“Page indexed without content” is a Google Search Console status that means your page is indexed even though Google couldn’t find or read its content.
Do you see this status in your Page indexing (Index Coverage) report, but you’re unsure how to approach it?
You need to know that although the “Page indexed without content” issues may be relatively rare to encounter in Google Search Console, when they keep arising, it’s a sign that you should take a closer look. That’s because if there’s content on the page that should be indexed but isn’t, the page won’t perform well on Google.
Unfortunately, the information you may find about this status is often limited or conflicting. But don’t worry – I got you fully covered, so read on to learn about the possible causes and solutions.
Causes for “Page indexed without content”
If you see the “Page indexed without content” status in your Page indexing (Index Coverage) report, it indicates that Googlebot couldn’t find or access your content but indexed your page because of extensive internal and external linking pointing to the URL.
And if you’re wondering how a page can be indexed without content, let’s analyze how Google approaches pages in the indexing pipeline.
When Google discovers a page on your website, it goes through the robots.txt file to ensure it can visit a URL.
The general idea of using robots.txt is that it indicates what pages bots shouldn’t visit. In other words, if your URL is blocked within robots.txt, Googlebot shouldn’t crawl it and see your content.
Of course, it still may happen that the URL you blocked in robots.txt gets indexed. Ania Siano described that case in her article on the “Indexed, though blocked by robots.txt” status.
On the other hand, if your URL is crawlable and indexable (meaning you don’t block it with robots.txt or the noindex tag):
- Googlebot can freely visit it, and
- If it finds it valuable – add it to the index.
However, an important thing to remember is that, according to John Mueller, “A page’s content doesn’t need to be indexed for a page to be indexed (…).”
That’s why one of the cases when you can see this status is when you publish a page without content by mistake or remove the content leaving a blank page for users within the indexed URL.
However, if bots have valid reasons to index a URL but, for some reason, they can’t access or process your content, such a page may also be considered “Page indexed without content.”
There are actually a few reasons why Google may think your page has no content, even if it actually contains some. Let’s dive in!
Google can’t access or process the content
One of the reasons is that your page is published in a non-accessible format for Google, so it can’t read it.
According to Google’s official documentation, to see your textual content on Google, it needs to be published in one of the indexable file types.
Another case is when Google thinks that your indexed page has no content due to server-related issues on your side.
Here’s when Google can’t process the content because, for some reason, your server blocks bots from seeing it.
In other words, it’s like Google doesn’t have any additional information about your page, e.g., it may not recognize either the content type or the HTTP response.
Here’s how you may see such a page when inspecting the URL in Google Search Console:
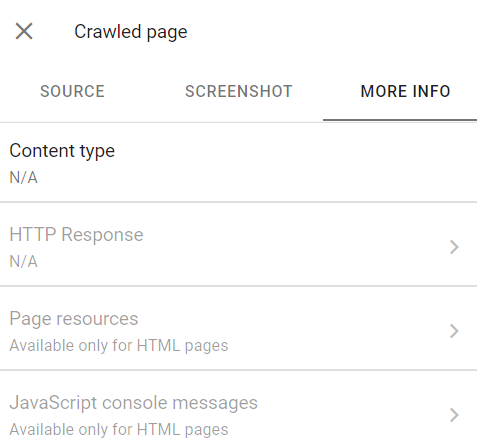
In this case, contact your developers to track down the possible cause of the issue.
Cloaking
Another reason why Google might assign your page to the “Page indexed without content” status is when you show different content to users and bots. With some exceptions, this is considered cloaking and goes against Google’s guidelines.
Why is cloaking problematic for Google? In this case, Google can see the content on your page, but it finds out that there are actually two versions of it – one for users and another for bots.
As a result, Google gets suspicious, as it considers such behavior a form of spam “(…) with the intent to manipulate search rankings and mislead users” and may not want to index a given page’s content.
According to John Mueller, cloaking can poorly impact user experience as users see different content than they were promised on SERPs:
On the other side, some webmasters may use cloaking to show keyword-rich content only to bots in hopes of better rankings. However, fooling Google may have severe consequences.
In both these cases, such an approach may result in a manual penalty.
We covered that topic before on our blog. Read Ania Siano’s article about manual actions and how to deal with them.
Rendering issues
To fully understand the context of your page and serve it to users on SERPs, bots need to render your content.
However, it may not be possible if you’re blocking some important files in your robots.txt.
And, although official Google documentation on the Page indexing (Index Coverage) report says that “Page indexed without content” “(…) is not a case of robots.txt blocking,” I feel it needs some clarification.
The statement above is true when it refers to blocking URLs. But blocking, e.g., JavaScript or CSS resources in your robots.txt may actually contribute to the “Page indexed without content” issues.
In other words, if the URL is crawlable and indexable, but you blocked important files in robots.txt:
- the page can be indexed, but
- search engine bots won’t be able to access and analyze its content.
It means that Googlebot won’t fully render your page as you didn’t give it access to your essential resources.
Moreover, remember that even if you’re not blocking any crucial files in your robots.txt, your pages may still struggle with rendering issues, making it impossible for Google to see your content.
It’s especially the case when you don’t optimize the way you serve your JavaScript-based content to search engines.
Why? Because, sometimes, Googlebot may not be able to handle the cost of processing your JavaScript content on its own and see only a blank page instead of your valuable content.
And when you get rendering messed up on your website, it may bring severe consequences for your organic visibility as Google can’t fully understand what your page is about.
How to find the “Page indexed without content” status in Google Search Console?
You can find the “Page indexed without content” status at the bottom of the Page indexing (Index Coverage) report in Google Search Console in the ‘Improve page appearance’ section.
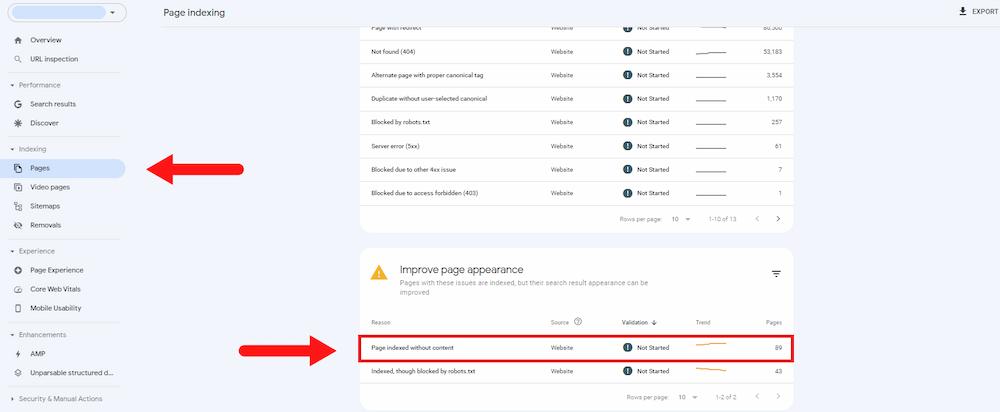
Enter the status page to dive into the list of the “Page indexed without content” URLs. It will also show you the chart on how the number of affected pages has changed over time.
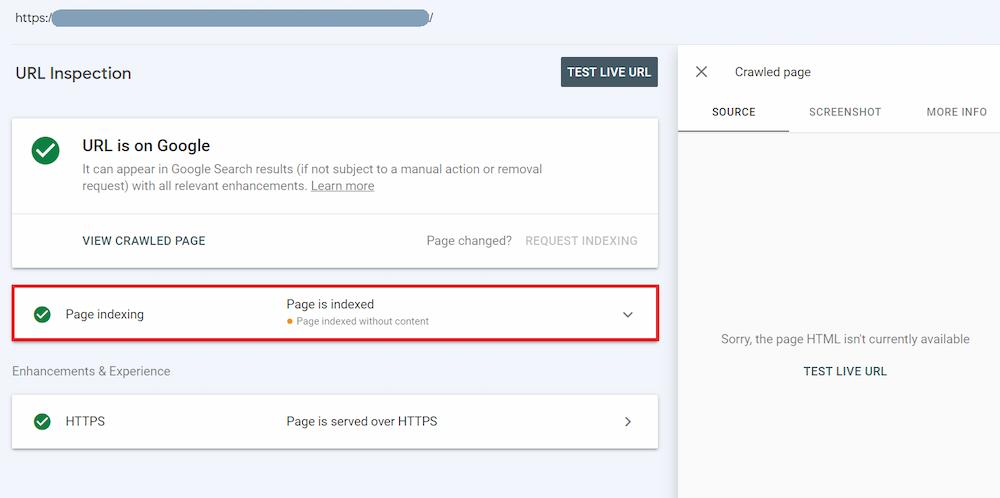
Another way to navigate this issue is to use the URL Inspection tool.
Here you can enter a specific URL on your domain and examine its current status. For “Page indexed without content,” you should see the following information: ‘URL is on Google’ and “Page indexed without content.”
Also, by clicking on ‘View crawled page,’ you may check how Googlebot sees the affected page. However, in the case of “Page indexed without content,” additional information like the page HTML, screenshot, or more info on page resources may not be available.
How to fix “Page indexed without content” in Google Search Console?
Browse the list of affected pages in Google Search Console
The initial analysis of the “Page indexed without content” URLs in Google Search Console may help you decide on the next steps.
Looking at the lists of the affected pages for our clients, the “Page indexed without content” issues were primarily empty pages.
If it’s also the case for you, it may be a good moment to rethink your indexing strategy and consider whether these pages should still be indexed.
Analyze internal and external linking
Extensive external and internal linking might be confusing for Google if you published a page without content by mistake or removed the content and didn’t take any action to optimize that URL.
Why? Because when Google sees many links to a given page, it considers it essential and is more eager to get it indexed even if it doesn’t include any content. This way, bots may use up their limited resources, wasting your crawl budget, and not want to crawl your other pages with valuable content.
To thoroughly analyze how bots flow through your website, perform a log analysis with an SEO crawler like Screaming Frog.
You may consider different solutions depending on whether: Decide on the next steps
Compare how your page is seen by users vs. Googlebot
Even if your page looks completely normal when you look at it in your browser from a user perspective, it may look different for bots.
And as you already know, it may be especially dangerous if Google considers such behavior cloaking.
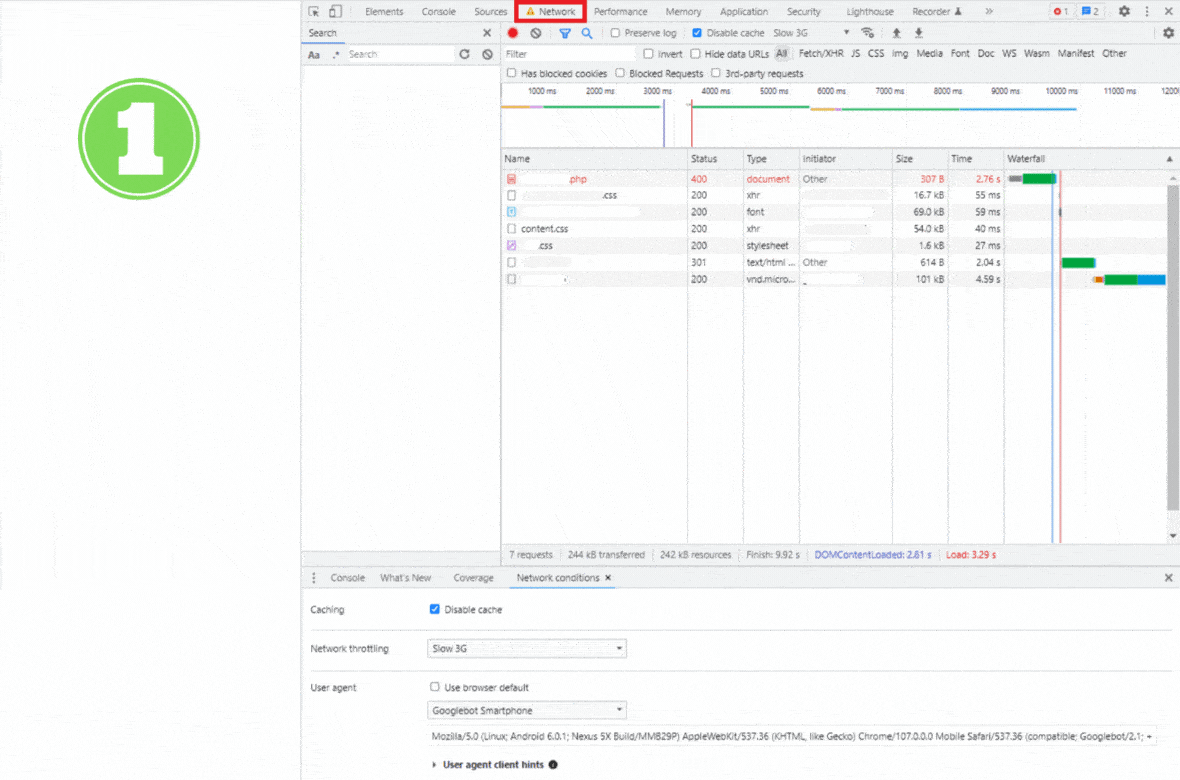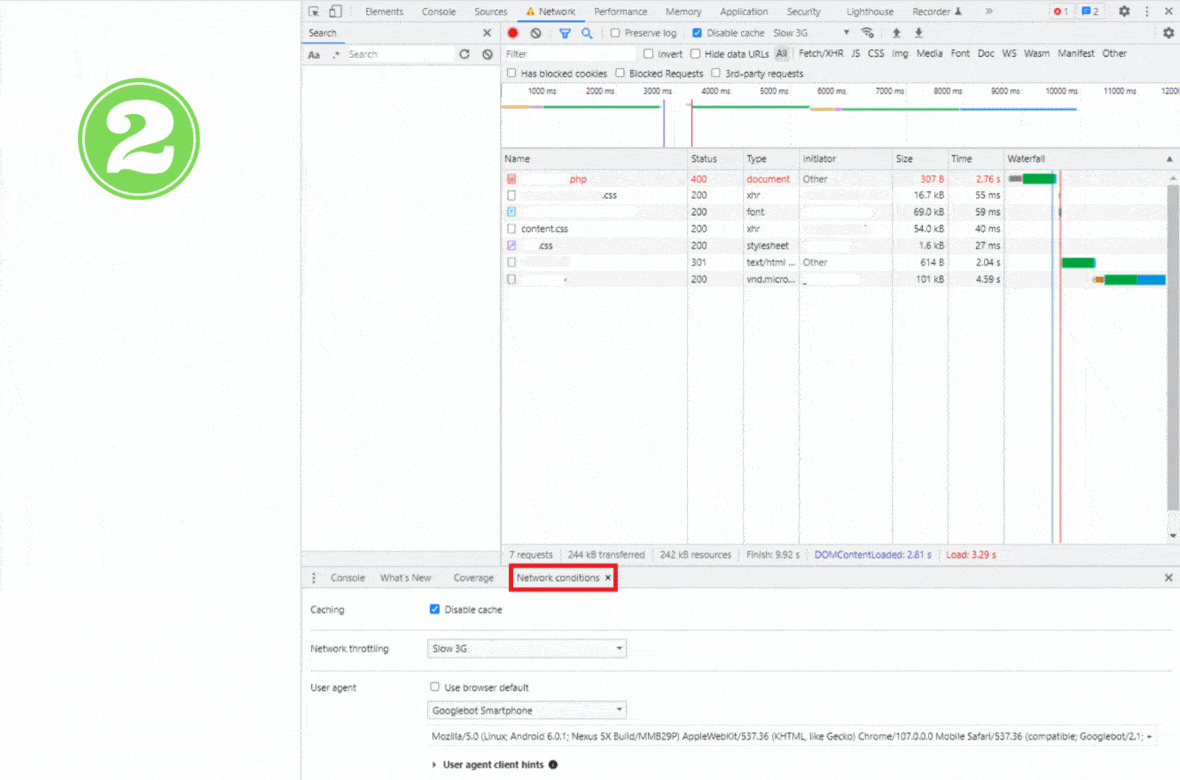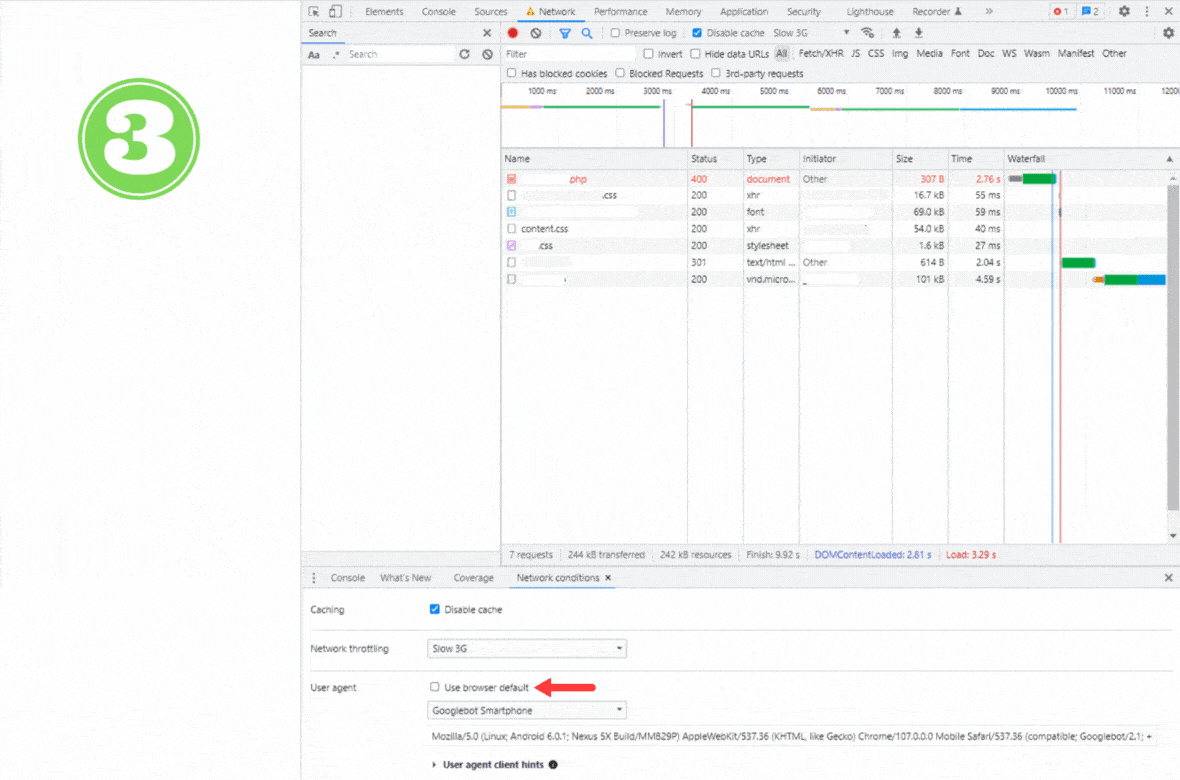
To diagnose if this may be the case for you, simulate Googlebot User Agent in Chrome Dev Tools to find out how Google sees your affected page.
Go to the ‘Network’ tab and open ‘Network conditions.’ Next, unclick ‘Use browser default’ in the User-agent section and choose ‘Googlebot Smartphone’ from the drop-down list.
Then, refresh the page (you can use the Ctrl + Shift + R shortcut on Windows) to ask your browser to serve the version of a page that Googlebot sees.
If this version of your website significantly differs from what you show users, it may imply that Google thought you were trying to hide something from it.
To fix it, remove or change content that users and Google see differently to ensure you show them one version of your website.
However, remember that even if you didn’t make any changes to your content on purpose, cloaking might often result in a hacking attack on your website. In this case, follow Google’s recommendations on fixing the hack to navigate the issue.
Troubleshoot rendering issues
As you already know, blocking essential resources in robots.txt may contribute to your rendering issues.
To troubleshoot this, go through your robots.txt file and check if you’re not blocking, e.g., any JavaScript or CSS files that may influence how your main content is generated.
However, I understand that if you’re managing a large website, going through the Disallow directives in robots.txt manually may be a long and error-prone process.
In this case, you can use the Mobile-Friendly Test to check how your rendered source code looks for Google. The tool will also provide you with a screenshot of your page’s rendered mobile version, which can give you an insight if bots see your content differently than users.
To do this, insert the URL into the tool and choose ‘View Tested Page.’
In the right-hand side panel, pay particular attention to the ‘Page resources’ section. It will show you any resources that couldn’t be loaded and let you know about the cases where Googlebot is blocked by robots.txt.
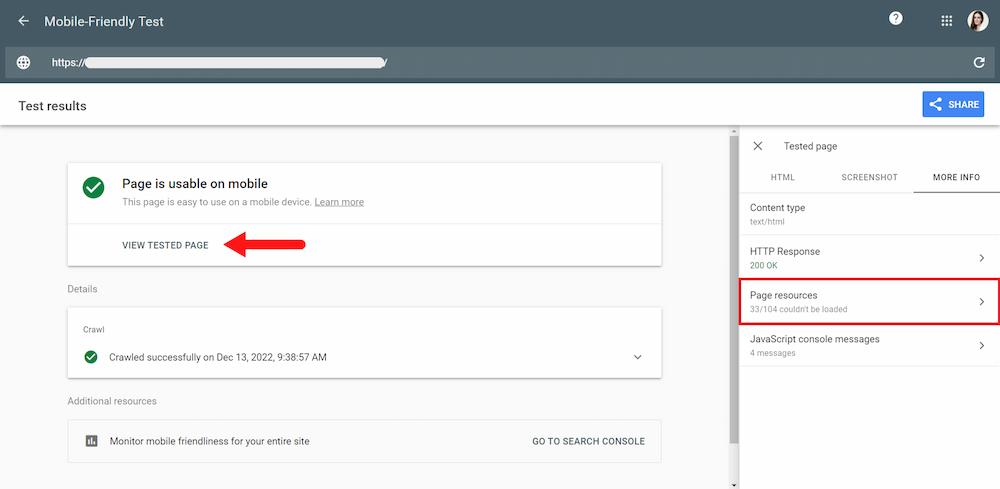
As it turns out, blocking important JavaScript files is quite a common mistake, even on modern and large websites. I described a similar case in my article on 4 common mistakes eCommerce websites make using JavaScript published on Moz.
Don’t lose your opportunity to expose your content to Google. Reach out to us for our Rendering SEO services to ensure Google can see and process your valuable content. Struggling to get your pages fully rendered?
Have you seen “Page indexed without content” in your Google Search Console, but it disappeared without any explicit action on your side? Here’s one more thing you need to know.
It might happen that Google revisited your pages and changed how it evaluates them. In this case, it most likely put such URLs within the “Crawled, currently not indexed” status.
Another thing is that Google is not consistent in assigning issues to corresponding statuses in Google Search Console. It means you may encounter pages that should belong to different statuses within the “Page indexed without content” status.
And all of that makes diagnosing your issues even more complex, especially if you’re managing a large website without any SEO guidance.
Here’s what you can do now: Still unsure of dropping us a line? Read how technical SEO services can help you improve your website.NEXT STEPS
Wrapping up
Google defines the “Page indexed without content” status as a non-critical issue where an affected page is indexed, but for some reason, Googlebot couldn’t access or process its content.
And although the affected URLs can be found on Google, you still shouldn’t ignore them.
Because if you don’t take action to fix the “Page indexed without content” issues, the lack of visible content may contribute to the chaos that can cost you search visibility.
Get to the core of the problem to prevent:
- Ranking issues as bots can’t understand your page and serve it for specific user intent, and
- Worsen user experience and increase bounce rates as users can’t proceed to explore your website with a blank page.
Contact us for a technical SEO audit of your website to navigate any problems that may stop bots and users from seeing your content.

Hi! I’m Bartosz, founder and Head of Innovation @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with your organic growth – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!