
The Internet is omnipresent and has had a revolutionary impact on our everyday lives by providing us with incredible possibilities. Since its development over 50 years ago, it’s been estimated that more than 46% of the global population has internet access. It’s incredible, especially when you consider that only 10% of the global population was using this technology just 15 years ago.
The story of the Internet as we know it began in the early 1960s at the US Department of Defense with the ARPANET (Advanced Research Projects Agency Network) project. Just a few years later, in 1969, this technology was also being implemented in the academics environment at the University of California and the Stanford Research Institute. Despite the Internet being known in defense and academic circles for decades, it didn’t take off until it moved into American households in the early 1990s. The 21st century’s introduction of Wikipedia, YouTube, and Facebook helped shape the Internet into the recognizable landscape we know today.
However, even though our lives are completely entwined with the Internet, where we watch movies, connect with friends, and order our favorite pizza, the vast majority of users do not even know how this technology works.
In this article, I want to take a close look at some of the technology behind the Internet everyone knows and explain what really happens from the moment you type in “google.com” – or your favorite website for that matter – in your address bar until the moment it appears on your screen.
The Internet from scratch
The Internet as a large spider web or net is cliched at this point, but such imagery is certainly not accidental. The Internet is, in fact, a giant network where all the devices (computers, servers, tablets, etc.) are connected. And while they do create a network similar to a cobweb, the reality is infinitely greater and more complicated.
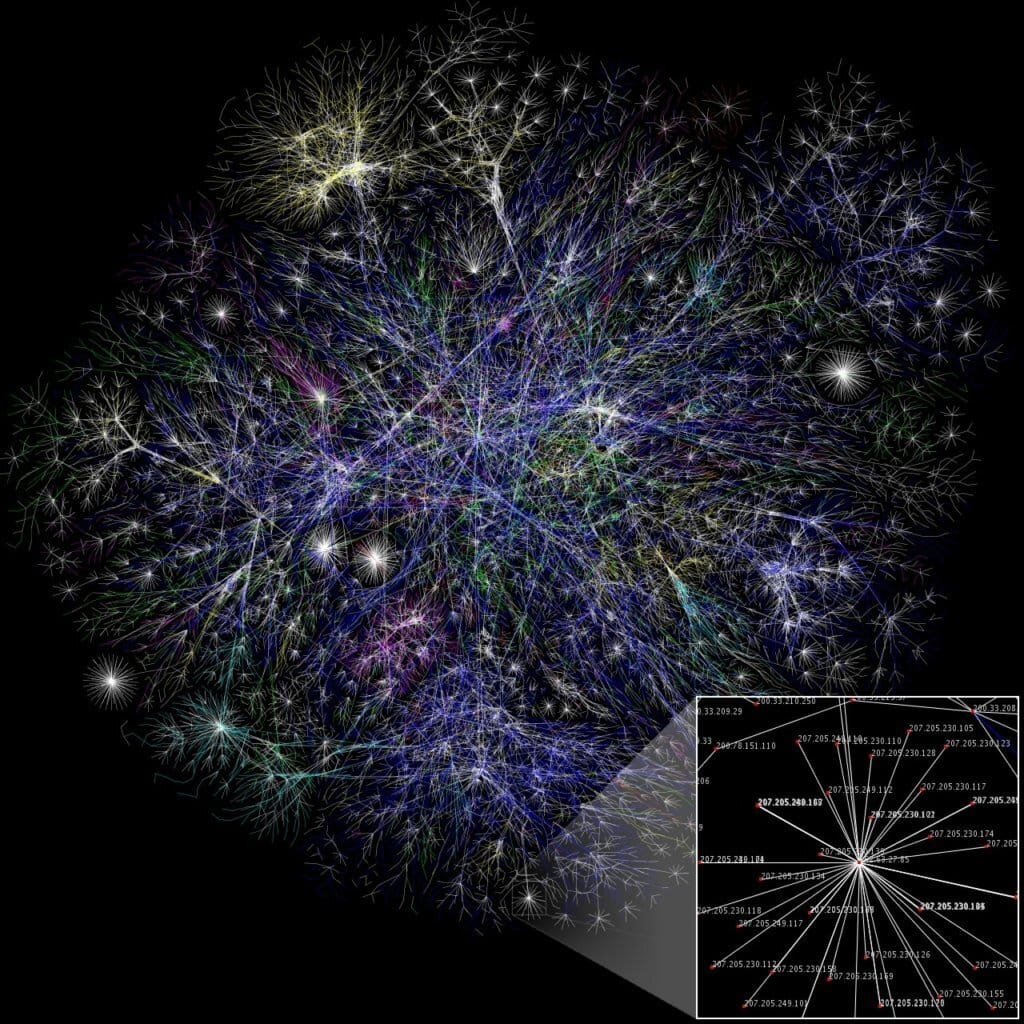
Now that we have our visualization of the Internet, we need to consider some of the factors that are required to make all of this work, such as protocols.
Protocols
End devices connected to the Internet (computers, smartphones, tablets) must have a general standard about their communication. We can imagine that they need to “speak” the same language to understand each other. They are called protocols.
TCP/IP Protocol
The most basic protocol is the TCP/IP rule. It’s possible to split them into TCP and IP parts.
TCP is an abbreviation for Transmission Control Protocol. It enables computers to connect with each other and transfer data into packages. The main rule for this type of communication is to split bigger data into small pieces and send them separately from point A to point B on different internet “roads” at the same time. When all the needed data is received, then the computer puts all the pieces back together.
This type of transmission is faster, more independent, and less sensitive to errors than others. Each piece of data is sent separately. But what if some packages are lost? Then the small missing packages are sent again. It doesn’t take as much time, and it’s unnoticeable to the user.

You might be asking yourself how the computers know where to send the packages. The IP protocol takes care of that. An IP address, in other words, is the unique number of a computer or server. When you want to send or receive data, computers need to know the “language” which they will communicate with and which device they should speak to.
HTTP – Deeper Communication
The next thing you should know is HTTP. The HyperText Transfer Protocol enables computers and servers to communicate and exchange data via the World Wide Web (www). It’s a set of rules for transferring data in the application layer (your browser/device shows the webpage you want). Each time your browser asks a server for info (HTML, JavaScript, CSS, images, videos, etc.), it makes an HTTP request.
To make it clear and simple, both protocols (HTTP and TCP) work at the same time in most cases. However, their roles are completely different. We can say that TCP/IP is responsible for delivery (like a courier track), and HTTP is for the format of packaging (courier package).
Cache – the game changer
Cache is the next thing you should know about. This is an important aspect that has a significant influence on the speed that a website renders. Writing very briefly, a cache is a place where computers/servers/apps store temporary files. Thanks to that, access time is reduced to the minimum – the user does not need to download from the origin server the same unchanged files (like CSS, JS, or images) when they want to display the same website for repeat viewings.
This aspect is used to improve website performance, of course. Such files are stored in different places like a computer browser, ISP (Internet Service Provider) server or a destination server (for example, the server of your favorite webpage).
Users don’t even think about it, but cache makes their lives easier, literally. One of the most often used and useful caches is the one in your browser. It creates faster web browsing. Every modern web browser (Chrome, Opera, Mozilla, Safari, etc.) improves your satisfaction by using the cache feature.
Using cache has mainly two purposes:
- To reduce the bandwidth and process the requirements of the web server.
- To help improve the responsiveness for users of the web.
If you’re curious to see how it works in Chrome, write “chrome://cache/” in the address bar. You will find all the temporary files already saved in your browser – JavaScript files, fonts, images, graphics, etc.
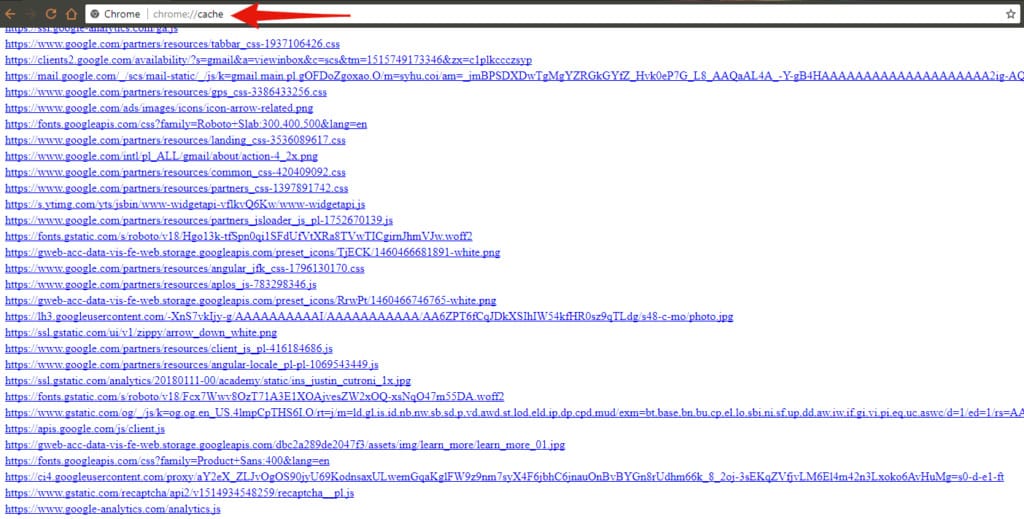
All of those files make your browser work faster. You do not need to download some files every time you connect with a given website since fonts, CSS or graphic files rarely change.
Rendering a webpage – step by step
Now that we understand how it all connects, let’s take a look at how a webpage is rendered; meaning, how all of these factors create a visual image that you see as a webpage. For the purposes of this article, I’ll be simplifying the whole process as much as possible and thus making it seem shorter than it is in reality. Let’s use the google.com case:
Step 1 – The computer connects with the ISP server
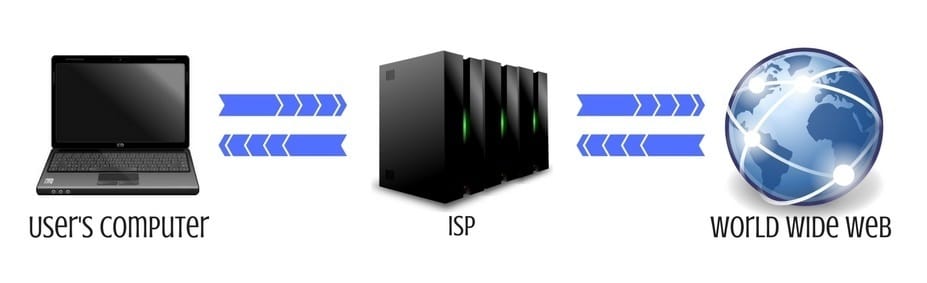
Right after you type the address into your website’s browser (f.ex. “google.com”), your PC is setting up the connection with an ISP. This is your Internet Service Provider, and every single one of them has its own dedicated server. For you, it’s kind of a gate to the whole world wide web. Every single step is made through your ISP.
Step 2 – The ISP connects with the DNS
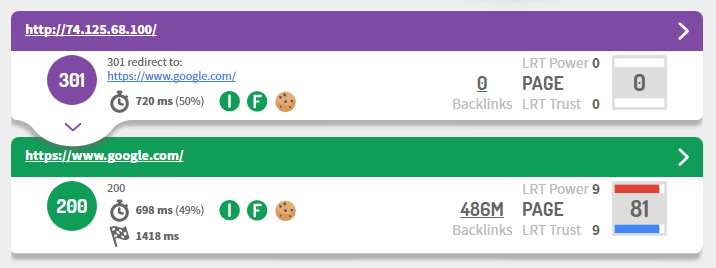
The thing that needs to be done is to change the domain name (google.com) into an IP address – in this case, 74.125.68.100. We can compare it to a phone number, but more computer oriented. Your browser needs to know which server responds with the data you expected. That is why your browser asked for the DNS (Domain Name System) for changing the written domain name (in this case, “google.com”) into the given punctuated numbers.
Try to copy and paste “74.125.68.100” in your address bar instead of google.com, and you will see that you will be redirected to https://www.google.com/.
All Internet users know a lot of domain names like Google, Forbes, Yahoo, and hundreds more. It’s incomparably easier to remember domain names than IP addresses. That is why DNS servers are so important for us – humans.
Step 3 – The DNS responds
The next step is the DNS response, indirectly via your Internet provider’s server. Finally, your browser receives information from the DNS about the already changed domain name into the IP. For now, your browser knows your intention – writing “google.com” in the address bar means a connection to 74.125.68.100.

Step 4 – The user’s browser connects with the destination server
After receiving information from the DNS with the IP address, your browser connects with an origin server and asks for specific data.
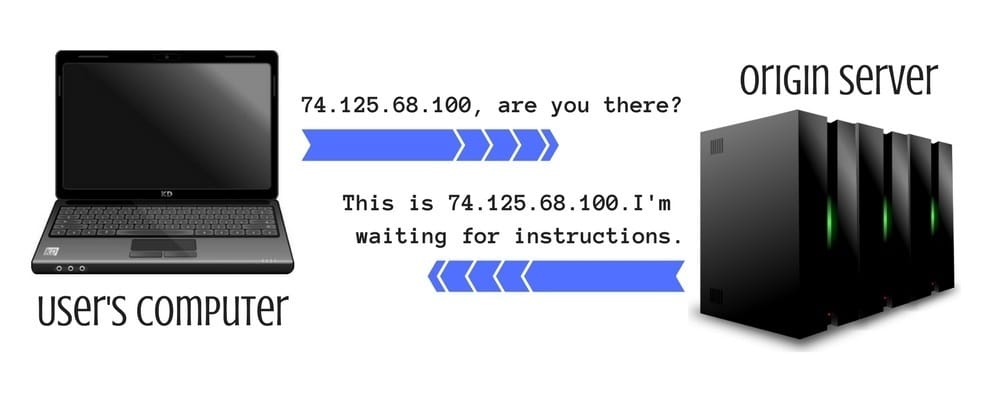
Step 5 – The server responds with the needed data
At the very beginning, the server sends a general structure of a website (HTML file). After that, it sends additional data like pictures, videos, Java Scripts, CSS files, and much more. In this step, you should remember that the smaller size of data sent and received, the shorter the overall loading time is.

Step 6 – Additional communication between the user and server
At the last step, after finally rendering an up-to-date version of the requested web page, you will probably request additional data, e.g., other pages or files. Then the browser connects and requests more data directly, without a connection with the DNS and constantly updating cache files.
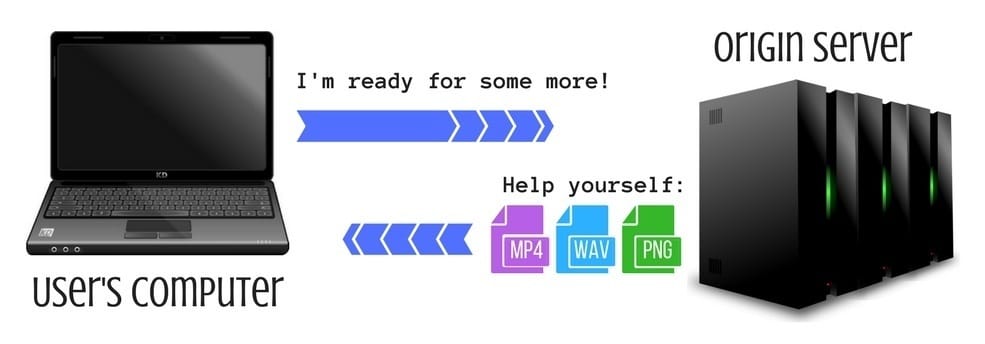
Most importantly, the proper configuration of the cache helps to improve the user experience since it is saved at several levels – the user’s browser, Internet Service Provider and end-host server.
Conclusion
Now you should have a good understanding of the main principles of how the internet works, how everything is able to connect, and how you’re able to see a rendered version of your favorite website. In my next article, we will take another look under the hood and see how we can maximize website performance based on the information I’ve just provided for you.
Understanding the basics of how the internet works is the first step to taking care of technical SEO on your website. We can help you with that! Just contact Onely and check our technical SEO services.







