
Let’s face some hard truths first.
If your content isn’t ultimately better than the alternatives, Google may choose not to index it. To make matters worse, we now know that you can get kicked out of Google’s index over time. We have hard data showing how common this problem is.
On average, 10-15% of your pages are not indexed by Google. Moreover, suppose your content relies on JavaScript (and it most likely does, even if you’re using WordPress, Shopify, or similar platforms). In that case, the risk goes up: 40% of an average website’s JavaScript-powered content is not indexed.
This article will guide you through this problem, all the elements that build into it, and of course, I will show you how to diagnose and fix it.
The weight of code
Over the last few years, there has been an outburst of new web technologies. Yet, while we all appreciate their functionalities, we rarely think about the cost of this ongoing revolution.
In 2011, a median weight of JavaScript code served by a mobile version of a website was around 50KB. Today, it is over 400KB. This is a 750% spike in the weight of code!
However, this is not the key problem.
Script dependencies
In 2011, it was rare for a website to rely on JavaScript execution to serve content. To make it simpler – to a robot, a website would look more or less the same with and without JavaScript.
Around 2015, we started seeing websites that would entirely rely on JavaScript (e.g., the famous hulu.com case), and today, most popular websites don’t work well without JavaScript. This means that Google most likely didn’t (or, at least, didn’t need to) execute ANY script before ~2015 to see the website’s content. This has now changed.
The cost goes up. 20 times
All of a sudden, Google not only has to render your website to see the layout (process your code to see how your content is organized), now they need to render JavaScript as well.
This raises the cost of crawling (and, eventually, indexing) your pages 20 times.

This cost is measured in resources needed to crawl, fetch, and render those increasingly heavy pages. It’s a gamechanger for both Google and SEOs. Search engines can’t afford the cost of processing everything we throw at them.
Looking for the solution
If you want to launch a successful website that relies on JavaScript, you will likely go through trial and error. No tools or documentation will allow you to assess with complete confidence that your new website will be properly rendered and fully indexed. The only thing you can do is to follow the best practices and hope for the best.
Over the last few years, we’ve conducted research on ways to diagnose and fix JavaScript rendering problems. We were looking for a repeatable, quantifiable metric that would precisely measure your potential rendering problems and guide you towards fixing them without hundreds of hours of work.
This turned out to be more complicated than we had hoped, even though we didn’t expect it to be easy.
Googlers were extremely helpful with all our questions about JavaScript, with one exception. They wouldn’t give us anything precise when we asked why some websites get rendered and some do not. Except for some obvious things to avoid, there was no clear definition or framework to predict if a website will struggle with rendering.
Throughout 2018 and a good part of 2019, we created 20+ experiments testing different theories to find the “sweet spot” for JavaScript-powered websites.

In mid-2019, we realized that we were not getting closer to the solution. Each experiment yielded interesting results, but none would give us a final answer.
We concluded that if we want to get to the bottom of the JavaScript SEO issues, we need to go big. Real websites, real data, and a timeline tracking how Google’s “limits” are shifting.
That’s why we created our JavaScript SEO toolset, and in September 2019, we started gathering data about Google’s indexing for both HTML and JavaScript. This is the first and only tool that shows the scale of the problem.
The results were beyond what we expected.
Findings we didn’t expect
Popular brands struggle to get into Google’s index fully

This list of brands goes on and on. Our database is filled with hundreds of the world’s most popular eCommerce websites, publishers, SaaS tools, and all sorts of companies that are struggling to get their indexable pages indexed in Google.
Indexing your content is getting harder.
This is not a temporary problem, even though anecdotal evidence may make you think otherwise.
Indexing your content is not a given anymore – you need to earn your place in Google’s index. And it seems to be getting harder over time.
With 9+ months worth of data, we can see the trend is negative. In other words, Google is indexing less and less content every month.
Indexing trends fluctuate during Google updates.
Some of the Google updates seem to influence the indexing trends we are observing. Google May Core Update 2020 is one such case.
The SEO community wrote tens if not hundreds of articles trying to understand what happened in May. I briefly went through some of them, and as usual, there are many hypotheses based on various SEO aspects ranging from backlinks to E-A-T.
While we probably will never know exactly what was targeted by this update, thanks to TGIF, we can shed a bit more light on Google’s May Core Update.
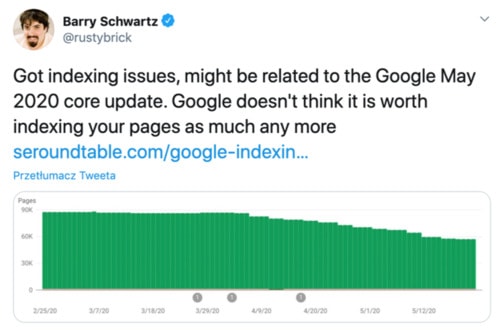
Barry Schwartz recently reported that “Googlers are saying, it might not be worth Google’s time to index those pages.” Well, this is probably true, but let’s see if our data reflects that.
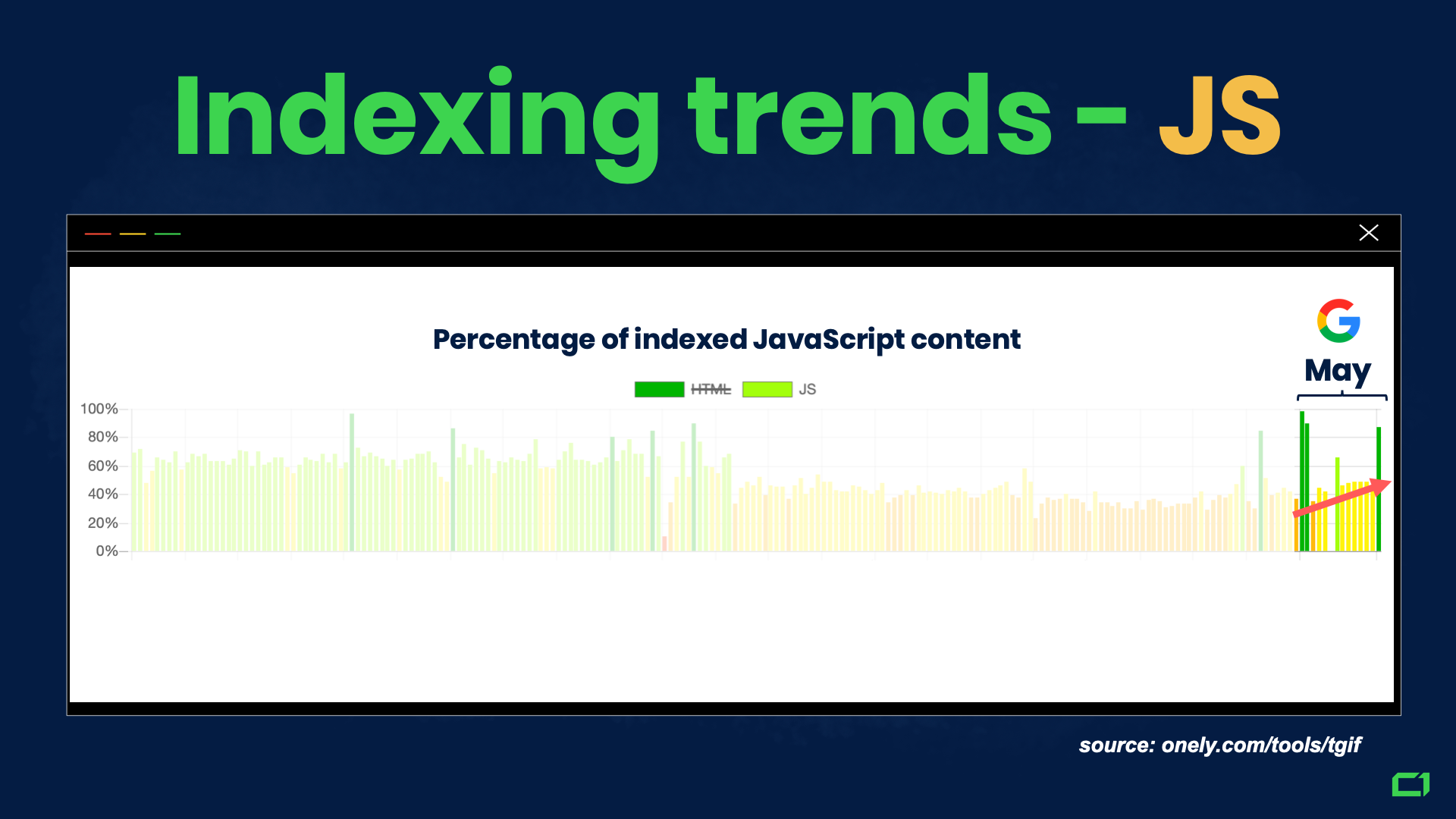
It is clear that JavaScript indexing improved in May. Google is currently indexing content that depends on JavaScript more eagerly than before.
However, if we learned something from observing indexing trends, Google has limited resources, and nothing happens in a vacuum.
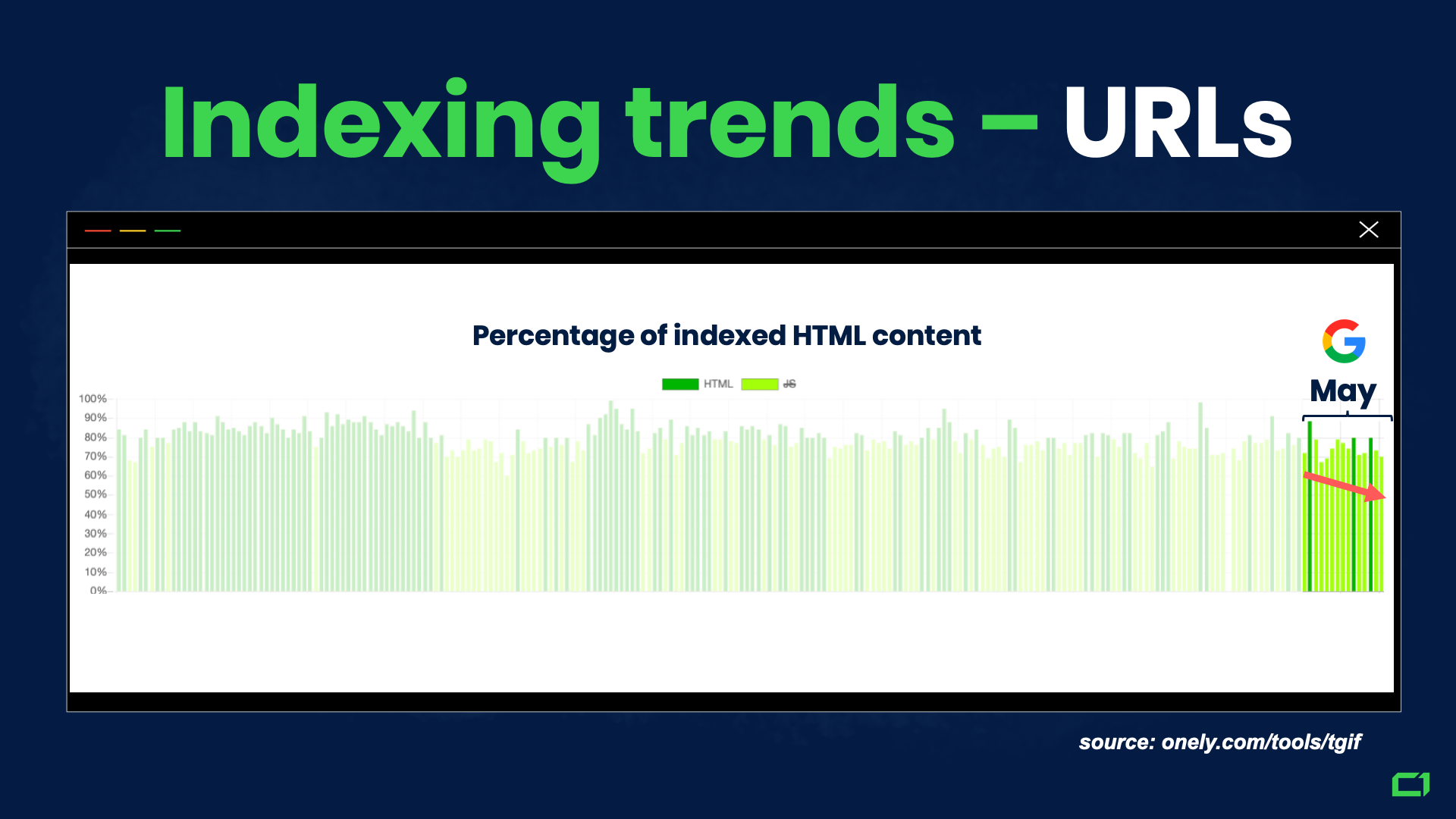
Looking at the screenshot above, we can clearly see that the increase in JavaScript indexing came with a price. HTML indexing declined, which is why so many webmasters reported seeing a decline in the number of their pages indexed.
Google’s index selection
Based on Google’s patents, let’s go through some of the basics of index selection.
- There is a line of URLs trying to get into Google’s index.
- Google has limited resources.
- Depending on the availability of these resources, Google may establish a threshold of URL quality and let in less attractive content into the index when there are more resources available.
- When Google’s resources are lower, your content may be removed from the index to make room for higher quality content.
As you can see, the quality of your content is essential, which is nothing new. However, it may be surprising how much that quality is determined by how your page is rendered.
Rendering – a search engine’s perspective
Statement
All the insights shown below are based on our research, our tools gathering indexing and rendering data daily, and documentation we’ve managed to find online (Google’s statements, patents submitted by Google, Google’s presentations and announcements, and everything we could find to get more insights into how rendering works at Google).
This article summarizes our research and findings of our subjective interpretation of how Google approaches rendering. We will be updating this article with new findings as our research progresses.
Rendering is essential for Google and other search engines to see and understand our website’s content and layout. Without rendering, your content doesn’t exist online. We are way past the times when you could see your content by simply looking into the website’s HTML code.
At the same time, this process is the most expensive part of the indexing pipeline.
Let’s dive into how Google is optimizing the cost of rendering on their end.
An intro to batch-optimized rendering and fetch architecture (BOR)
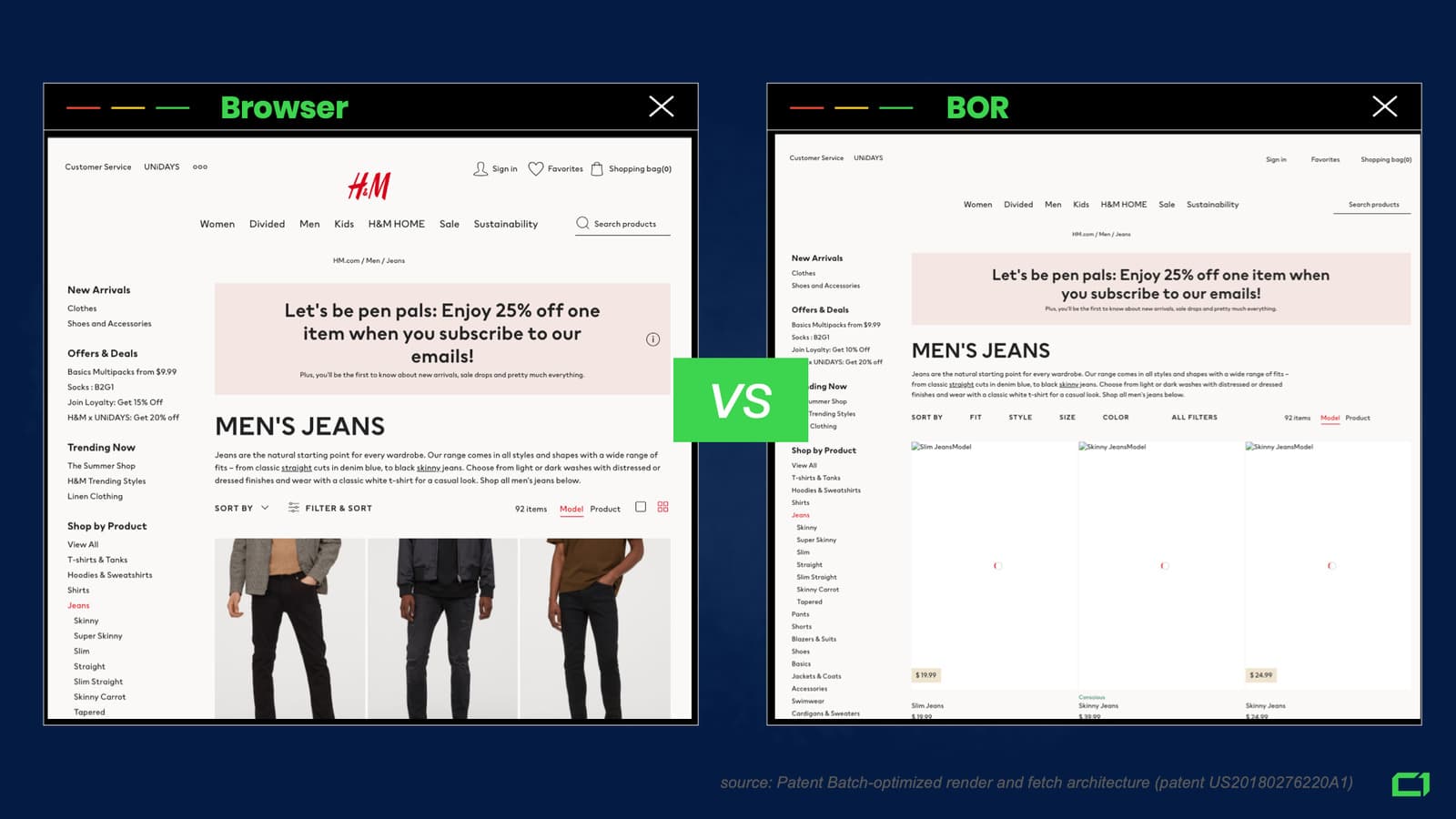
First of all – search engines are looking at your pages from a completely different perspective. They don’t care about many elements that are solely focused on real users’ browsing experience.

BOR is removing all elements that are non-essential to generate your website’s layout. These include:
- Tracking scripts (Google Analytics, Hotjar, etc.)
- Ads
- Images (BOR is using mock images to generate the page’s layout)
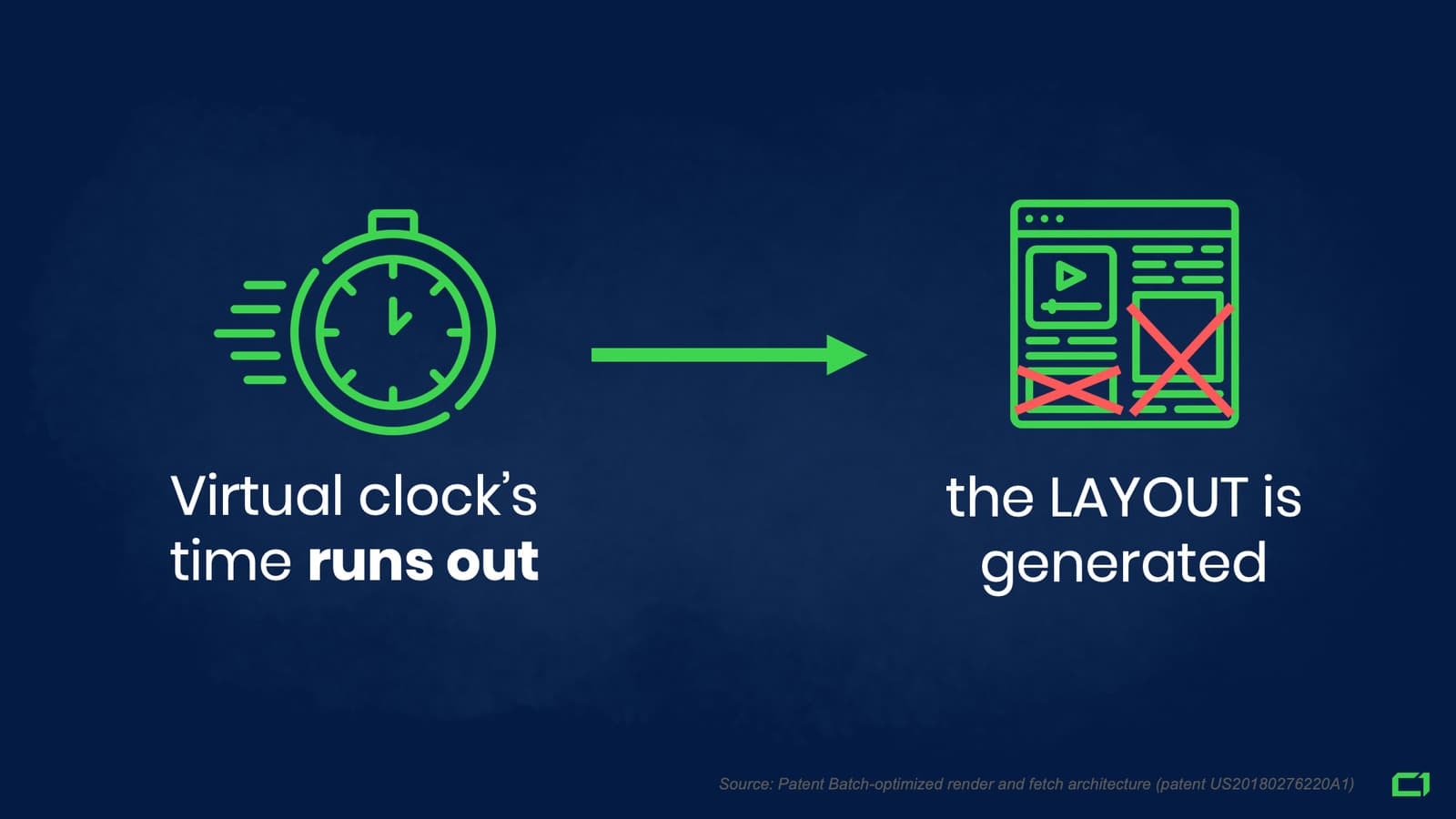
After removing all those unnecessary elements, BOR is setting a value on the Virtual Clock (which we’ll talk about later).

The final step of this process is when the time on the Virtual Clock runs out, and the website’s layout is generated. This is when things get both complex and exciting.

Use this information to rank better.
First, you need to understand the two key concepts of the Batch-Optimized Rendering architecture: the Virtual Clock and the Layout generated after the Virtual Clock runs out.
Let’s start with the Virtual Clock. While researching this topic over the last few months, we were shocked that it was never covered before apart from what we found in Google’s patents.
What’s a Virtual Clock?
Let’s start with the simplest possible definition and work our way down. Virtual Clock measures the time spent on rendering your layout. It’s not advancing while waiting for resources (scripts, CSS files, image dimensions, etc.).

This leads us to the conclusion that if your website is heavy with a lot of JavaScript/CSS to render – you need more time on that Virtual Clock. Will you be granted that time? I guess you already know what the answer is 🙂
There is a limit of how much (how long) BOR will render. Let’s investigate it.
Where is the limit of batch-optimized rendering?
According to Google’s patents, BOR sets the Virtual Clock to an unknown number of seconds. Exactly how many seconds are on the Virtual Clock is not relevant, as for this value to be actionable for us, we would also need to know exactly how much resources BOR is assigning to each rendering thread and a few other specific metrics that we will never get.
However, we can still work with the data we already have.
Knowing that the main factor limiting rendering is computing power, we can see how much your website relies on computing power to render. However, just like for website performance, we don’t have a precise score or a “goal” here. It is a moving target. We are aiming to be faster, lighter, better, and more efficient than the competition.
Statement
This is not a detailed walkthrough/analysis required to fully understand your rendering issues, but this is the first step to a better understanding of how much your website relies on computing power to fully render.
There are hundreds of ways to measure how much our layout relies on computing power. I’ll go through two of them: a quicker, easier way to diagnose problems on the spot (less precise) and a more complex method giving us a better understanding of how our website’s layout is generated.
Measuring the rendering cost – TL;DR
Go to www.onely.com/tools/tldr/ (TLDR = Too Long; Didn’t Render) and see how much computing power is needed to render your website on a scale from 0 to 100.

Anything below 20 – 30 points is OK. The results you’ll see in TL;DR are not very precise, but they can give you a ballpark figure of the scale of the problem for your pages.
If you score high – this means that you need to investigate a bit more. On the other hand, if you score low – a page you are testing is most likely not going to struggle with rendering problems.
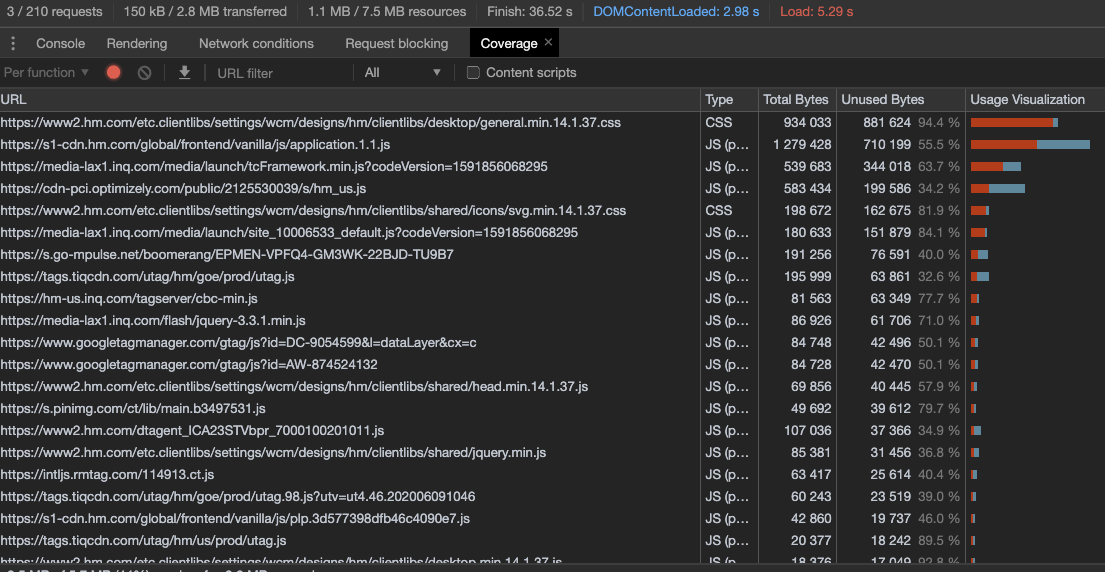
Measuring the rendering cost – Chrome Developer Tools
To measure your rendering cost more accurately, you need to remove all the unnecessary scripts, ads, and images from your page.
To do so, follow the steps from this video walkthrough I recorded and see how rendering with less computing resources affects your page.
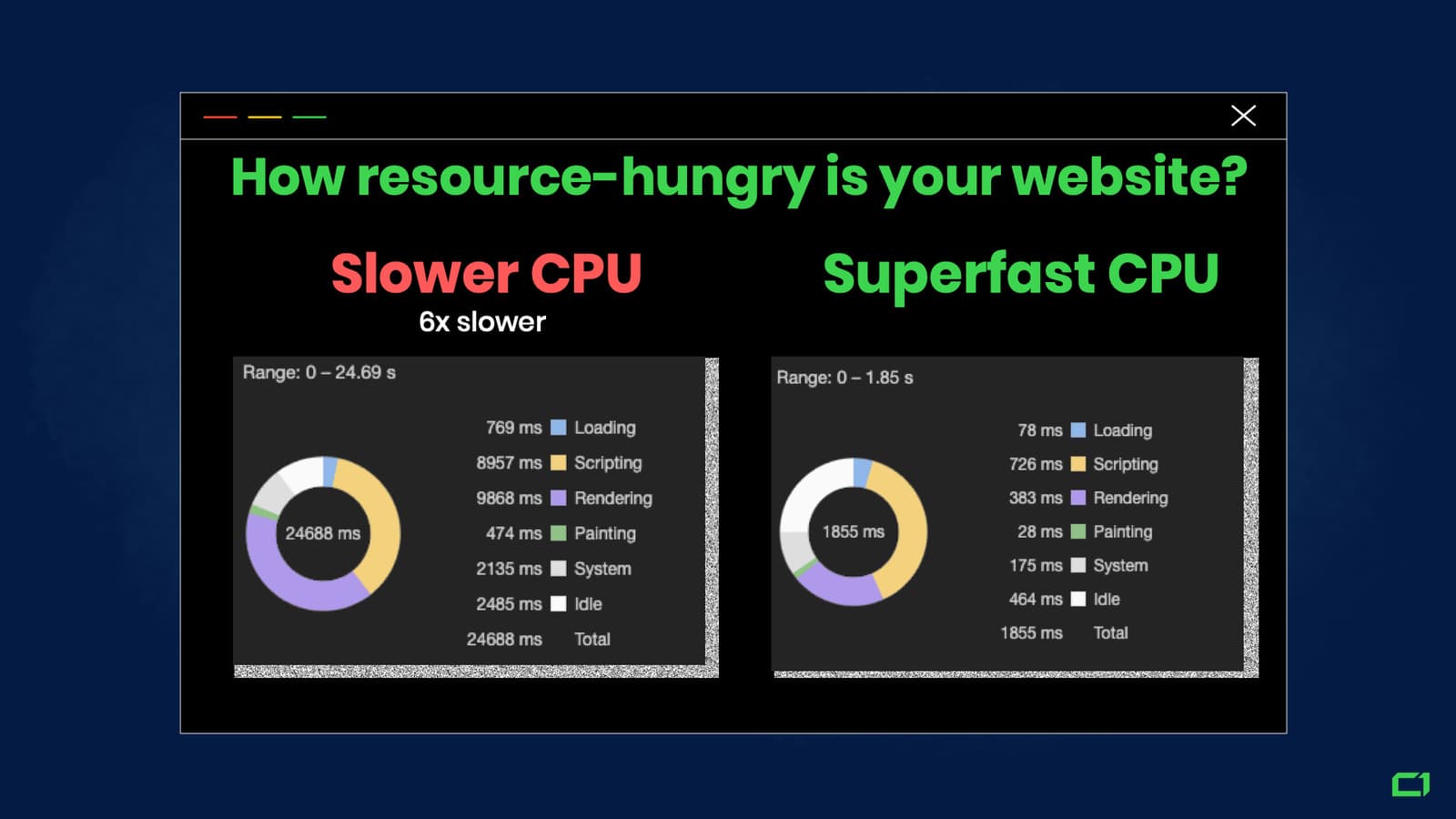
Looking at the example above, we can see that throttling your computer’s processor six times increased all of the components of the load time quite a bit. The duration of the rendering process was increased from less than 400ms to almost 10 seconds. This is roughly a 25x increase.
This shows us that the page I tested requires a lot of time on the Virtual Clock. Probably more than it is going to get.
Once we run out of time on the Virtual Clock, we enter a new, exciting, and very complex world of rendering and layout.
Rendering SEO and the layout of your page
Understanding how and why Google is looking at your website’s layout is the key to finding the missing link between crawling, rendering, and indexing. Those three elements are interconnected. Finding and unblocking bottlenecks between them has more potential than any other part of SEO.
Why layout matters for technical SEO
We knew that the content location matters for quite some time. As SEOs, we had an overall idea that Google is looking at content’s placement. We would advise our clients not to put too many ads above the fold, and we would talk about links on top of the page being more “valuable” than those below the fold.

What I want to share with you today is a bit more actionable and based on both Google’s documentation and patents, but also on more than nine months worth of detailed data into how Google is indexing content and which parts of the layout seem to be picked out by Google more eagerly than others.
Google’s patent on “Scheduling resource crawls” from 2011 is full of valuable information showing how Google is assigning different levels of prominence to different sections within the rendered layout.

When I started to understand Google’s logic around creating that queue of URLs to be crawled, it became clear to me that JavaScript SEO is merely a part of the problem. JavaScript SEO was mostly focused on IF Google will be able to see our content. This is important, but it’s just the tip of the iceberg.
Rendering SEO is a brand new territory with dozens of different aspects.
The Google Indexing Forecast (TGIF) dataset
Around May 2019, when we already knew that layout matters, we sat down with Tomek and went through all possible repercussions. We started to wonder if all the potential partial indexing problems we are seeing are JavaScript SEO-related. In other words, we wanted to try and find out if the cost of JavaScript is the main reason a page is only partially indexed.
Our best hypothesis was that maybe it’s not JavaScript, but instead, Google is picking parts of the layout that are more important so they can save resources otherwise spent scripting and rendering just to see the sections they are not interested in.
To even start analyzing this problem on a large scale, we had to build a database of websites with partial indexing issues. After a few months of intense work, TGIF (The Google Indexing Forecast) toolset was released during my SEOktoberfest 2019 talk.
How TGIF works
First, we picked a few hundreds of the most popular domains and started tracking their indexing delays (based on newly added URLs from their sitemaps). Now that we had information about when these URLs are indexed, we could start checking if different elements of the layout are indexed.
This part turned out to be one of the most shocking data points within our database. It helped us understand much more about how partial indexing works and which parts of your website’s layout are more critical than others.
We already knew that Google is assigning different values to internal links based on their location and attributes. This leads us to believe that Google has a good understanding of which parts of the website’s layout are more important than others.

What we realized when looking at the data gathered in TGIF is that there is a good chance that Google is using similar logic when deciding on which part of your website’s layout should be rendered and indexed. Going through all the partially indexed pages within our database, we found that:
- Google seems to be prioritizing the indexing of the “main content” of the page’s layout
- Some elements are being skipped by Google more often than others. Those elements being product carousels underneath the main content like “you may also be interested in,” “related items,” etc.

Partial indexing is more serious than it looks. It creates a vicious circle of crawling, rendering, and indexing problems.
In turn, these issues affect the whole website’s link graph and crawl budget. The same websites that are struggling with partial indexing also struggle with getting their URLs indexed.
How to address partial indexing
There are two main problems to address when solving partial indexing problems.
1. Your website’s CPU consumption
Google openly said that it will interrupt scripts. I assume this is Google’s way of explaining how the Virtual Clock works.

And this is when things get interesting again. Looking into our dataset, we are seeing clearly that layout elements that are often not indexed by Google are far from random.

Looking directly into Google’s statements and patents, they imply that rendering will be interrupted regardless of the different parts of the layout. However, based on our findings, some parts of the layout seem to be at a higher risk, so we would assume that Google’s heuristics might pick and choose which scripts to execute.
This brings us to the second problem that you need to address.
2. Understanding our website’s layout elements and their dependencies on different scripts
Now, to make it actionable, we need to clearly understand why Google decides not to index specific parts of our layout. There are multiple scenarios to consider here. Just to explain the most high-level approach to this problem, let’s have a look at one possible scenario.
Example:
My product name, images, and description are all indexed by Google. However, product reviews, user-submitted images, related products from the same collection (product carousel), and the social media feed below are not being picked up by Google.
Diagnostics path
Before we are gonna jump into the technical aspects, let me state something really important first. Rendering SEO is an important step, but it is not the best idea to be looking into rendering issues before addressing the following aspects first.
- Information architecture
If I were to choose the most important and the most underappreciated part of SEO, creating a clear information architecture would be my first choice. No questions asked. If your information architecture is not spotless, search engines will struggle to find and rank proper pages within your structure.
If it’s the case for you, contact us for information architecture services.
- Indexing strategy
If your website is not lean and Google is crawling thousands of URLs that are not valuable and indexable, you will struggle with indexing. The best solution is to crawl your whole website and look at the number of pages crawled vs. the number of unique, indexable, and valuable pages within your website. In 2020, wasting the crawl budget is not an option. Avoid relying on URL canonicalization and noindex tags. Those still require Googlebot to visit those URLs. In a perfect scenario, some 95% of Google-facing URLs should be unique, valuable, and indexable. Obviously, this is not always possible but aim for it.
Check out our Indexing SEO article to find out how to create a great indexing SEO strategy.
- Crawl budget optimization
This last point is fairly obvious after looking at the two points above. Make sure to regularly look into your server logs, crawls, etc., to make sure that Googlebot is only visiting the pages you want. The quicker you spot anomalies and problems, the safer your rankings are.
Find out more about crawl budget here or go for crawl budget optimization services.
Now that we have this out of our way let’s dive into our rendering’s diagnostic path.
Step 1
If Google is skipping a part of your page’s layout during rendering and indexing, the first thing to do is to go through the JavaScript SEO basics and see if your scripts are not, e.g., blocked by robots.txt, if all the elements are crawlable and indexable for bots.
During this process, you’ll need a deep understanding of the search engine’s limitations (e.g., Googlebot doesn’t scroll, doesn’t click, etc.), and of course, you need decent technical SEO knowledge. Misdiagnosing rendering problems during this step may lead to unnecessary and expensive code changes.
Step 2
Once you establish that your content is, in fact, fully accessible and indexable for Google, it is time to start looking into the specific scripts that are not being executed by Google. This is a broad topic, but let me just mention some areas to investigate.
The cost of your website’s scripting and rendering
- Does your web development team have web performance budgets set? If they do, are they within those budgets? How are those budgets set?
- Do you actually need that much script executed just to generate your product page’s layout? Maybe some of your scripts have features that may be only served to users and not search engines?
- Are you optimizing your critical rendering path? Is your website benefiting from progressive rendering?
How is your code structured throughout the website?
- Do you use one, the same, large JS/CSS file for every page within your website?
- How much code is not necessary? Getting familiar with the Coverage tab in the Chrome Dev Tools is definitely a good idea. Optimizing CSS/JS is definitely a lot of development work, but this is definitely worth the effort.
Is the content that’s not indexed relevant to the main content of your page?
- If you are using a section of your layout to do “PageRank sculpting” or as a solution to your poor information architecture or internal link structure, Google may start ignoring it.
- Is your main content/product page about running shoes and your “related items” section is full of digital cameras? Martin Splitt from Google recently confirmed that if some part of your page is not “supporting” your main content, Google may also skip indexing it.
Is your main content visible without JavaScript?
- If your main content is visible without JavaScript processing and “extra” elements of your page require a lot of computing power to render, there is a good chance that search engines will only index your main content. This makes a lot of sense from the search engine’s point of view. Why spend so many resources just to index boilerplate content or content that is not relevant to the user’s intent?
The list above is by no means definitive. However, diagnosing and fixing partial indexing problems becomes easier over time. As with most technical SEO tasks, our goal is to make the search engine’s job easy. This one is no exception.
Breaking the vicious cycle
Most of the time, partial indexing is a symptom of bigger-picture technical SEO issues. When we first started looking into partial indexing a few years back, we didn’t take this issue seriously enough.
Partial indexing means that you lose both control and understanding of your website’s graph. I have yet to see a website where partial indexing isn’t connected to other technical SEO issues. The example above is the most popular, judging from our data, but the options are unlimited.
Getting started with Rendering SEO
Rendering SEO is focusing on three key elements.
- The layout of your page.
- Relationship of your layout with parts of your code.
- How search engines understand and process both the layout and your code.
JavaScript SEO was mostly focused on “if Google can see our content.” We can see now that this point of view was extremely limited. For two reasons:
- Google will often skip indexing parts of the content, even for pages that are 100% HTML/CSS based.
- Rendering and indexing (and problems related to both) are a challenge with and without JavaScript dependencies.

When we started to analyze our dataset of partially indexed pages with LAYOUT in mind, we finally understood its importance.
Just to go through one example, content prominence seems to be a powerful metric and one we didn’t pay enough attention to. Google will go through heavy JS files just to make sure that your main, most prominent content is indexed.
At the same time, search engines will happily skip indexing of lightweight HTML/CSS content if it is not relevant to the most prominent part of the layout. Understanding how Google is assessing different parts of your layout is one of the most important things when it comes to getting your website ranking well in Google.
Here’s what you can do now: Still unsure of dropping us a line? Read how Rendering SEO services can help you improve your website.NEXT STEPS
Wrapping up
Getting your content rendered and indexed by Google is not a given. If anything, we can assume that getting your content into Google’s index will become harder and harder.
With billions of websites flooding the web while shipping code that is increasingly expensive to parse and render, search engines will have to pick content that is worthy of its price in the resources spent on indexing it.
I truly hope that I’ve managed to get you interested in the topic of Rendering SEO. While it’s one of the biggest challenges we are facing as technical SEOs, it comes with tremendous potential to make your website grow. Which is why auditing rendering issues is included in every technical SEO audit we conduct.
Do you want to know more? Check out these top insights about Rendering SEO with Martin Splitt from Google and Bartosz Góralewicz.

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!







