“Indexed, though blocked by robots.txt” and “Blocked by robots.txt” are Google Search Console statuses. They indicate that the affected pages didn’t get crawled as you blocked them within the robots.txt file.
However, the difference between these two issues is that:
- With “Blocked by robots.txt,” your URLs won’t appear on Google,
- In turn, with “Indexed, though blocked by robots.txt,” you can see your affected URLs in the search results even though they are blocked with a Disallow directive in your robots.txt. In other words, “Indexed, though blocked by robots.txt” means that Google didn’t crawl your URL but indexed it nonetheless.
As fixing these issues lies at the heart of creating a healthy crawling and indexing strategy for your website, let’s analyze when and how you should address them.
What does indexing have to do with robots.txt?
While the relationship between robots.txt and the indexing process may be confusing, let me help you understand the topic in depth. It’ll make grasping the final solution easier.
How do discovery, crawling, and indexing work?
Before a page gets indexed, search engine crawlers must first discover and crawl it.
At the discovery stage, the crawler learns that a given URL exists. While crawling, Googlebot visits that URL and collects information about its contents. Only then does the URL go to the index and can be found among other search results.
Psst. The process isn’t always that smooth, but you can learn how to help it by reading our articles on:
What is robots.txt?
Robots.txt is a file that you can use to control how Googlebot crawls your website. Whenever you put a Disallow directive in it, Googlebot knows it cannot visit pages to which this directive applies.
But robots.txt doesn’t control indexing.
For detailed instructions on modifying and managing the file, see our robots.txt guide.
What causes “Indexed, though blocked by robots.txt” in Google Search Console?
Sometimes Google decides to index a discovered page despite being unable to crawl it and understand its content.
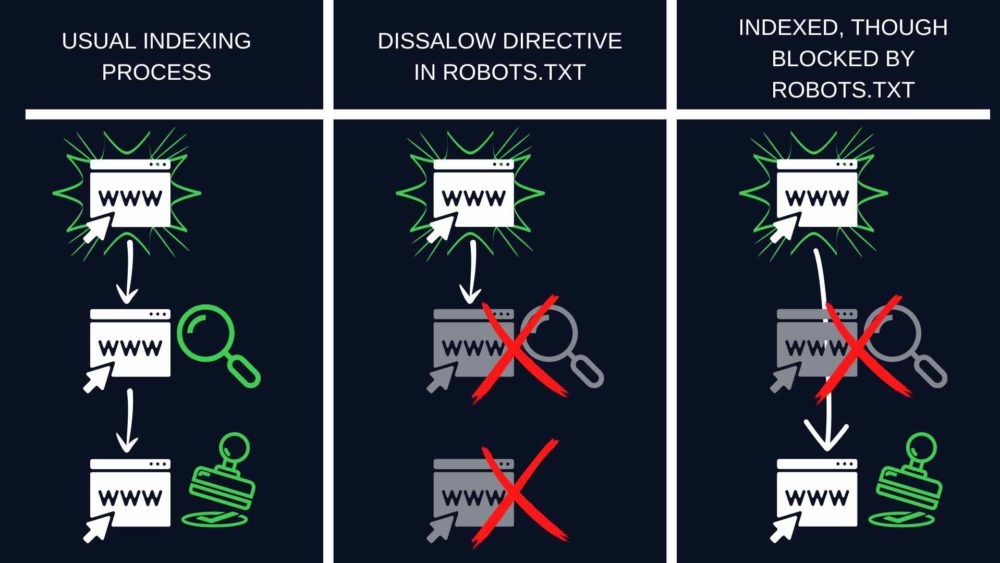
In this scenario, Google is usually motivated by many links leading to the page blocked by robots.txt.
Links translate into PageRank score. Google calculates it to assess whether a given page is important. The PageRank algorithm takes into account both internal and external links.
When there’s a mess in your links and Google sees that a disallowed page has a high PageRank value, it may think the page is significant enough to place it in the index.
However, the index will only store a blank URL with no content information because the content hasn’t been crawled.
Why is “Indexed, though blocked by robots.txt” bad for SEO?
The “Indexed, though blocked by robots.txt” status is a serious problem. It may seem relatively benign, but it may sabotage your SEO in two significant ways.
Poor search appearance
If you blocked a given page by mistake, “Indexed, though blocked by robots.txt” doesn’t mean you got lucky, and Google corrected your error.
Pages that get indexed without crawling won’t look attractive when shown in search results. Google won’t be able to display:
- Title tag (instead, it will automatically generate a title from the URL or information provided by pages that link to your page),
- Meta description,
- Any additional information in the form of rich results.
Without those elements, users won’t know what to expect after entering the page and may choose competing websites, drastically lowering your CTR.
Here’s an example – one of Google’s own products:
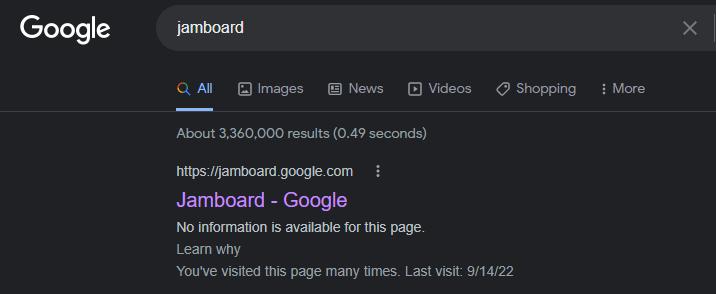
Google Jamboard is blocked from crawling, but with nearly 20000 links from other websites (according to Ahrefs), Google still indexed it.
While the page ranks, it’s displayed without any additional information. That’s because Google couldn’t crawl it and collect any information to display. It only shows the URL and a basic title based on what Google found on the other websites that link to Jamboard.
To see if your page has the same problem and is “Indexed, though blocked by robots.txt,” go to your Google Search Console and check it in the URL Inspection Tool.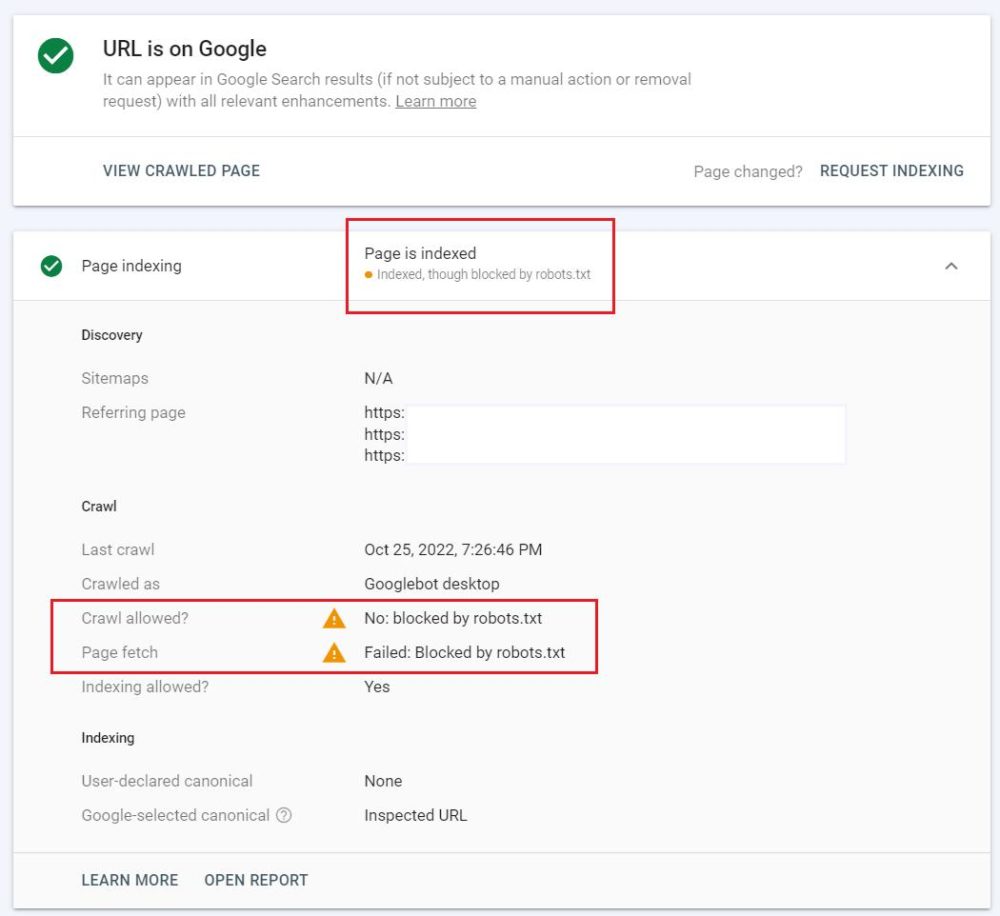
Unwanted traffic
If you intentionally used the robots.txt Disallow directive for a given page, you don’t want users to find that page on Google. Let’s say, for example, you’re still working on that page’s content, and it’s not ready for public view.
But if the page gets indexed, users can find it, enter it, and form a negative opinion about your website.
How to fix “Indexed, though blocked by robots.txt?”
Firstly, find the “Indexed, though blocked by robots.txt” status at the bottom of the Page Indexing report in your Google Search Console.
There you may see the “Improve page appearance” table.
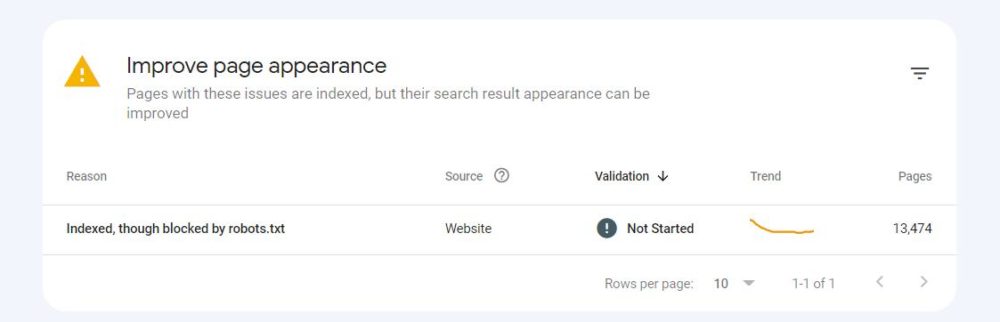
After clicking on the status, you will see a list of affected URLs and a chart showing how their number has changed over time.
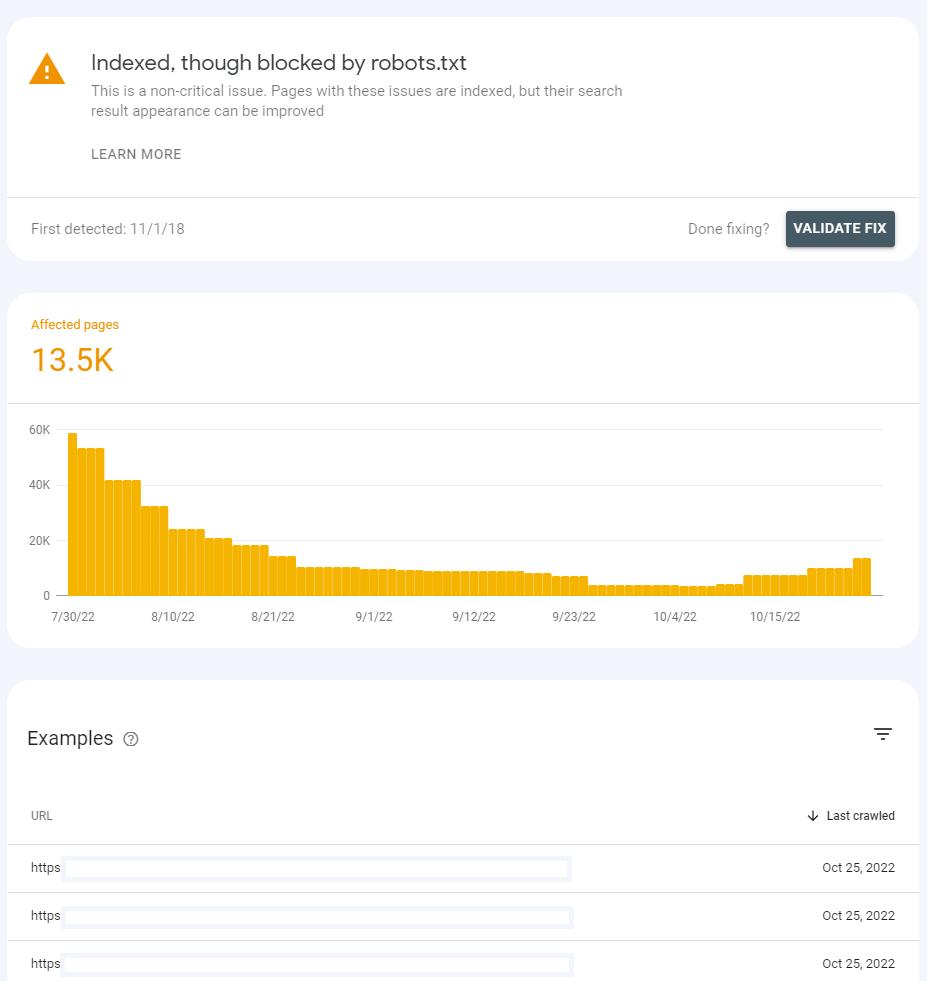
The list can be filtered by URL or URL path. When you have a lot of URLs affected by this problem, and you only want to look at some parts of your website, use the pyramid symbol on the right side.
Before you start troubleshooting, consider if the URLs in the list really should be indexed. Do they contain content that may be of value to your visitors?
When you want the page indexed
If the page was disallowed in robots.txt by mistake, you need to modify the file.
After removing the Disallow directive blocking the crawling of your URL, Googlebot will likely crawl it the next time it visits your website.
When you want the page deindexed
If the page contains information you don’t want to show users visiting you via the search engine, you must indicate to Google that you don’t want the page to be indexed.
Robots.txt shouldn’t be used to control indexing. This file blocks Googlebot from crawling. Instead, use the noindex tag.
Google always respects noindex when it finds it on a page. Using it, you can ensure Google won’t show your page in the search results. You can find detailed instructions on implementing it on your pages in our noindex tag guide.
Remember to let Google crawl your page to discover this HTML tag. It’s a part of the page’s content.
If you add the noindex tag but keep the page blocked in robots.txt, Google won’t discover the tag. And the page will remain “Indexed, though blocked by robots.txt.”
When Google crawls the page and sees the noindex tag, it will be dropped from the index. Google Search Console will display another indexing status when inspecting that URL.
Keep in mind that if you want to keep any page away from Google and its users, it’s always the safest choice to implement HTTP authentication on your server. That way, only the users who log in can access it. It is necessary if you want to protect sensitive data, for example.
When you need a long-term solution
The above solutions will help you remedy the “Indexed, though blocked by robots.txt” problem for a while. It’s possible, however, that it will appear in regard to other pages in the future.
Such status indicates that your website may need thorough internal linking or backlink audit improvement.
What does “Blocked by robots.txt” mean in Google Search Console?
“Blocked by robots.txt” indicates that Google didn’t crawl your URL because you blocked it with a Disallow directive in robots.txt. It also means that the URL wasn’t indexed.
Remember that it’s normal to prevent Googlebot from crawling some URLs, especially as your website gets bigger. Some of them aren’t relevant for search engines for various reasons.
The decision on what pages should and shouldn’t be crawled on your website is a fixed step in creating a sound indexing strategy for your website.
How to fix “Blocked by robots.txt?”
Firstly, head to the ‘Why pages aren’t indexed’ table below the chart in the Page indexing report to navigate your “Blocked by robots.txt issues.
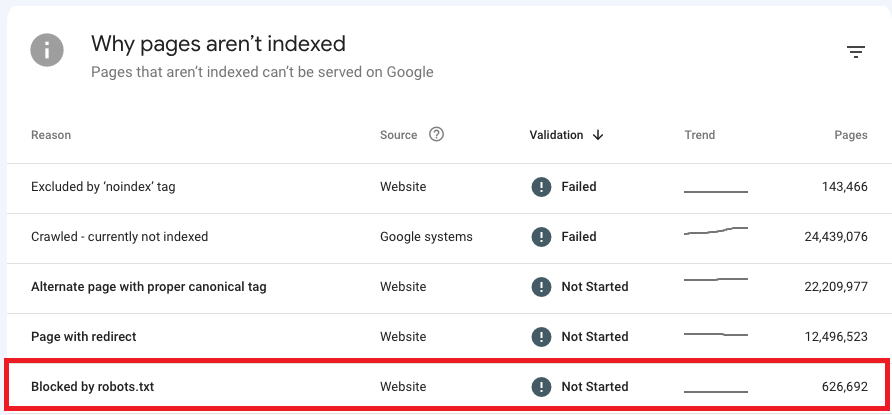
Addressing this issue requires a different approach based on whether you blocked your page by mistake or on purpose.
Let me guide you on how to act in these two situations:
When you used the Disallow directive by mistake
In this case, if you want to fix “Blocked by robots.txt,” remove the Disallow directive blocking the crawling of a given page.
Thanks to that, Googlebot will likely crawl your URL the next time it crawls your website. Without further issues with that URL, Google will also index it.
If you have many URLs affected by this issue, try filtering them out in GSC. Click on the status and navigate the inverted pyramid symbol above the URL list.
You can filter all affected pages by URL (or only part of a URL path) and the last crawl date.
If you see “Blocked by robots.txt,” it may also indicate that you have intentionally blocked a whole directory but unintentionally included a page you want to get crawled. To troubleshoot this:
- Include as many URL path fragments in your Disallow directive as you can to avoid potential mistakes, or
- Use the Allow directive to allow bots to crawl a specific URL within a disallowed directory.
When modifying your robots.txt, I suggest you validate your directives using the robots.txt Tester in Google Search Console. The tool downloads the robots.txt file for your website and helps you check if your robots.txt file is correctly blocking access to given URLs.
The robots.txt Tester also enables you to check how your directives influence a specific URL on the domain for a given User-agent, e.g., Googlebot. Thanks to that, you can experiment with applying different directives and see if the URL is blocked or accepted.
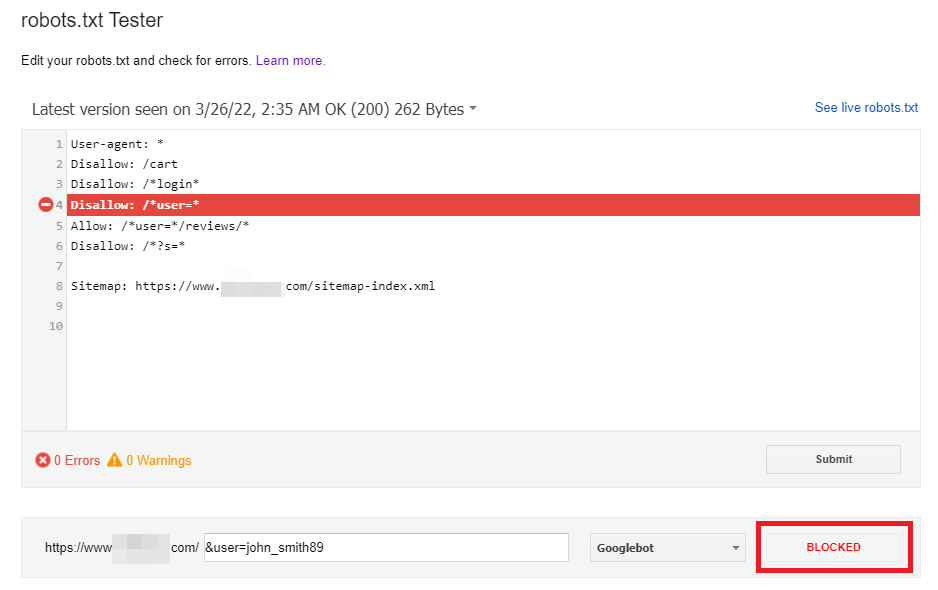
Although, you need to remember that the tool won’t automatically change your robots.txt file. Therefore, when you finish testing the directives, you need to implement all the changes manually to your file.
Additionally, I recommend using the Robots Exclusion Checker extension in Google Chrome. When browsing any domain, the tool lets you discover pages blocked by robots.txt. It works in real-time, so it will help you react quickly to check and work on the blocked URLs on your domain.
Check out my Twitter thread to see how I use this tool above.
What if you keep blocking your valuable pages in robots.txt? You may significantly harm your visibility in search results.
When you used the Disallow directive on purpose
You can ignore the “Blocked by robots.txt” status in Google Search Console as long as you aren’t disallowing any valuable URLs in your robots.txt file.
Remember that blocking bots from crawling your low-quality or duplicate content is perfectly normal.
And deciding which pages bots should and shouldn’t crawl is crucial to:
- Create a crawling strategy for your website, and
- Significantly help you optimize and save your crawl budget.
Here’s what you can do now: Still unsure of dropping us a line? Reach out for crawl budget optimization services to improve the crawling of your website.NEXT STEPS
Key takeaways
- The Disallow directive in the robots.txt file blocks Google from crawling your page but not indexing it.
- Having pages that are both indexed and uncrawled is bad for your SEO.
- To fix “Indexed, though blocked by robots.txt,” you need to decide if affected pages should be visible on Search and then:
- Modify your robots.txt file,
- Use the noindex meta tag if necessary.
- Having the “Blocked by robots.txt” pages on your website is normal if you don’t want bots to crawl these URLs and see their content.
Getting your crawling and indexing right is the foundation of SEO, and a well-organized robots.txt file is just one part of it. Contact us for a thorough technical SEO audit to navigate your issues.

Hi! I’m Bartosz, founder and Head of SEO @ Onely. Thank you for trusting us with your valuable time and I hope that you found the answers to your questions in this blogpost.
In case you are still wondering how to exactly move forward with fixing your website Technical SEO – check out our services page and schedule a free discovery call where we will do all the heavylifting for you.
Hope to talk to you soon!