomputed, Google rarely updated the values displayed by the toolbar. Googlers admitted they wanted to avoid people getting even more obsessed with PageRank scores.
When attempts to change the web admins’ manners turned out unsuccessful, Google finally noticed that the PageRank display was doing more harm and good. The toolbar’s PageRank display was last updated in December 2013, and three years later, the feature disappeared entirely.
Important PageRank updates
PageRank wasn’t ideal in its original form. With time, it became evident that it needed improvement and safeguards against those trying to manipulate it.
Google was also becoming more and more discreet about PageRank’s role in ranking search results. Eventually, an ex-employee of Google revealed that the company was no longer using the original PageRank patent since 2006. These steps could have been motivated by how much the whole SEO industry was focused on manipulating PageRank. However, the ex-employee also pointed out that the new algorithm is significantly faster to compute, and the sole reason for this change could have been a need for more efficiency.
We may never know how the original PageRank formula evolved and how it’s used in search ranking now. However, we can infer two critical changes from two patents filed in 2004 and 2006.
Meet Joelle, the reasonable surfer
In a patent filed in June 2004, “Ranking documents based on user behavior and/or feature data, “Google described the Reasonable Surfer Model.
Why did the random surfer need to become reasonable? One of the initial model’s elements was the assumption that the surfer had the same probability of clicking on each link on a given page. It meant that each link carried the same amount of PageRank value.
Of course, this premise didn’t quite reflect the reality.
Imagine a woman named Joelle who wants to impress her friends by making a homemade pizza. She’s browsing the web and viewing many recipes. When a page links to other suggested recipes, she’s randomly viewing them as well.
Still, at the moment, she is unlikely to be interested in the culinary portal’s privacy policy. She also doesn’t need to buy pots for growing basil. The chance she will click on any of these links is tiny.
The patent states:
Joelle is indecisive and chaotic, but she’s reasonable. How can the algorithm successfully imitate her behavior? It must consider, for example, the link’s position on the website. The size and color of the anchor text may also hint if Joelle would be interested in clicking. If the anchor text sounds too commercial, she’ll feel discouraged from visiting the site. If someone listed the link among others, Joelle is likelier to click on links with higher positions in that list.
The goal was to differentiate the weight passed by links according to their features. These important attributes are listed in the patent:
Seed Sites – what are they, and how do they affect PageRank?
Another important idea that likely influenced the PageRank formula was to realize that it’s possible to choose a set of pages that are trustworthy by definition.
It is unlikely, for example, that government-owned sites will link to blogs explaining how to cheat the tax system. It’s also possible to identify a few reputable newspapers whose journalists do qualitative research and don’t refer to unverified information.
According to a 2006 patent titled “Producing a ranking for pages using distances in a Web-link graph,” these types of websites are “seed sites.” Two examples listed in the document are The Google Directory and The New York Times. These pages are preselected, and we can then assume that pages they link directly to should have higher PageRank.
But what about pages linked by sites that are directly linked by seed sites? Selected seed sites don’t recognize them, but we can still be sure that a site that won the New York Times’ trust will not include junk links in its articles. It’s wise for the ranking algorithm to calculate the distance between a given page and one of the chosen seed sites.
Picture a website of an imaginary Italian Cuisine Enthusiasts Association. Due to its reputation, employing professional authors, and high-quality content, Google can consider it a seed site.
For the sake of simplicity, suppose there are only two pages with a spaghetti bolognese recipe on the whole Internet. When you’re hungry and looking for a recipe for this dish, Google may have a dilemma about which one to display first. So it’ll check how close they are to the famous website of the Italian Cuisine Enthusiasts Association. The page two links away from the seed site should rank higher than the page seven links away from a trusted source.
Outdated SEO practices to increase PageRank
As we mentioned before, website owners and SEO developed a colossal ambition to get the highest PageRank score. The algorithm influenced their position in the search results and testified to the website’s prestige. Some SEOs used to refer to the value of PageRank that the pages passed to each other as “link juice.” And everyone wanted to squeeze it to the last drop.

To the contentment of many, the original algorithm was easy to manipulate. People who took shortcuts and didn’t shy away from unfair practices successfully generated loads of traffic to their low-quality sites. Having more links was enough to boost any website’s visibility. Where those links came from didn’t matter after all.
Google had to learn some lessons from its mistakes to prevent the Internet from turning into a massive link farm. The breakthrough came when it developed automatic ways to catch and punish websites that broke the rules.
What are link schemes?
Imagine running a blog about Chinese cuisine. As you create posts and share your knowledge, it may be helpful to recommend other sources to readers. Sometimes you link to another blog on the subject or promote engaging culinary workshops that you’ll go to yourself.
Those kinds of links are called “natural.” Including them in your post will make the information complete and more valuable. You decide to make them out of a desire to create a good blog, not to raise someone’s PageRank.
However, not everyone on the web is as well-intentioned as you are. People regularly post out-of-context links without any benefits for users. Their goal is to raise the number of backlinks pointing to a site they want to rank higher in search results. These useless backlinks tend to be purchased, automatically generated, or forced on contractors.
Such actions relying on posting unnatural links and attempting to manipulate PageRank are called link schemes. Let’s discuss them in more detail.
Buying and selling links
In the past, selling links by high-ranking domains was prevalent. This type of practice abused the principle that links from pages with a high PageRank score significantly increase the PageRank score of a linked site. Google caught The Washington Post selling links in 2007 and the BBC in 2013. As a penalty, their websites’ PageRank scores got manually lowered, and they lost many visitors in the following months.
Google once even had to punish its own product. In 2012, Google Chrome’s official website was using purchased blog posts for promotion. The penalty dropped the domain’s PageRank, and the first search results page no longer displayed Chrome’s pages for the “browser” query.
Google doesn’t reveal whether the manual penalty for sites selling links is always a reduction of their PageRank, but press reports on Google’s manual actions from the early 2010s suggest that’s what it consisted of.
Back when we could see the PageRank score in the toolbar, it wasn’t just the algorithmic calculation result but also an expression of Google’s opinion about a given portal. And Google couldn’t trust a website caught selling unnatural links as much as it did before.
Google’s former head of the web spam team, Matt Cutts, mentions the issue of manual PageRank demotion in a video on YouTube.
Selling and buying links didn’t always involve money. It used to happen that two unrelated pages agreed to link to each other on an exchange. Moreover, some entrepreneurs decided to send others “free” products in return for attaching a link to their store’s website. Some businesspeople made linking to their site a condition of using their company’s services. They usually didn’t allow the contractors to opt out of this part of the deal.
Spam comments
Another sad occurrence was posting spam comments on the web. Suppose someone noticed that your blog about Chinese cuisine has a high PageRank and then posted a comment under one of your posts with a link to their carbonara recipe, even though it’s not interesting for your readers. Such action certainly doesn’t stimulate a productive discussion on your blog and only serves to unnaturally raise the ranking of a different page.
Link farms
Internet users from a few years ago could also observe link farms springing up like mushrooms. Link farms are groups of websites that all link to each other to increase their rankings. Earlier, we talked about how PageRank simulates the behavior of a random surfer and how it would work on four culinary pages that link to each other. What if the same author created all these pages, and their sole intention was to increase the PageRank of one of them?
Imagine that said author didn’t make these additional pages a source of independent information but only to give a random surfer a better chance of visiting the site with the carbonara recipe. Their attitude doesn’t support the building of reliable and satisfactory content on the web and doesn’t correspond to the goals of Google.
Most link farms weren’t created by human hands but rather by automated programs being able to fill servers with hundreds of new junk pages every day. Link farms should be viewed as a very negative phenomenon as they fill the web with spam.
What is the Penguin update, and how does it fight dishonest SEO?
In April 2012, there was a new Google update announced. Despite the friendly codename — “Penguin” — it aimed to fiercely combat web admins who manipulated PageRank. Google programmed the Penguin algorithm to look for unnatural links and impose a penalty on sites that benefited from them.
After Penguin’s release, many web admins were surprised to discover a sudden breakdown in their website’s ranking. They had to go through a tedious cleanup of backlinks to regain their lost PageRank score. They often had to send e-mail requests to remove unnatural links to their sites, and Google appreciated meticulously documenting those actions.
When it was impossible to contact the website with the unwanted link, the way to proceed was to disavow it by submitting an appropriate request to Google.
Take advantage of link risk management to reevaluate your backlink strategy.Need help with disavowing spammy backlinks?
The Penguin algorithm was updated seven times and became part of Google’s core infrastructure. Since it was introduced, link farms or buying links can only harm the website’s visibility — at least in the long run. Although link spam continues today, its effectiveness has significantly dropped thanks to this measure. Each of us can help Penguin in guarding the quality of search results. If you observe unnatural linking, you can use this Google Form to report link schemes.
PageRank in modern-day SEO
PageRank has come a long way since it was first introduced. The algorithm had to outsmart link schemes and learn to differentiate between various types of links. Its exact role in ranking search results remains a secret.
So what should you understand about PageRank to build better SEO strategies?
Does Google still use PageRank?
PageRank started as an algorithm measuring how much time a random surfer would spend on your site. Over time, it likely learned to take into account the location and anchor text of links and differentiate the probability of the surfer following them. The algorithm also had to become resistant to manipulation and start recognizing seed sites that were by definition trustworthy.
All these significant PageRank changes and the fact that its original patent was abandoned in 2006 at the latest can lead you to think Google may no longer use this algorithm. But Google didn’t forget about the solution that made it so successful in the first place.
This tweet from John Mueller about PageRank may serve as proof that Google still uses its renowned algorithm. Google Webmaster Trends Analyst Gary Illyes also confirmed on Twitter that PageRank is still important in ranking.
Principles of healthy link-building
Today, you can no longer use the PageRank bar and see your website’s PageRank score. However, its hidden value is still fundamental to search visibility and can be increased.
You certainly shouldn’t pay for links in order to improve PageRank. It strictly violates Google’s guidelines and is bound to hurt your rankings in the long term.
Instead, you should focus on two things:
- Creating quality content that naturally acquires qualitative backlinks to improve the external PageRank flow to your domain.
- Making sure your content is internally connected and fit for distributing internal PageRank on your site properly.
Qualitative backlinks
Imagine you started a blog about Chinese cuisine. How can you improve the ranking of this page when sponsored links can’t pass you any PageRank without breaking Google guidelines? That’s where digital PR comes into play. While traditional PR focuses on increasing brand recognition using traditional media such as the press, digital PR concentrates on online methods.
You can contact bloggers or journalists and propose to them to write about a project you run on your blog, within which you send out surveys to dietitians and publish your findings on the health benefits of eating Chinese dishes. Content creators are unlikely to be interested just in your website’s existence since it’s one of the thousands of blogs about Chinese cuisine, but you can get them intrigued with your research.
If you are persistent, you can get featured in some news and articles, and with them, you’ll gain natural, valuable backlinks.
Internal linking
We can’t ignore internal linking in the PageRank discussion. Internal links serve two essential purposes:
- They affect the individual rankings.
- They help browsers navigate your site.
How individual pages on your website link to each other is critical because, without correct connections, they may never get discovered by Google. For example, creating so-called orphan pages with no internal links pointing at them is a huge mistake.
Our article on these issues can help you learn how to fix internal linking problems. You can also contact Onely for internal linking optimization.
PageRank vs. subdomains and subfolders
Interestingly, one of the predominant questions you may want to ask yourself in optimizing your PageRank is the dilemma between creating subdomains or subfolders for your website. Imagine, for example, your blog about Chinese cuisine has a version for novice chefs and an expert version.
The widely accepted theory states that Google may see the expert version subdomain as a separate website from your blog (and any links between them as external links) while interpreting links between the blog and its expert version subfolder as internal linking.
Many prominent SEO experts like Barry Adams claim that a higher damping factor will burden the links to the subdomain. Your blog will therefore pass them less PageRank while passing more PageRank to its subfolders. However, it’s worth noting that people base this conjecture on a somewhat outdated understanding of the algorithm, which may not always behave in such a predictable manner.
How to avoid breaking Google Webmaster Guidelines?
PageRank aims to help search engine users find quality content from trusted sites. Backlinks can measure this trust only when they are natural; that is, they refer to pages useful in the context of users’ search.
Selling links as an attempt to manipulate the PageRank exposes the website to a penalty imposed by Google, which will reduce its ranking and visibility. Following the 2012 Penguin update, Google algorithms automatically detect and penalize such practices.
Now you may be wondering how so many websites maintain ads among their content without compromising their visibility. The secret is that Google won’t consider your commercial links unnatural or fraudulent if they’re appropriately tagged.
Google appreciates it when you openly explain the relationship between your website and the link. To avoid accidental breaches of guidelines, you may use link attributes, which are hidden pieces of text describing each link in HTML code.
Nofollow tag
The nofollow tag is the oldest way to tell Google not to pass any PageRank to the linked page. SEOs compare the PageRank value to link juice that can be “poured” from one site to another. They could say that if your website were a glass of link juice that’s pouring through the link holes, the nofollow tag would be a slice of tape keeping the liquid inside the glass.
This metaphor is obviously imperfect because linking to another page won’t make you lose any PageRank. But you can still use the nofollow tag to prevent passing authority to pages you don’t want to endorse.
The nofollow tag should be used inside the <a> HTML element as such:
<a href=”http://www.example.com”rel=”nofollow”>Some Anchor Text</a>
In September 2019, Google announced two new rel attributes designed to stop the PageRank flow. You can put them into HTML the same way as nofollow tags. Here’s what they look like and what they do in comparison to the nofollow attribute:
| Nofollow tag | Sponsored tag | UGC tag |
| rel=” nofollow” | rel=” sponsored” | rel=” ugc” |
| Marks links to sites you don’t want to pass any PageRank to for whatever reason. | Marks links resulting from a paid advertisement or endorsement. | Marks links posted by your website’s users that might be spam, and you don’t want to take responsibility for them. |
Google indicated that it isn’t necessary to change the existing nofollow tags to more specific UGC or sponsored tags but recommended using them in the future. It’s also possible to use more than one rel attribute to mark a single link.
At the same time, as stated in the announcement, from now on, the described tags will no longer serve as an absolute PageRank blocker but rather as hints for Googlebot. However, their use is still required if you don’t want your site to be penalized for unnatural linking.
PageRank and redirects
Sometimes, you may need to move your website or page to a different address. Surely you’d like its PageRank to be retained. Fortunately, using a 301 redirect will help you achieve precisely this effect.
People have many doubts about how Google treats 302 redirects regarding PageRank. Due to the fear of losing PageRank, web admins often give up using those redirects. In one of the SEO Office Hours meetings, John Mueller confirmed that concerns around 302 redirects are unfounded. The 302 redirect allows the original address to retain the whole PageRank value.
A participant of a different SEO Office Hours meeting asked another interesting question whether the number of followers or likes increases the PageRank passed by the social media profile. We found out then that Google doesn’t consider social media activity with regard to PageRank. Even if the search engine treats a social media profile as a regular webpage, the number of likes it has will not affect the PageRank passed.
Measuring PageRank
Since Google Toolbar isn’t available anymore and Google no longer uses the original PageRank formula, there aren’t any methods you can use to measure PageRank for your web pages or even to see its approximation.
However, it’s still helpful to analyze your website’s link profile, and for that, you need an alternative metric. There are several metrics that are popular in the SEO industry that attempt to simulate PageRank. Although Google doesn’t use any of them for ranking web pages, metrics like DA and DR are correlated with Google rankings. So using them can be useful when auditing your website.
Page Authority and Domain Authority
Page Authority and Domain Authority are metrics developed by Moz to illustrate a page’s or a domain’s ranking potential. PA and DA range from 0 to 100 on a logarithmic scale, making it easier to improve them from 20 to 30 points than from 60 to 70 points. To calculate Page and Domain Authority, Moz uses data from the Mozscape web index and machine learning algorithms.
If you’re a fan of old-school and creative solutions, you can read our article on how to check Domain Authority with Scrapebox and use this controversial tool for White Hat SEO purposes.
Trust Flow and Citation Flow
Trust Flow and Citation Flow by Majestic assess a website’s authority based on its backlink profile. Citation Flow shows how many links point to your website, while Trust Flow focuses on the quality of those links.
Trust Flow grows when popular and reputable websites link to your page and will always score lower than Citation Flow, which considers all links no matter their status.
Domain Rating
Domain Rating is a metric developed by Ahrefs. It’s calculated on a logarithmic scale of 0 to 100. Domain Rating is based on backlinks Ahrefs found pointing to your site without nofollow tags.
Ahrefs designed it to measure the authority of entire websites, not individual pages.
Key takeaways
- PageRank is an algorithm that helps Google evaluate the popularity and credibility of websites. It allows Google to surface more relevant content in search results. By assessing the number of links on pages and their quality, PageRank estimates how much time a random surfer would spend on them.
- By getting your website linked to other reputable domains, you increase your PageRank score and your chances of ranking high.
- For every page within your domain to rank high, you should also take care of proper internal linking to improve your internal PageRank flow.
- Google penalizes attempts to manipulate PageRank with unnatural links. Remember to correctly mark your links with nofollow, sponsored, and UGC tags to avoid traffic loss.

Hi! I’m Bartosz, founder and Head of Innovation @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with your organic growth – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!