Ryte’s Izzi Smith joins forces with Onely’s Tomek Rudzki to get to the bottom of Medium’s dramatic loss in SEO visibility.
Medium is a trusted user-generated content publisher. It even employs an engagement-based model to pay its contributors through paywalled articles.
On paper, it’s an ideal platform for aspiring and professional writers alike.
However, according to Searchmetrics and Sistrix, Medium’s top-level domain recently saw a 40% drop in organic visibility in desktop and 50% in mobile.
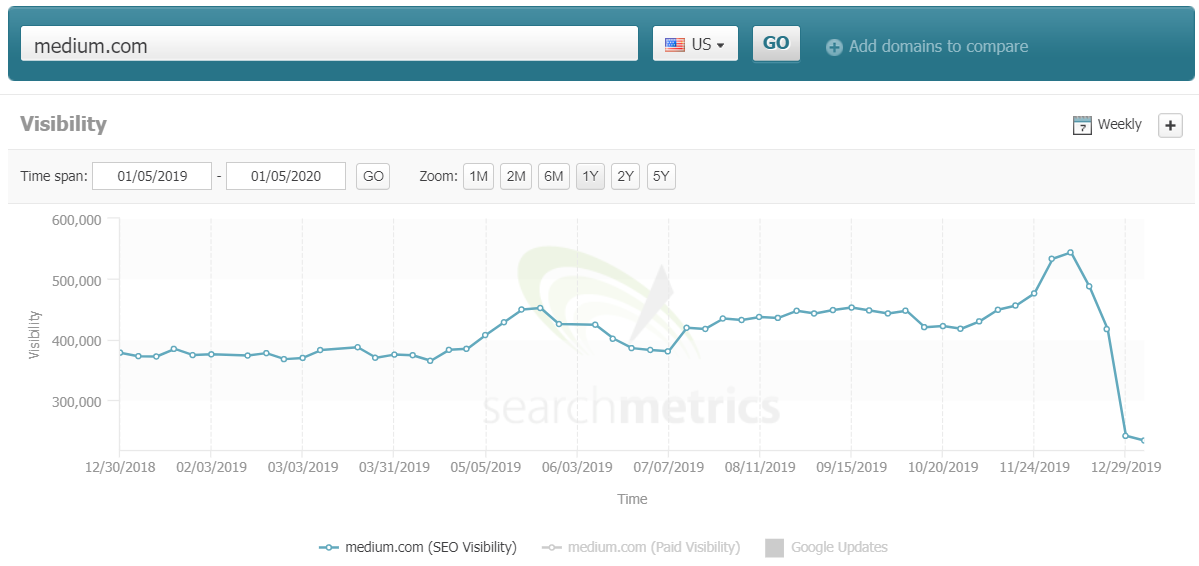
This is a dramatic decrease and something Ryte’s Izzi Smith and Onely’s Tomek Rudzki wanted to get to the bottom of.
Using Ryte’s Website Success, they did a quick crawl and analysis of Medium’s technical set-up and content.
Here are their thoughts on why Medium might be tanking and what SEOs can take away from all of this.
1. Homepage cloaking
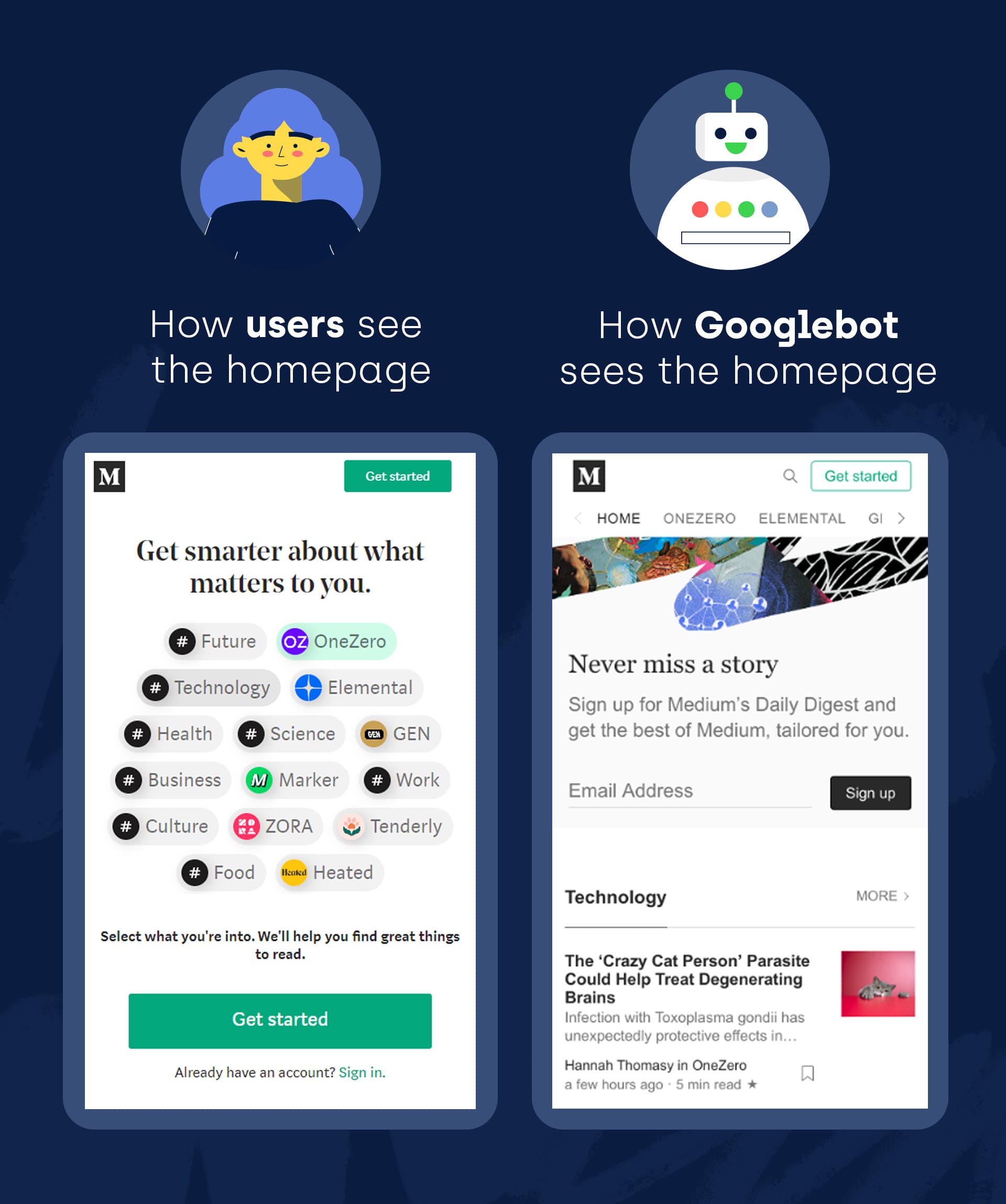
IZZI: The first thing I noticed during the initial analysis was just how different the homepage was compared to my previous visits.
Mainly, the menu and navigation links were missing, the top stories were removed, and there was barely any content displayed aside from subscription call-to-actions.
What kind of a domain’s homepage that relies on organic traffic removes all of its outgoing internal links? Either one that knows nothing of SEO or one that’s cloaking search engines.
To confirm my suspicions, we used Chrome Dev Tools and Google’s Mobile Friendly Test to change the user agents around. When setting the custom user agent to that of Googlebot, Googlebot Mobile, and Googlebot-News, Medium’s classic homepage appeared with featured articles, content, menus, and everything else.
Although this is not as extreme as black hat SEO cloaking cases (and could be the result of an A/B test that got out of hand), it can still be viewed by Google as an attempt to hide specific intentions and therefore could be punishable.
The timing is coincidentally quite significant.
The huge visibility drop started on 8th December 2019 and using the Wayback Machine’s archive, the homepage variation was implemented in early November.

This alternate version for non-logged-in visitors could make it clear that Medium’s strategy is becoming even more aggressive towards capturing new paying subscribers.
2. A major issue with low-relevance, indexable URLs
IZZI: Medium has a, ahem, large problem with indexable, uniquely generated URLs that simply have no place in the SERPs.
A huge example of this is that comment sections for each article generate their own URL rather than being available within and strengthening the relevant post.
According to site search analyses, the /responses/ path has around 2.2M indexed URLs, although the true amount could be a lot higher.
This is a confusing strategy for a number of reasons.
The value provided by reader responses should be present on the page to strengthen that article’s authority and context, and it makes no sense for this type of content to be found on its own URL via search engines.
Who is specifically searching in Google for comments on an article? No one, that’s who.
Similar problems were found with user profiles. For each new writer or subscriber, a new URL is created for
-
- The user’s profile
- Users they follow: /following (1.2M indexed URLs)
- Users following them: /followers (1.1M indexed URLs)
- The articles they recommended: /has-recommended (1.2M indexed)
- Their comments: profile-name/responses (2M indexed)
- Their highlights: profile-name/highlights (400k indexed)
So in total, around 7.5 million URLs should not be indexed (and counting), but are.
Whereas the user profiles can sometimes make sense to index, especially for authority figure contributors, the overall logic causes many weak pages to be fully indexable in their own right and can lead to large issues with the crawling budget and Google’s core Panda algorithm that punishes thin, low-quality pages.
There’s also a relevancy question in play.
Does it make sense to have an indexable URL for the listings of posts someone has recommended? Are searchers looking for this information in Google?
To be honest, I highly doubt it.
Problems like this are easily avoided by including the comments on the article’s page, or if you must create a separate URL, utilizing noindex robots directives.
What’s additionally worrying is the fact that even if there are no comments for an article, an indexable URL is still created, causing thousands of these thin pages.
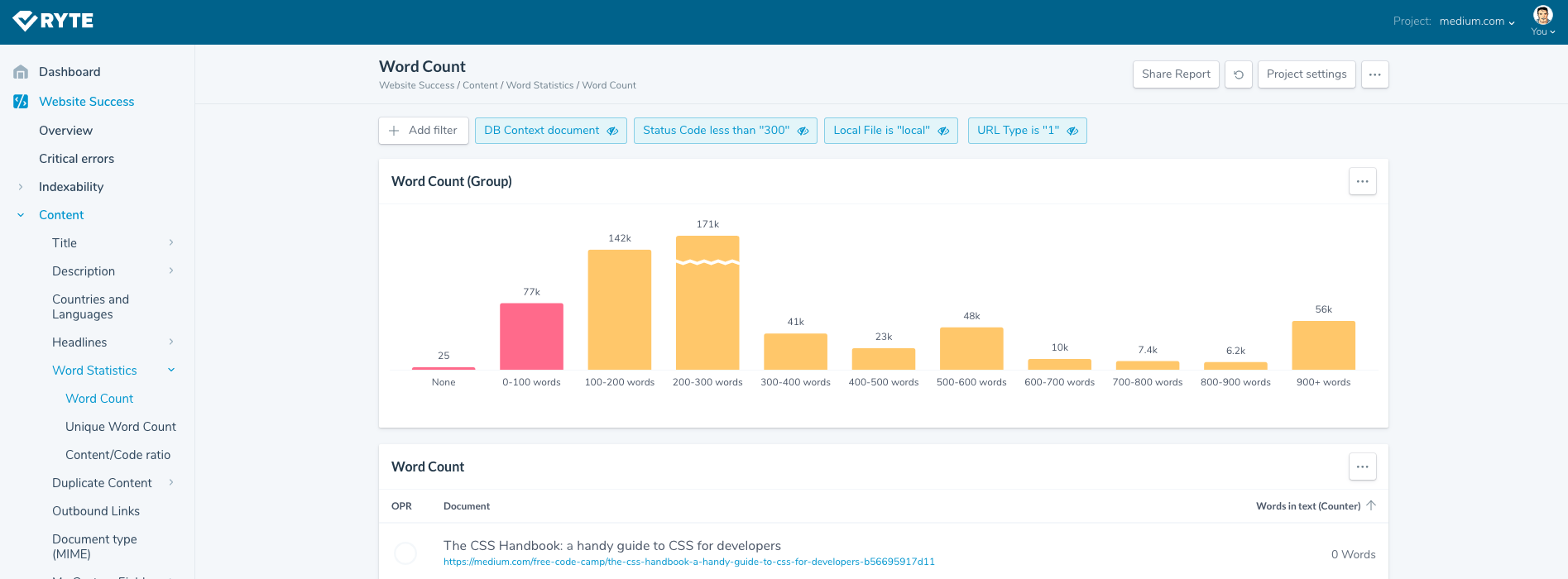
A screenshot from our segment of Ryte crawl data broken down by word count. As you can see, the majority of indexable pages have a low amount of text.
3. 16% of Medium posts cannot be found in Google
TOMEK: It seems Medium.com tries to index millions of low-quality pages while many VALUABLE pages aren’t indexed in Google.
Based on my research, 166 articles (from a random sample of 1,011 articles extracted from Medium’s sitemap) aren’t indexed in Google.
That’s over 16%!
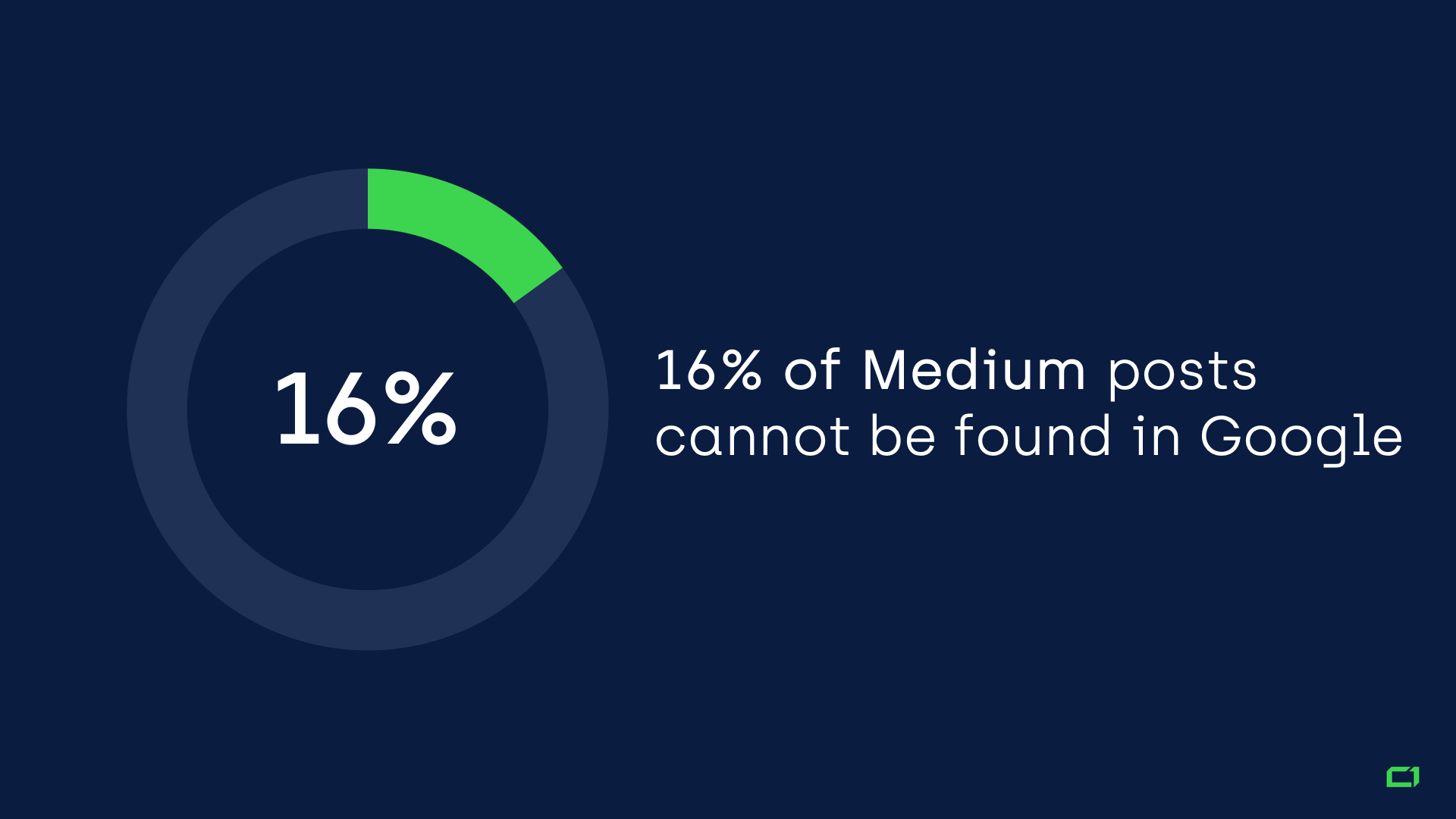
It seems the reason is simple: Medium has no crawling and indexing strategy.
It simply floods Googlebot with tons of URLs with no value, hoping Googlebot will eventually find and index all of the valuable resources.
Pagination allows Googlebot to visit just ~40 product pages per category.
Google is forced to find articles through millions of tags, followers lists, etc, which doesn’t make for an easy task for Googlebot.

4. Broken priority pages
IZZI: During my analysis, I found broken pages that were heavily linked to that could potentially be bringing in a lot of lucrative traffic were it available.
4xx URLs, either created by incorrectly set links or by content creators referencing non-existent pages, are generally a big problem that may occur if you have a lot of user-generated content to oversee.
For example, the tag URL for “Elections 2020” (https://medium.com/tag/election-2020) is referenced by 490 articles, yet leads to a dead “Not found (404)” page.
Whereas it’s not a good practice to index every tag page on a blog, this tag URL is surely an important resource for Medium and should exist, be indexed, and be ranking right away.
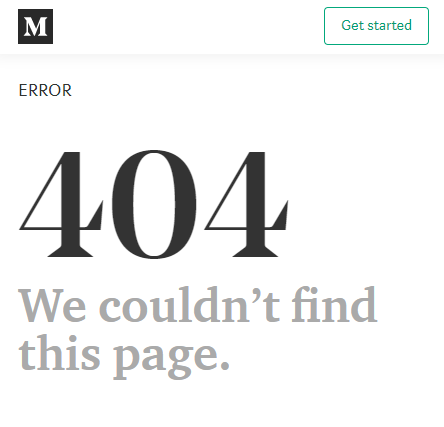
There is a similar case for generic, user-specified tags, such as “2019” and “2018” which are being linked to heavily. Evidently, the tag creation logic is something that Medium’s CMS should consider and maintain control over.
5. Sitemap havoc
IZZI: Another problem that can cause crawl budget issues is the fact that Medium has an incredibly strange sitemap logic.
XML sitemaps are set to act as a crawling priority system for search engines and feed additional optional information, such as last modified dates.
Every single day since 2012, Medium has had a system that creates a sitemap for every article, tag, and new users for that day, which are all housed within a sitemap index file.
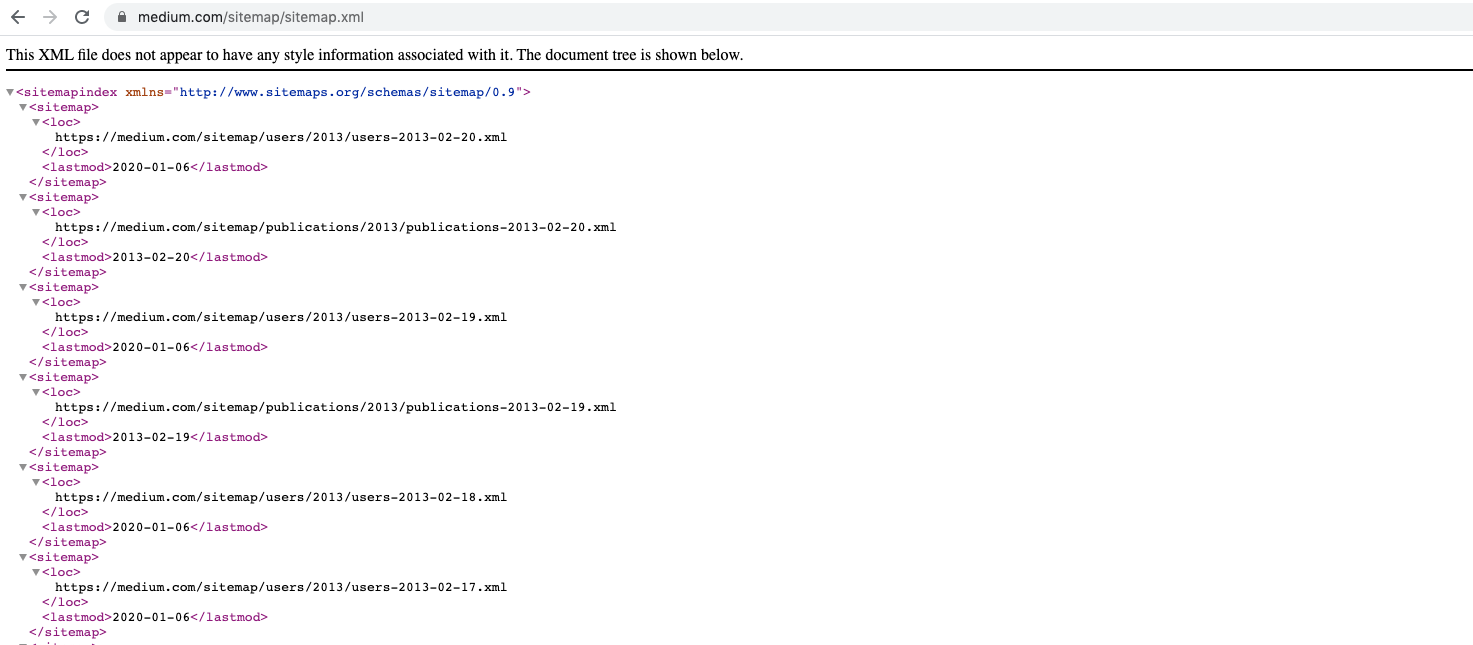
Medium does not quite exceed the pretty hefty size and URL limit set by Google for sitemap indexes (50,000 sitemap URLs and 50MB), but there is evidently a lack of priority given.
The best practice here would be to analyze the necessity of the available older sitemaps, especially those for tags and user profiles.
Let’s take a quick look at a sitemap from 2013, which references the seemingly important collection of articles about Vinnie the Cat, but for some reason, there is no longer any content available.
This is a huge shame because I really wanted to learn about Vinnie’s cat adventures…and because Medium is continuing to include outdated and broken pieces within their sitemaps.
6. Poor internal linking
TOMEK: Basically, Google is only able to visit ~40 posts per category on Medium.com
Users may potentially access an unlimited number of articles. They can easily scroll down through the category listings.
However, Googlebot cannot do that as Medium.com implements a type of infinite scroll that Google cannot deal with. Let’s see how they manage two categories:
- Technology – Google can only see 40 articles.
- Health – Google can only see 40 articles.
Keep in mind, there are millions of pages on Medium.com, 40 posts per category isn’t simply enough to let Google discover all the valuable posts on Medium.
This is probably why Medium tries to index all the possible tags, followers(!), and many other low-quality pages. Unfortunately, that’s a short-sighted strategy that can be harmful.
Links to similar articles
TOMEK: Like many modern websites, Medium provides links to similar articles. Medium accomplishes this by using JavaScript. Unfortunately for the website, Google skips this section in 50% of the cases.

There may be various reasons for why this is happening, including JavaScript SEO issues or relevancy.
Additionally, their recommendations aren’t useful. Let’s use one of their popular articles as an example: Yes, You Should Delete Facebook
What are the recommended articles for people who read this article? Well, horoscopes and taxing ultra-rich people.
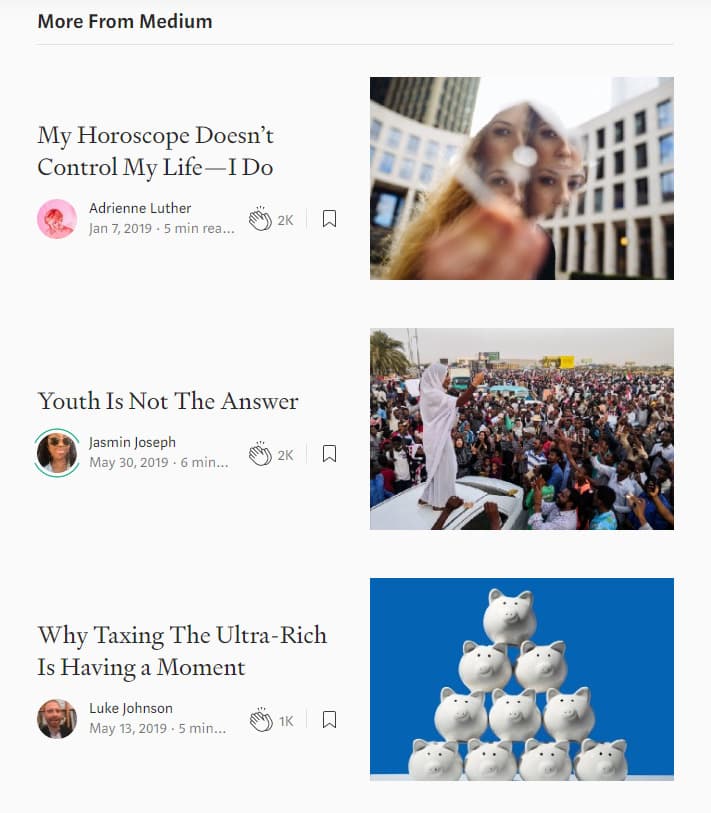
People would more likely be interested in how to secure their Facebook account or alternatives to Facebook Messenger.
In general, things related to technology and social media, not whether or not they’ll meet the love of their life tomorrow who may or not deserve to be taxed more.
To avoid similar SEO traps, you can contact Onely and schedule internal linking optimization.
7. You can’t always trust those outbound canonicals
IZZI: One of the main benefits of sharing an article in Medium is that you can utilize its power and authority, and make your content available to many more readers than your own smaller site would.
To encourage this, Medium has given their contributors the option of setting a cross-domain canonical, which negates any issue of duplicate content should you wish to keep it published on another website.
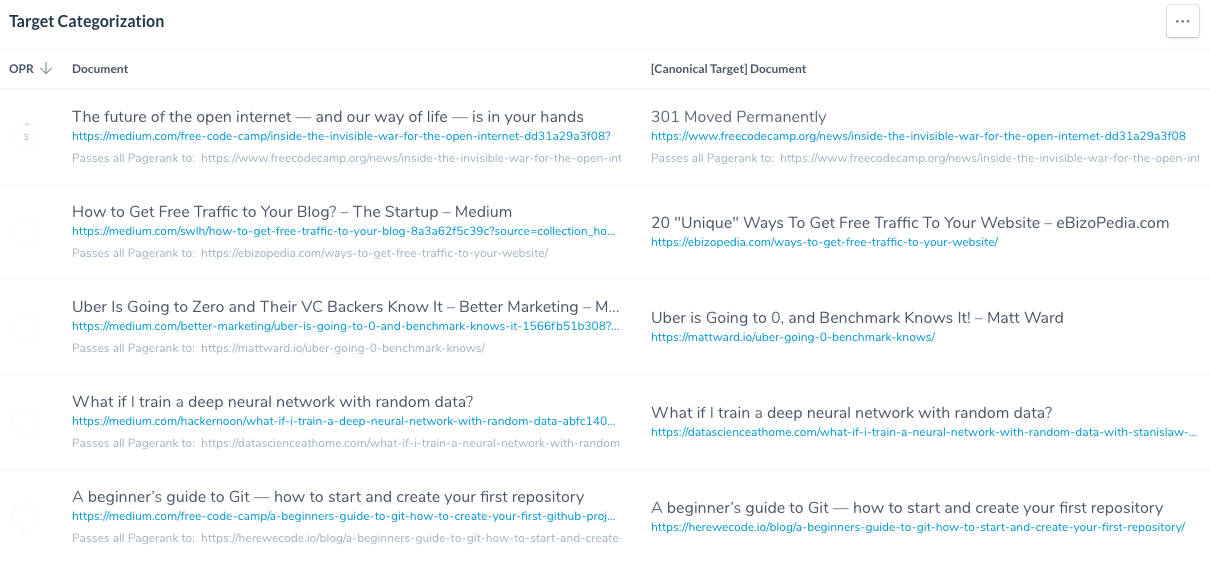
Screenshot from Ryte’s Canonical Report
According to my analysis of Medium’s top-level domain, around 7% of its canonicals are leading to external sources.
This is fine, but when you cannot oversee or guarantee the quality of the target documents on a large scale, you could be inadvertently linking to harmful destinations that detriment your domain as a whole.
8. An abundance of internal nofollow links
IZZI: Although falsely used to internally sculpt page equity, nofollow can be a hint to search engines that you don’t trust the content you’re linking to, so it’s poor SEO practice to use them internally.
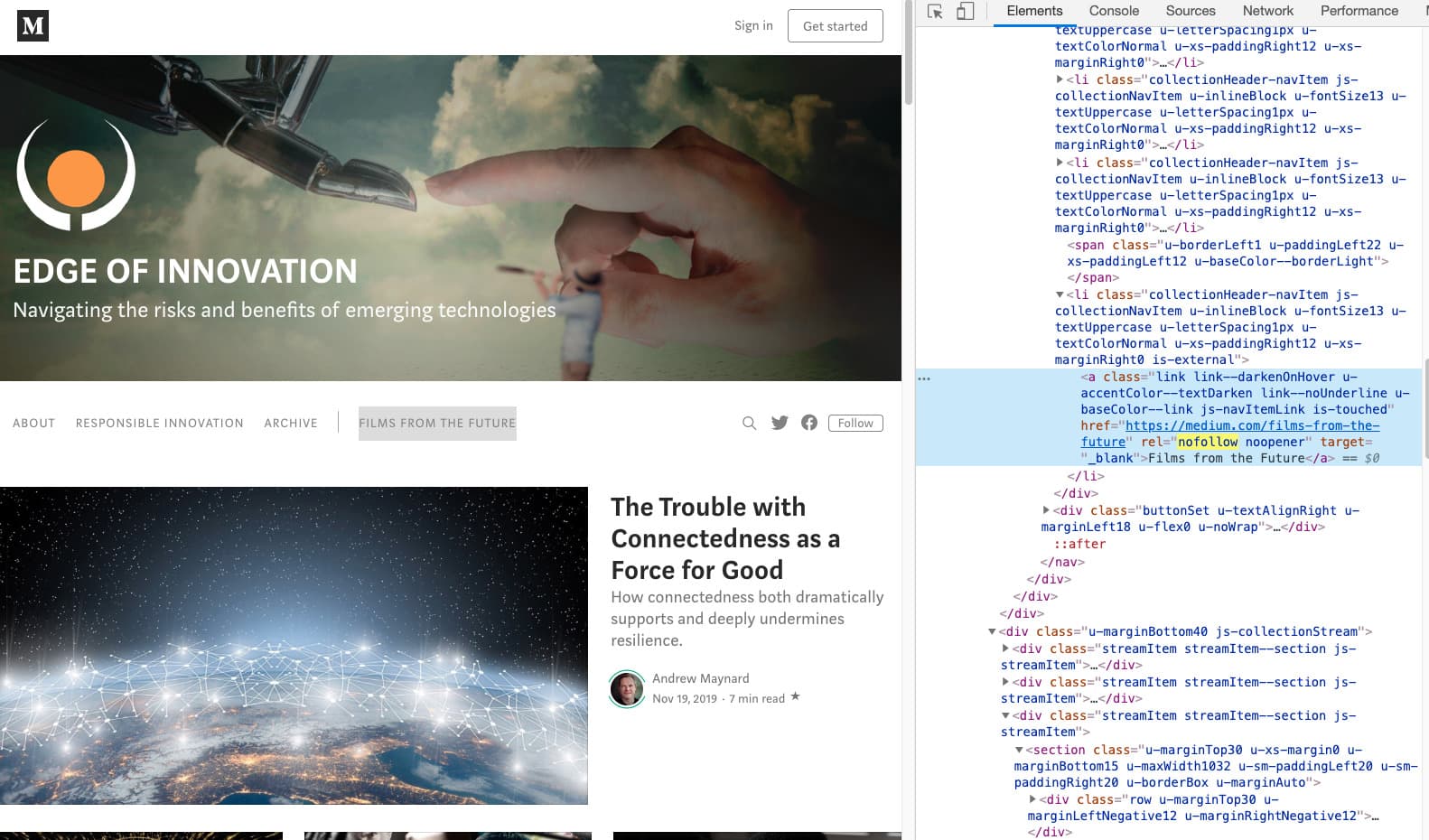
Unfortunately, Medium has used rel=nofollow widely and freely across their site, with many CMS features defaultly wrapping links with the attribute.
I also discovered that all button links for a magazine’s overview page were set to nofollow, as well as certain menu navigation properties. These should definitely be set to follow, given the high importance of these references and the strength they can pass on.
9. Mobile-first indexing?
TOMEK: When Google’s organic visibility drops, it’s always a requirement to check if the issue is related to a website having just switched to Mobile First Indexing.
In the Mobile First Indexing world, Google indexes the mobile version of a page and uses it for ranking purposes.
In fact, Medium.com looks slightly different on mobile.
For instance, there are no links pointing to similar articles on the mobile version of the website.
Based on my analysis, Google still hasn’t switched Medium.com to the Mobile First Index, so this probably isn’t the reason for the recent drop.
That said, it’s only a matter of time before MFI will be enabled for Medium’s website and they should properly analyze their mobile version to avoid the possibility of more organic drops in the future.

10. Paywalled Content?
IZZI: Google has been transparent about the fact that they have no problems with article content that is hidden behind a paywall, but only when the correct steps are taken into account e.g. providing schema markup with the “isAccessibleForFree” property (something that Medium is actually correctly implementing).
Therefore, this should not be the cause of its organic visibility drop. However, perhaps this is a signal from Google that they may be demoting cases like this.
On one hand, searchers expecting to see a full article and then not being able to read it is delivering a poor user experience, but on the other hand, it’s understandable that publishers who don’t want to fill screens with ads need to somehow generate revenue.
I predict (and hope) that in the future, Google will recognize the confusion within the SERPs or on Google News that content availability is ambiguous and look into potentially implementing paywall “labels”. This shouldn’t be all too difficult logistically: the schema markup is explicit feedback alone and can potentially warrant its own rich result data snippet.
This change to the News SERP’s appearance can only stand to improve the quality of a publisher’s incoming traffic and reduce the frustrated, short-click visits.
This may also benefit search engines from a monetary perspective. If users prefer visiting free-to-read news sources, Google can gain from increased GDN placements.
Takeaways
Although the specific reason for Medium’s drop in organic is not entirely clear (as always with SEO speculations), Medium is living proof that despite publishing high-quality content, the technical aspects always need to be considered and dealt with in order to make the content perform highly in search engines.
let current_datetime = new Date();
document.getElementById(‘datetime’).innerText=”Today is ” + current_datetime.toString();
To avoid falling prey to similar technical challenges, make sure that your SEO strategies include:
- Avoid the risk of potentially cloaking search engines by checking variations with multiple user-agents and Google’s Mobile-Friendly Test.
- Assess the necessity for pages being indexed by analyzing quality, relevance, and valuable user metrics, such as incoming traffic and time on site.
- Check whether you have highly important yet broken, unreachable, or unindexable URLs by using SEO crawlers.
- Always provide prioritized sitemaps that direct search engine crawlers on the correct path of your website, and clean up older and irrelevant sitemaps.
- Aim to keep a watchful eye over user-generated content, and outgoing external links and canonicals, to avoid potentially referencing harmful sources.
- Avoid internal nofollow links to not show search engines that you find your own pages and content untrustworthy.
- Guarantee that Google is able to index all your valuable content.
- Having great content is not enough to make a website successful: use technical SEO best practices to ensure your content is easily discoverable and accessible by search engines and can, therefore, reap valuable organic traffic.
NEXT STEPS
Here’s what you can do now:
- Contact us.
- Receive a personalized plan from us to deal with your indexing issues.
- Enjoy your content in Google’s index!
Still unsure of dropping us a line? Read how technical SEO services can help you improve your website.
[/blog_grey_background]

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!