Most SEOs are focused on the Google Search Console chart showing their website’s crawl budget. You know the one I’m talking about, right?
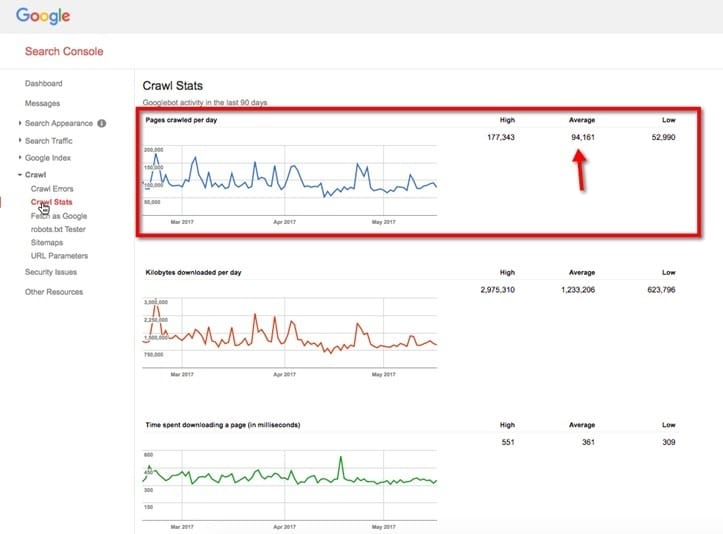
This chart provides data used to measure the crawl rate of a website. Unfortunately, what most people don’t realize is that this view often only covers between 10% to 30% of a domain’s crawling data.
To understand this better, let’s have a look at what is essential for Googlebot to crawl your website.
Let me show you an example.
A huge discrepancy
Go to Zalando.co.uk and enter Chrome Developer Tools (Ctrl + Shift + I or F12 on Windows) or (Cmd + Opt + I for Mac). Once you are in Chrome Developer Tools, go to “Network.”
Now, if you look at the “Domain” tab, you can see that not all of the content there is served from www.zalando.co.uk.
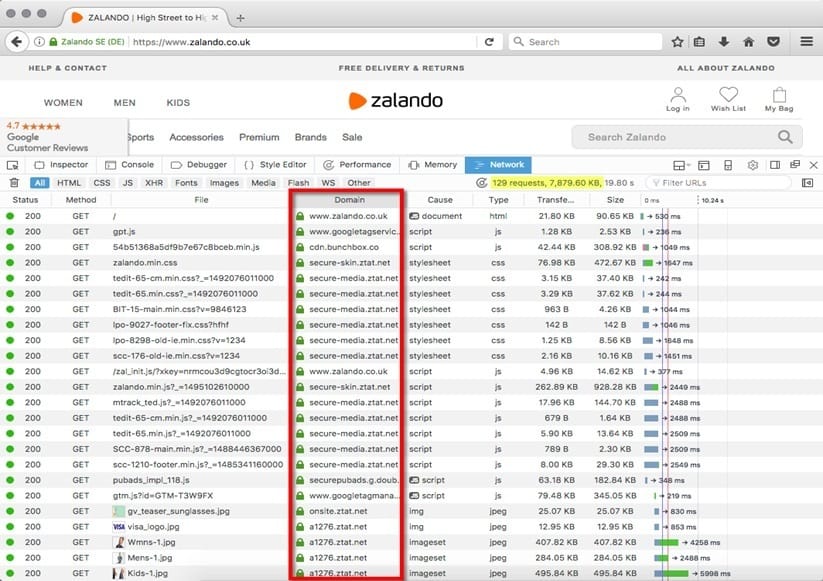
By looking at the source of most of the images, CSS, and JavaScript files, we can safely assume that zalando.co.uk serves their resources from ztat.net’s subdomains.
Once we filter out the requests by ztat.net, we can see that there are 50 requests with almost 16.8 MB of data (93%). Only 1.3 MB of data is served from a domain other than ztat.net.
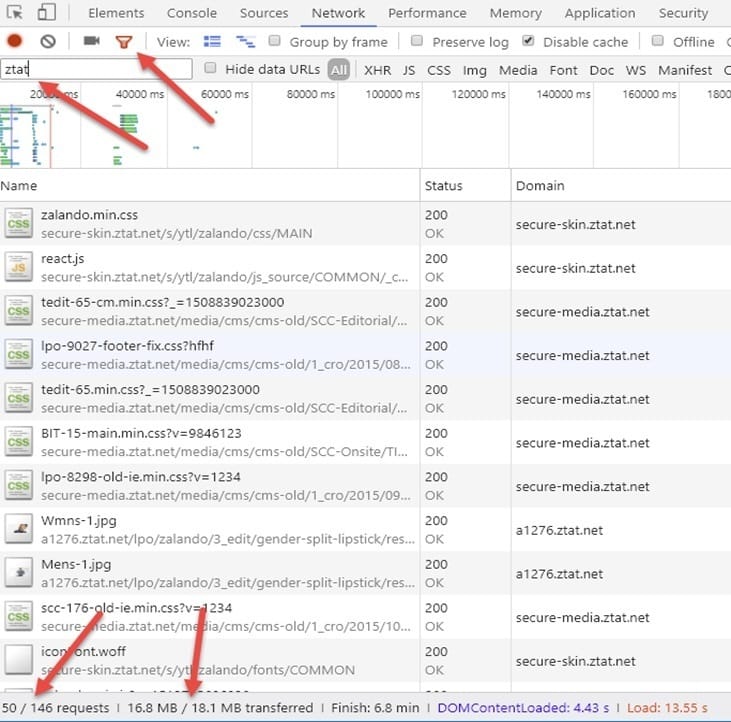
There are only two files served from https://www.zalando.co.uk: our main 22KB HTML file + 5 KB JavaScript file.

This is why I feel sick when I go to SEO conferences to see crawler budget case studies with a Google Search Console screenshot taken from the main domain when most of the content is served from external hosts. If it was Zalando, we would be looking at less than 1% of the data to draw conclusions about the whole structure, which is, by the way, hosted on a completely different server.
As you can see, this creates a huge discrepancy in what we see in Google Search Console when we only track our main domain. We only see a small percentage of the data Googlebot crawls. It is hard to make technical (or business) decisions based on such a small fraction of information.
Now, let’s go back to the Google Search Console data.
Main domain
Below you will see the crawling stats of one website. On the first chart, you can see everything that is hosted on the main domain (e.g., domain.com), and on the second chart, all the static resources hosted externally (e.g., static.domain.com).
I’ll compare the number of pages downloaded per day and kilobytes downloaded per day between the main domain and the static subdomain. I am ignoring the “Time spent downloading a page” chart in this comparison. Let’s have a look at the differences between those two datasets.
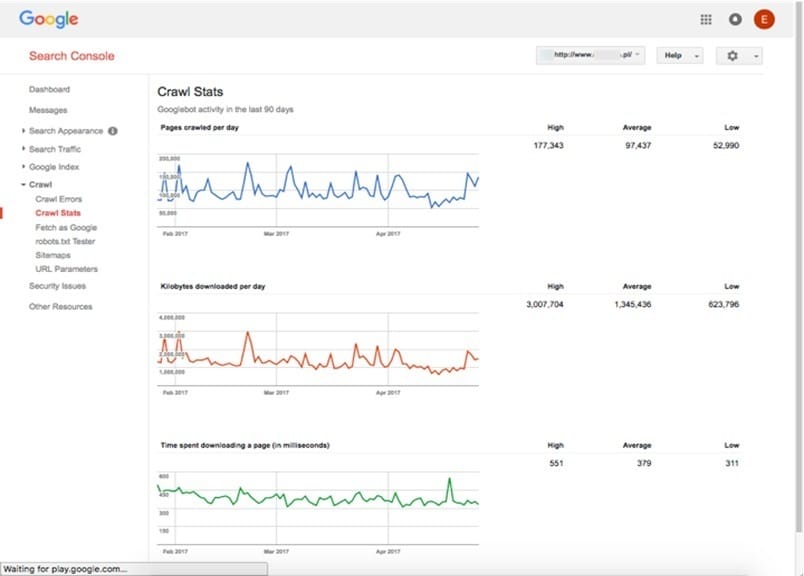
Crawl Stats
Pages crawled per day – 97,437
Kilobytes downloaded per day – 1,345,436 KB (1,345.4 MB)
Static resources
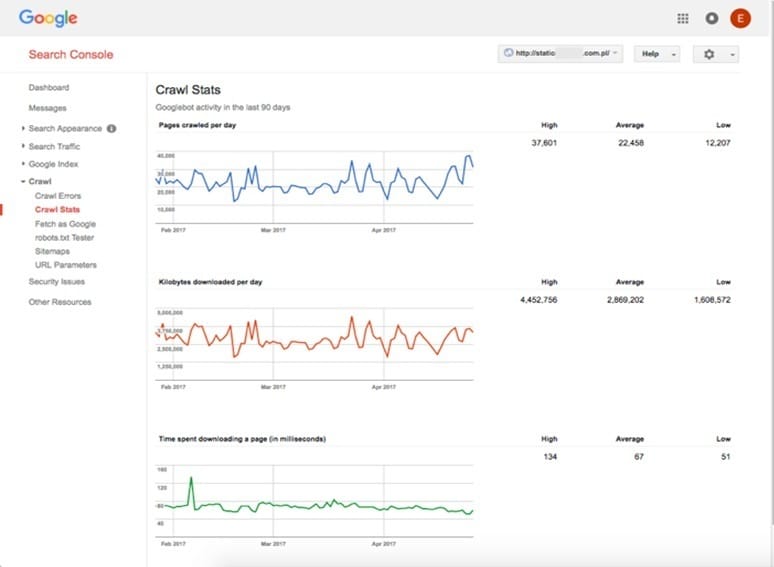
Crawl Stats
Pages crawled per day – 22,456 (23% of the main domain’s budget).
Kilobytes downloaded per day – 2,869,202 KB (2,869.2 MB – 213% of the main domain’s budget).
Those differences aren’t a strict rule, but in most cases, we will see that the static resources will have a lot more “Kilobytes downloaded per day” with a little bit less “Pages crawled per day.” This makes perfect sense as static subdomains/domains are usually used for hosting JavaScript, CSS, and image files, and those tend to weigh more than HTML pages.
By the way, if you haven’t already authorized a Google Search Console account, do it now!
What to do with this data?
Once you authorize all the hosts serving files necessary to render your page, you can start optimizing these resources.
With a good view of the resources needed to render your website, you can begin the process of optimizing them step by step. Consider Googlebot as if it were a browser (it kind of is, and it is Chrome 41).
Explaining the whole process of optimizing a website would require additional articles, but now that you have a good overview of how Google crawls your website, start working on improving all the aspects that can slow down the crawling and indexing of your website. The rule of thumb is that there are two key metrics that affect crawling: size and speed of delivery.
This is definitely a great start to get your crawler budget growing.
And let me leave you with a quick tip – if you are struggling with how much KB Googlebot is going through every day, double check if your cache is configured properly, as cached content takes 0 KB to load from the server.
If you still have any questions about crawling, don’t hesitate to ask Onely’s technical SEO experts.