
Last week, I published my Ultimate Guide to Indexing SEO – a rather long piece of content that covers most aspects of indexing and solving issues around getting your pages indexed by Google.
It was published on March 25th, right after the presentation I gave on the same topic at BrightonSEO.
I shared the guide with the attendees as a useful resource for further research.
The next day, after ~30 hours from the guide being published, my colleague wrote to me: “Hey Tomek, your Ultimate Guide to Indexing is not indexed on Google yet.”
I don’t want to brag, but this is a seriously valuable and unique piece of content. Google should index it without much hesitation.
So I was fairly sure some bugs must have happened on Google’s end. And I wasn’t wrong.
Diagnosing the indexing bugs
Bug number 1
As the first step, I used the URL Inspection tool.
The Ultimate Guide’s URL was reported as “Discovered – currently not indexed.”
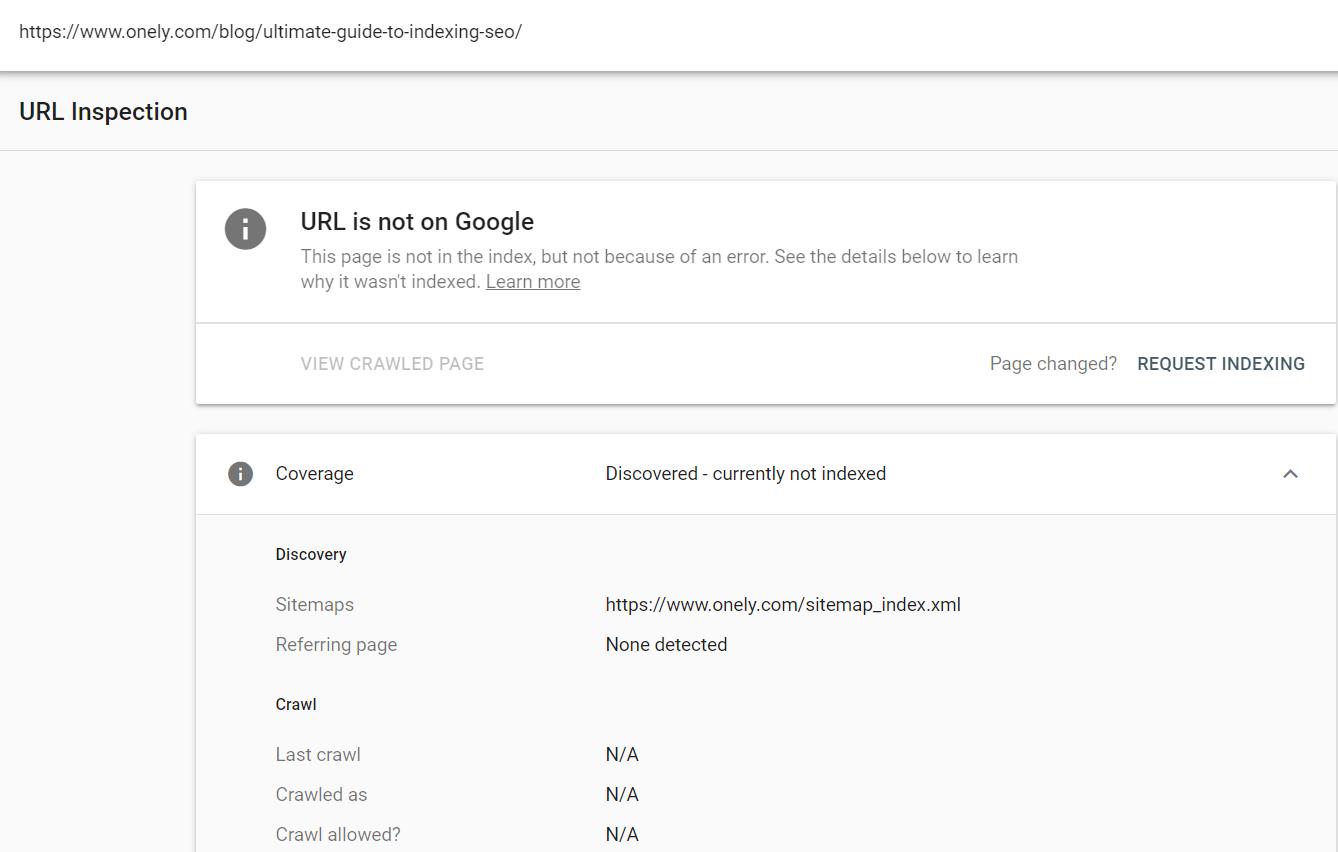
Google Search Console also showed no internal links pointing to this page.
I thought: “Wait, there are links on our Blog and I am sure Google saw them!”
To make sure, I used the URL Inspection tool with our Blog homepage.
I looked inside the crawled HTML, and my intuition wasn’t wrong. There WAS a link pointing to the Ultimate Guide.
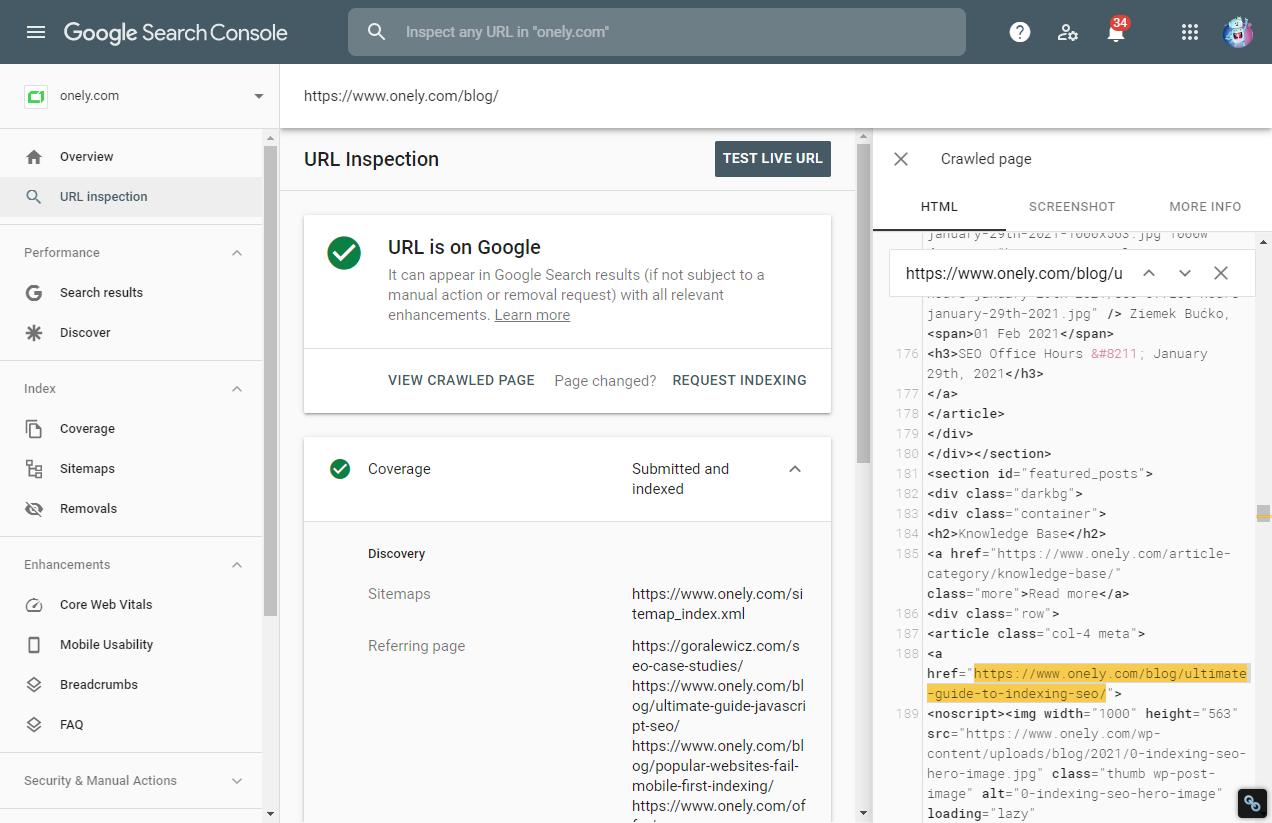
So there it was, bug number 1! Fairly easy to spot.
Bug number 2
Bug number 2 was more confusing.
GSC said the page was discovered but not indexed.
I double-checked what Google’s documentation says about it:
So Google discovered the Ultimate Guide but didn’t even crawl it.
Was it just a matter of giving Google more time?
Normally, I would wait longer before getting suspicious, and check if other pages were affected by this issue.
But this time was different.
The page that wasn’t indexed was The Ultimate Guide to Indexing SEO!
This called for more investigation.
So I went deep into the server logs.
Server log analysis is essentially a tool SEOs can use to spy on Googlebot. You can use them to check which pages were visited, and when. Quite powerful.
Let’s summarize what we know so far:
- Google Search Console claimed there were no internal links pointing to the page. I already showed you that was wrong.
- Google Search Console claimed it’s not indexed and wasn’t even crawled. As I found out from looking at server logs, that was wrong as well.
| What GSC claims | Reality |
|---|---|
| A page wasn’t visited by Googlebot | A page was visited by Googlebot multiple times, over 5 days ago for the first time! |
| There are no links pointing to this page | There are links pointing to this page and Googlebot discovered them. |
If you happen to be a Googler reading this and you want to investigate, here is the exact footprint:
- IP of Googlebot visiting my Ultimate Guide to Indexing SEO: 66.249.64.243
- Time: [25 March 10:56:12 +0000]
- Type of Googlebot: Googlebot Smartphone (the site is under Mobile-First Indexing).
The obvious question that comes to mind is: “Is this just a reporting bug from Google Search Console?”
Now here’s the most interesting part:
It turned out that Google indexed an improper version of the page, and I have no idea why,
When you search for “Ultimate Guide to Indexing SEO”, you’ll find the page, but…
Google indexed the version with no trailing slash. Which, according to our server logs, was never crawled by Googlebot. So why did it happen? It’s not the canonical version, and there are no links on our site pointing to the URL without the slash!
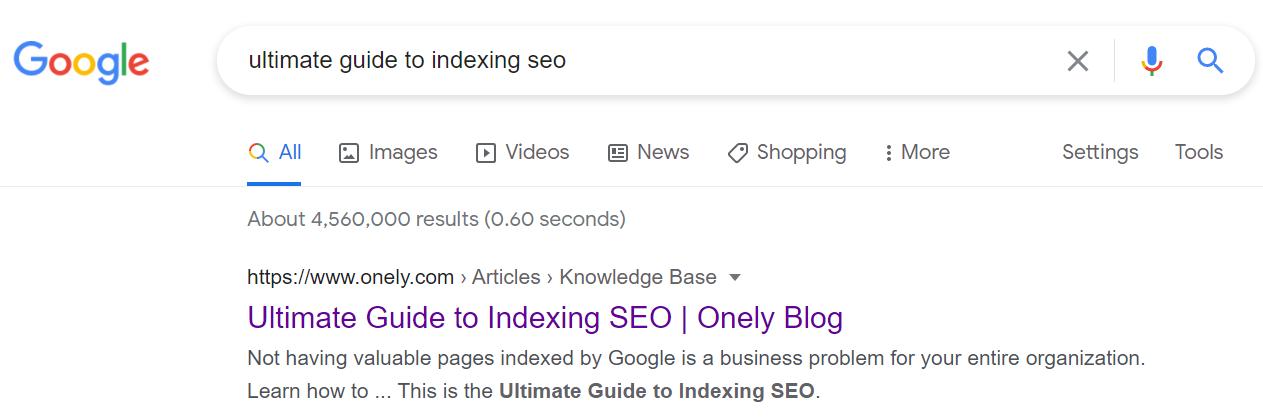
I saw similar patterns multiple times on other websites. For instance, I saw a few big brands that suffered from a temporary bug when the HTTP version was ranking instead of HTTPS.
Is this just a reporting bug? Or is Google missing ranking signals from the canonical version, with the trailing slash?
What’s the lesson here?
Every website can suffer from indexing issues.
I was able to investigate the issue and, at the very least, notice that the reporting in GSC was wrong.
But many site owners won’t go looking for the answer in their server logs.
Indexing issues are often self-induced. But just like in the case of my Ultimate Guide, Google’s systems sometimes don’t work as expected.
And in my case, it’s just one page. Here’s a story showing that this can happen on a much larger scale.
Recently, a friend of mine, who is working for a popular news publisher, got his website permanently de-indexed. It stopped showing up in Google Search, Google Discover, and Google News.
The situation lasted for 2 weeks, then it went back to normal. They didn’t get any notification from Google.
And it’s not even the first time this happened to that company. They previously had a different domain fully deindexed for 2 weeks.
Then, with no action taken on their end, Google started showing their domain in search results again. Why does this happen?
Wrapping up
I wish Google was more open about the following:
- Indexing takes time and even unique, valuable content may spend days or even weeks in the indexing pipeline.
- Indexing bugs occasionally happen with no fault from the website owner.
- Even small sites may struggle to get fully indexed, even though there aren’t any technical problems blocking Google.
Google Search is a very complex system, and it’s expected that bugs will happen every now and then.
There are many ways to get help from Google in these cases: We have fantastic Google representatives helping the community, recording SEO Office-hours, and answering questions on Twitter and in the Google Webmaster forums.
That being said, I can’t shake the feeling that Google could be more transparent when it comes to indexing bugs that happen every single day and give us more meaningful advice on solving them.
Have you ever had similar problems with your content? Did you manage to diagnose the issue, or did you simply wait it out? Let me know!
And if you need any help with indexing bags, contact Onely for technical SEO consulting.







