Introduction
JavaScript SEO research is highly dynamic, and a lot has changed since I published my JavaScript Experiment that exploded in the SEO community. The follow-up to the experiment resulted in many hours of research and reaching out to hundreds of experts who struggled to find the problem.
Through that research, I created and published a guide to JavaScript indexing. This only highlighted a massive gap in our (SEO community) knowledge about JavaScript indexing. It also revealed that JavaScript as a topic is still new and undeveloped even for the Googlers who are actively dealing with it.
JavaScript indexing seems to be much easier now after all that research. And while that sounds awesome on paper, it only made JavaScript SEO more complicated. This yin yang approach to my research is exactly why I was hesitant to write about JavaScript crawling in the first place, as one answer introduces numerous new questions.
There is no SEO without crawling. If a crawler doesn’t visit your content, it doesn’t exist in a search engine, which is why crawling is paramount.
You also need to be mindful of your crawl budget – the number of pages Googlebot will regularly crawl based on the size and cleanliness of your site, as well as the number of links directing the crawler to your site.
Optimizing it has been a hot topic over the last couple of years, and, unfortunately, as my recent experiment revealed, the difference between crawling HTML and JavaScript has a dramatic impact on the crawl budget.

A Different Crawling Experience
To get started, let me explain a couple of basic concepts.
[Please note: Some of the concepts, like JavaScript execution, are simplified in this article for the sake of allowing non-developers the opportunity to better understand this subject.]
There are three pieces of the puzzle in JavaScript SEO:
- Crawling
- Indexing
- Ranking
You can’t really get to #3 without #1, etc. If you want to understand the difference between crawling and indexing, please read this great article by Barry Adams.
[It’s indexing, by the way, and not indexation. Indexation means something completely different. If you’re unsure of the difference, use indexation when writing about this subject on Twitter and then tag Barry Adams. You’re welcome.]
We can compare the difference between crawling HTML and JavaScript to driving a smooth highway vs. a muddy, uphill off-road.
Crawling and executing HTML is as simple as it gets. All the content is visible in HTML, and the only “extra step” needed to index the content is executing CSS to see the styles.
With JavaScript websites (client rendered JavaScript), the whole process is MUCH more complex. First, the browser (or Google’s indexer) must process JavaScript to “change it into” HTML and index the content.
Executing HTML
- Download HTML & CSS in parallel.
- Wait for CSS to finish downloading and execute it.
- Render, and continue rendering as HTML downloads.
vs.
Executing JavaScript
- Download HTML (it’s tiny).
- Download CSS and JS in parallel.
- Wait for CSS to finish downloading and execute it.
- Wait for JS to finish downloading and execute it.
- (In many cases, Single-Page Apps (SPAs) wait until this point to start downloading data).
- Update the DOM & render.
Whether you understand it all or not, clearly, you can see the problem with the additional steps with JavaScript. To simplify the above problem, let’s paraphrase Jake Archibald from Google: “Less code = faster execution.”

[BTW, I highly recommend reading this case study of removing JavaScript to improve performance by 50%. This is a must-read article for everyone who wants to go with a client rendered JavaScript (React, Angular, etc.) website.]
As you can see, JavaScript has to complicate crawling. Googlebot is kind of a browser, too; after all, “web rendering is based on Chrome 41.” And there is no magic involved in this process, as it has to go through the same steps as any of the other browsers to see the content “hidden” behind JavaScript.
A New Experiment
Now that you know the fundamental difference in crawling and indexing JavaScript vs. HTML, you are probably wondering how this affects your crawl budget (at least I did) 😀
In previous experiments, I noticed a lot of problems with Googlebot not visiting every URL. I often had to manually fetch URLs to “invite” Googlebot to visit them. However, I never had such a problem with HTML.
Googlebot would even eagerly go through terrible thin content, as well as slow and ugly HTML pages. When it comes to HTML, Googlebot is like a dog inside an all-you-can-eat restaurant; even if the food is terrible, that dog is going home happy. Unfortunately, this doesn’t seem to be the case with JavaScript.
This led me to create a new experiment (multiple experiments, actually, but we’ll get there).
I must admit that I didn’t go all out with the experiment and stripped it down to be as simple as possible. I created an HTML website and a client-rendered JavaScript website with similar content generated by artificial intelligence from Articoolo.
The structure of all the websites in the experiment was the key to measuring crawling efficiency.
Each page had only one link, which looked something like this:
Homepage -> page1 -> page2 -> page3 -> page4 -> page5
Thanks to this structure, I was sure that if, for instance, page5 was crawled, this meant that Googlebot also had to go through the homepage, page1, page2, page3, and page4. There was no other way for Googlebot to find those pages (no sitemaps, etc.).
So how did Googlebot do?
Experiment Results
The differences between the HTML and JavaScript pages were considerably different.
HTML page
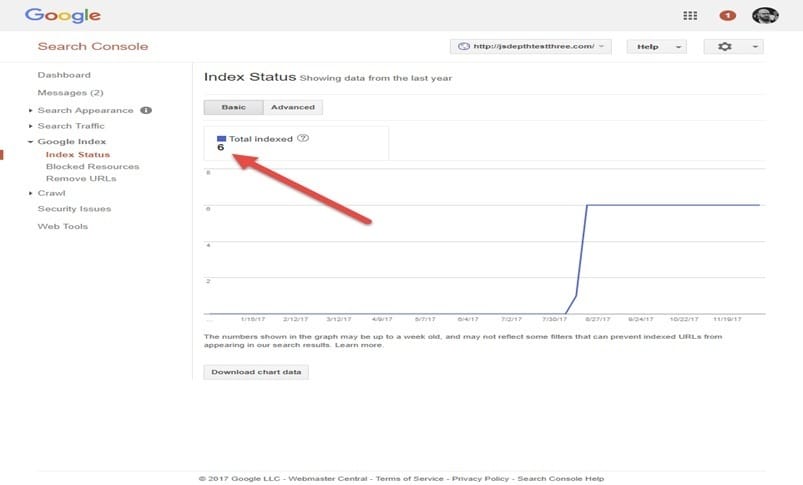
The HTML-based pages were crawled and indexed within a couple of hours. Google Search Console started showing six indexed pages within a week or so.
JavaScript page
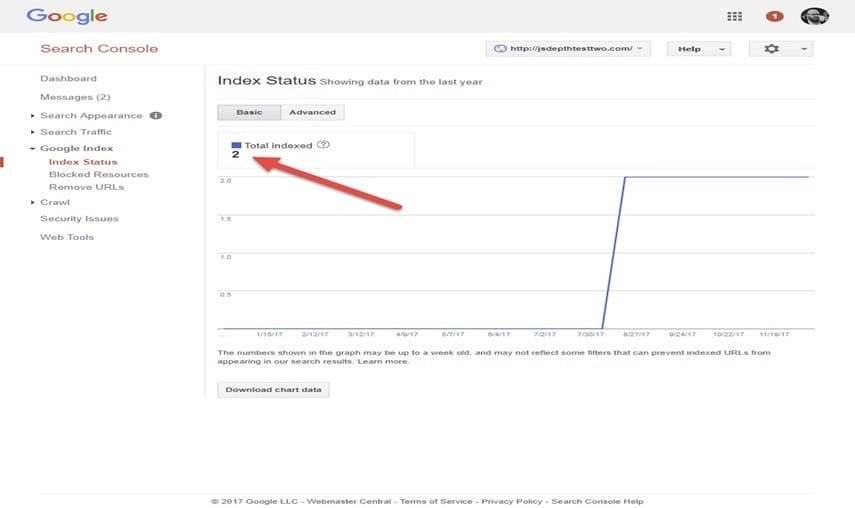
As you can see, it’s been a few months, and even though I shared this website’s URL at many conferences and let the cat out of the bag, Google had still only indexed the website’s homepage plus one content page.
We repeated this experiment over different domains in different configurations (including SPA, which I will write about soon) only to see identical results each time.
Feedback from Google
After seeing the results of my experiment, I reached out to Googler Ilya Grigorik in search of some answers.

He wrote, “I think the trouble here is that we’re conflating ‘crawling JS’ with crawling period…Put differently: ‘didn’t crawl’ doesn’t mean it didn’t crawl because it was JavaScript. Which is to say, there are factors at play here.”
As you can see, Ilya’s response was quite broad. What is worth pointing out is how he mentions that “there are factors at play” without going into detail about what they actually may be.
It’s almost as if he is insinuating that he knows what they are, but he’s certainly not going to be sharing them with me.
I then shared both websites in “JavaScript sites in Search Working Group” created by Googler John Mueller, along with my question regarding the possible factors affecting our test websites.
I quickly got an interesting reply from John Mueller:
“Hi Bartosz
I suspect you’re seeing a combination of things there, but nothing related to “crawl budget.” People refer to “crawl budget” as more a matter of how many URLs we can request from a host before we start causing problems through those requests (slowing the server down, server errors, etc.). Most hosts don’t have limitations in this regard. We can fetch as many URLs as we want (which might not always be a lot, especially if we don’t care about the site that much) from them without running into limits like that. JavaScript comes into play there in the sense that it’s an additional URL that needs to be requested to render a page, among all of the CSS, other scripts, APIs, images, etc. I don’t think I’ve ever seen a situation where one additional embedded resource causes an issue with the overall crawling and indexing of a website (many sites have >100 embedded resources on a page — definitely not great, but one more or less won’t change anything).

What you’re seeing is probably (I ran pretty much the same test last year :)) mostly:
– Rendering takes a bit of time, so there’s a delayed effect when it comes to discovering links that are added via rendering. This is primarily a temporary effect, though, once discovered, it’s the same as any other link.
– Test sites are inherently artificial in nature, and our algorithms tend to get bored with them quickly. That makes this kind of test a bit hit & miss or look worse than it would be in practice.
Anyway, it’s cool to see these kinds of tests. Thanks for sharing them & the results!
Cheers
John”
John’s reply is interesting; however, I don’t think it solves the problem I am seeing across all the test domains. John’s point that the crawl budget is based on host load is logical, but if you ever worked with a large domain, you already know how difficult it is to get Googlebot to crawl your new content. I wish it were based on host load only. I also think it’s telling that John mentioned that he ran a similar test, but he’s not sharing the results.
Summary
This is one of those articles that I’ve been putting off writing forever as I’ve been constantly searching for more data because, like I said at the beginning, each experiment result provides an answer with even more questions. Are “there other factors at play here”? Are we dealing with algorithms that “tend to get bored”? Or is there something else we’re missing?
Either way, based on the information in this article, I remain confident that JavaScript is killing the crawling budget.
This is a topic I will be continuing to explore and will, of course, share any new discoveries my research brings to light.
January 8, 2018 Update:
After publication, John Mueller reached out to us to clarify some of the points addressed in this article. So take it away, John:
“Hi! I just thought I’d send you a short note regarding [your article] – nice summary & graphics, btw! I think conflating crawl budget with what you’re seeing is wrong & kinda distracts from your message. Crawl budget (from our POV, & from what people generally view it as) is the # of URLS fetchable from a server/time, which includes JS, CSS, etc. It’s a technical limitation of how much can potentially be fetched from a server, and that doesn’t change depending on the type of content that it is. What you’re seeing is a change in rate of *indexing* from following links – there I agree that things are slower with sites that require JS in order to see the links. The difference is subtle, but if you know what kind of problem a site has (crawl rate vs. indexing rate), the actions you could take to fix the problem are very different.”







