More than a year ago, on my G+ profile, I posted about something that I found funny: using Scrapebox for white hat. During this year a lot has changed, so now we know we need to focus more and more on the quality of the backlinks instead of quantity. This means that we have to rethink which tools should we use and how they can help us maximize our SEO.
Personally, like Bartosz mentioned in his blog post on LRT, I find Scrapebox very useful for every single SEO task I do connected with link analysis or link building.
Scrapebox – a forbidden word in SEO
I bet everybody knows Scrapebox, more or less. In short – it’s a tool used for mass scraping, harvesting, pinging, and posting tasks in order to maximize the amount of links you can gain for your website to help it rank better in Google. A lot of webmasters and blog owners treat Scrapebox like a spam machine, but in fact, it is only a tool, and what it’s actually used for depends on the “driver”.
Now, due to all the Penguin updates, a lot of SEO agencies have changed their minds about link building and have started to use Scrapebox as support for their link audits or outreach.
Scrapebox – general overview
You can skip this section if you know Scrapebox already. If not – here is some basic information about the most important functions you can use.
Scrapebox is cheap. Even without the discount code, it costs $97. You can order ScrapeBox here.
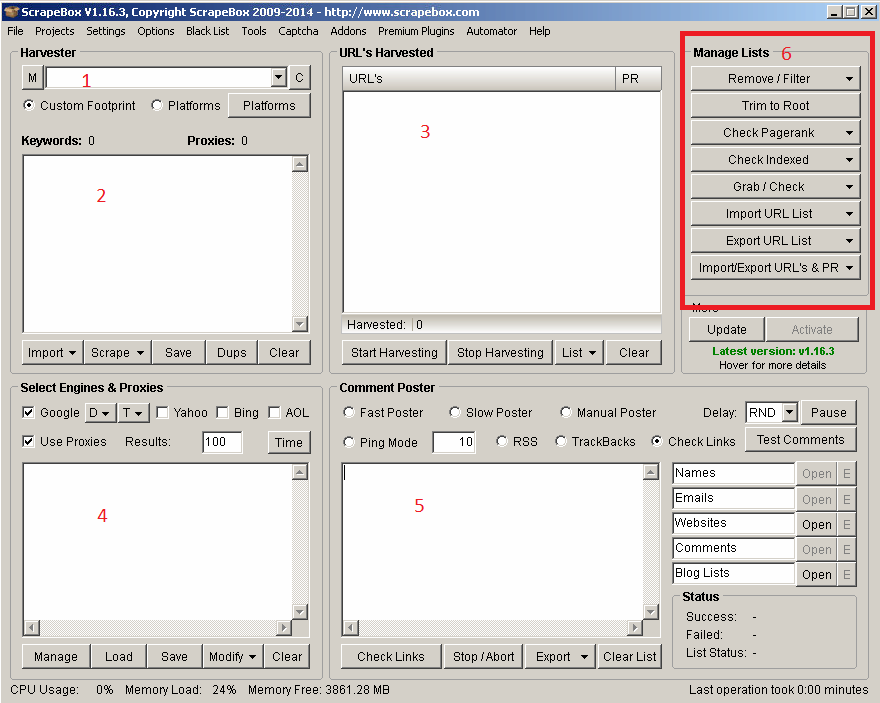
- In this field, you can put the footprint you want to use for harvesting blogs/domains/other resources. You can choose from the Custom option and predefined platforms. Personally, I love to use the “Custom footprint” option because it allows you to get more out of each harvest task
- Here, you can post keywords related to your harvest. For example, if you want to get WordPress blogs about flowers and gardening, you can post “flowers” and “gardening” along with the custom footprint “Powered by WordPress”. It will give you a list of blogs containing these keywords and this footprint.
- The URL’s Harvested box shows the total amount of websites harvested. Using option number 6, you can get even more from each results list.
- Select Engines & Proxies allow you to choose which search engine you want to get results from, and how many of them to harvest. For link detox needs or competition analysis, I recommend making use of Bing and Yahoo as well (different search engines give different results, which results in more information harvested). Also, you can post the list of proxies you want to use and manage them by checking if they are alive, and not blocked by Google and so on. After that, you can filter your results and download them as a .txt file for further usage.
- Comment Poster allows you to post comments to a blog list you have harvested, but in our White Hat tasks – we do not use it. Instead of that, we can use it to ping our links to get them indexed faster.
Scrapebox – Addons
By default, Scrapebox allows you to use a lot of different add-ons to get more and more from your links. You can find them by clicking “Addons” in the top menu in the main interface. Here is our list of addons:
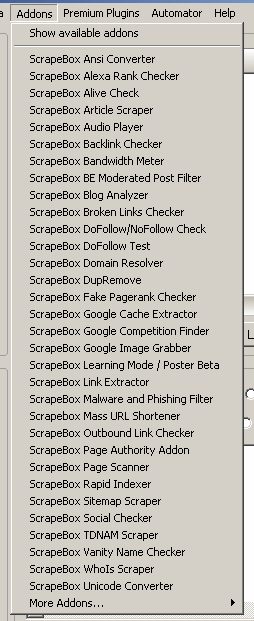
To get more addons You can click on “Show available addons”. Also, remember about premium plugins, which can boost your SEO a lot.
Keyword Scraper – the very beginning of your link building
One of the most massive things in Scrapebox that I use all the time is the integrated Google suggested keywords scraper. It works very simply and allows you to get a list of keywords you should definitely use while optimizing your website content or preparing a new blog post very, very quickly. To do this, just click on the “Scrape” button in the “Harvester” box and select “Keyword Scraper”. You will see a Keyword Scraper window like this one:
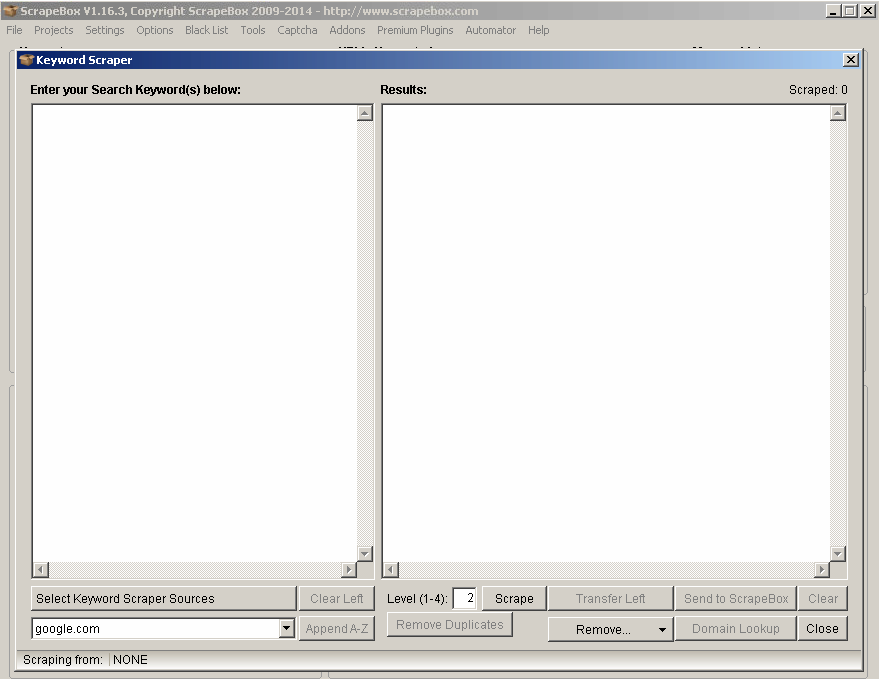
The fun starts right now. On the left side, simply put a list of keywords related to your business or blog and select Keyword Scraper Sources. Later, select the search engine you want to have research done on and hit the “Scrape” button.
As you can see on the screenshot above, you can also select the total “level” for the keyword scraper. For most keyword research tasks, it’s okay to have it on 2, but when it’s specific for each niche you want to target (for example for cooking blogs, it should be level 4 to get more keywords related to specific recipes or kitchen tips and tricks), you can adjust it up to 4. Remember that the higher level you choose, the longer it will take to see results.
After that, do a quick overview of the results you’ve got – if you see some superfluous keywords you don’t want to have in your keywords list, use “Remove” from the drop-down list to remove keywords containing/not containing specified string or entries from a specified source.
If the list is ready – you can send it to ScrapeBox for further usage or just copy and save to your notepad for later.
Now: let’s start our Outreach – scrape URLs with Scrapebox
So: we have our keyword research done (after checking the total amount of traffic that keywords can bring to your domain) – now let’s see if we can get some interesting links from specified niche websites.
After sending our URL list to ScrapeBox we can now start searching for specified domains we would like to get links from.
Footprints – what they are and how to build them
Footprints are (in a nutshell) pieces of code or sentences that appear in a website’s code or in text. For example, when somebody creates a WordPress blog, he has “Powered by WordPress” in his footer by default. Each CMS can have its very own footprints connected both with content or the URL structure. To learn more about footprints, you should test top Content Management Systems or forum boards to check if they index any repeatable pieces of code.
How to build footprints for ScrapeBox
Firstly, learn more about Google Search Operators. For your basic link building tasks you should know and understand these three search operators:
- Inurl: – shows URLs containing a specified string in their address
- Intitle: – shows URLs that have a title optimized for a specified text string
- Site: – lists domains/URLs/links from a specified domain, ccTLD etc.
So if you already know this, do a test search answering questions related to your business right now:
- Do I need do-follow links from blogs and bloggers related to my niche?
- Do I need backlinks from link directories to boost my SEO for one specified money keyword?
- Should these links be do-follow only?
- On which platforms I can easily share my product/services and why?
Got it? Nice! Now let’s move to the next step – creating our footprint:
So let’s say that you are the owner of a marketing blog related to CPC campaigns and conversion rate optimization. The best idea to get new customers for your services is:
- Manual commenting on specified blogs
- Creating and posting guest posts on other marketing blogs related to your business
- Being in top business link directories which allow you to post a lot information about your business
Let’s state that we need top 100 links where we can post a comment/get in touch with bloggers and contact them for any guest postings.
From our experience and after we did keyword research with Keyword Scraper in ScrapeBox, we’ve noticed that the top platform for blogging about marketing is WordPress – both on our own domain and on free wordpress.com platform.
To get the top 100 blogs related to our needs you can simply use:
“Powered by WordPress” + AdWords AND site:.com
This means that we want to search for WordPress blogs on Polish TLD domains with “AdWords” in every single part of the site. However, the results may not be so well-targeted if you fail to use advanced operators you can use search operators where a specified string can be found.
Use footprints in ScrapeBox
Now, after you’ve learned the basics of footprints, you can use them to get specific platforms that will allow you to post a link to your website (or find new customers if you would like to guest blog sometimes).
To do that, simply put them here:
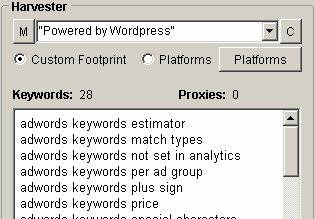
You can combine footprints with advanced search engine commands like site:, inurl or intitle to get only these URLs.
Advanced search operators and footprints have to be connected with the keywords we want to target so as to find more, better pages to link from.
For example, you can search only for .com domains (site:.com) containing the specified keyword in URL (inurl) and title (intitle). Now the URL list will be shorter, but it will contain only related keywords matching our needs.
Expert’s Tip:
For your product or service outreach, you can harvest a lot of interesting blogs hosted on free blog network sites like WordPress.com, Blogspot.com or your language-related sites. Links from these pages will have different IP addresses, so they can be really valuable for your rankings.
Find Guest Blogging opportunities using ScrapeBox
By using simple footprints like:
- Site:
- Allintitle:
- “guest blogger” or “guest post” (to search only for links where somebody posted a guest post already – you can also use the allinurl search operator because a lot of blogs have a “guest posts” category which can be found in its URL structure)
Later, combine it with your target keywords and get ready to mail and post fresh guest posts to share your knowledge and services with others!
Check the value of the harvested links using ScrapeBox
Now, when your keyword research is done and you have harvested your very first links list, you can start by checking some basic information about the links. Aside from ScrapeBox, you will also need MozAPI.
Start with trimming to domain
In general, our outreach is supposed to help us build relationships and find customers. This means that you shouldn’t be only looking at a specific article, but rather the whole domain in general. To do that, select the “Trim to root” option from the Manage Lists box:
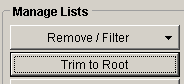
Later, remove duplicates by clicking the Remove/Filter button and select “Remove duplicate URLs”.
Check Page Rank in ScrapeBox
Start with checking Page Rank – even if it’s not the top-ranking factor right now, it still provides basic information about the domain. If the domain has a page rank higher than 1 or 2, this means that it’s trusted and has links from other related/hight PR sources.
To check Page Rank in ScrapeBox, simply click on “Check Page Rank” button and select “Get domain Page Rank”:
To be 100% sure that each domain legit PR – use “ScrapeBox Fake Page Rank Checker”. You can find it in the Addons Section in your ScrapeBox main window.
Check Domain Authority in ScrapeBox
I tend to say that it’s not a good idea to believe in any 3rd party tools results about Link Trust (because it’s hard to measure if the link is trusted or not), although it’s another great sign if a link’s every single result is “green”.
To check Domain Authority in ScrapeBox you can use the Page Authority addon. You can find it in your Addons list in ScrapeBox. To get it to work you will have to get your very own Moz API information (the window will appear after you select the addon).
This provides a quick overview of your links list. You can get information about the Page/Domain Authority, MozRank, and the amount of external links pointing to the domain/page. With that, you can see if a URL is worthy of your link-building tactics and all the work you plan to put in or not.
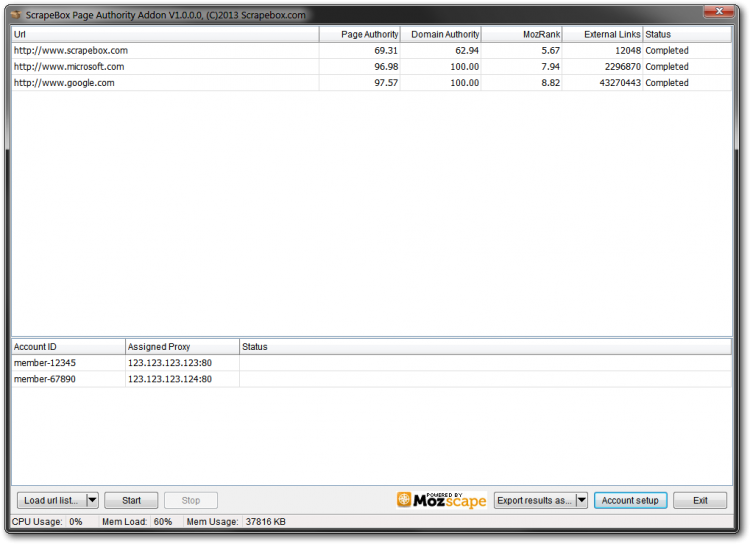
Remember: Do not rely on MozRank or Page/Domain authority only.
To get top links, try to look for average ones – a lot of backlinks with medium MozRank/Page/Domain authority.
Email scraping from a URL list using ScrapeBox
After you’ve harvested your first link list, you will probably want to get in touch with bloggers to start your outreach campaign. To do this effectively, use the Scrapebox Email Scraper feature. Simply click on the Grab/Check button and select to grab emails from harvested URLs or from a local list:
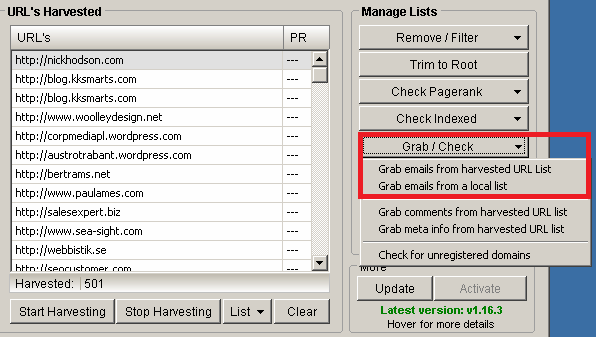
The results may not be perfect, but they can really give you a lot of useful information. You can export data to a text file and sort them by email addresses to find connections between domains.
Merge and remove duplicates using ScrapeBox
If you are running a link detox campaign, it’s strongly recommended to use more than one backlink source to get all of the data needed to lift a penalty, for example. For example, if you have more than 40 thousand in each file, you will probably want to merge them into one file and dig into it later.
To do this quickly, install the DupeRemove addon from the available addon list. After running it, this window will pop up:
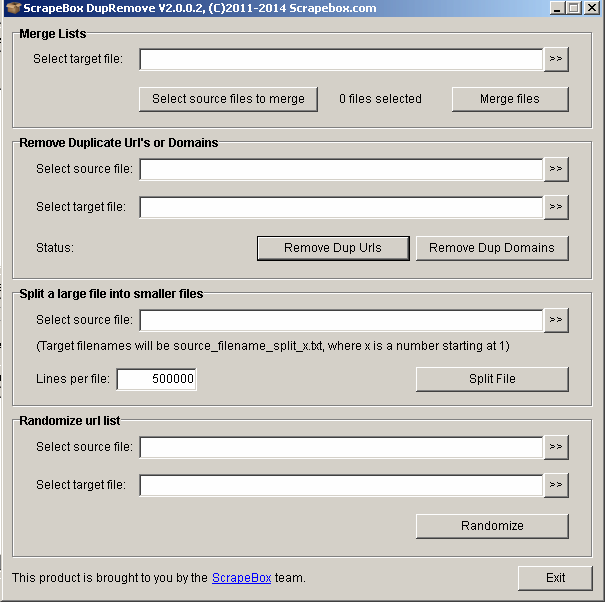
Now simply choose “Select source files to merge” and go directly to the folder with the different text files with URL addresses. Later press “Merge files” to have them all in one text file.
To remove Duplicate URLs or Domains “Select Source file” and choose where to export non duplicated URLs/Domains. Voila! You have one file containing every single backlink you need to analyze.
For those who like to do things in smaller parts – you have the option of splitting a large file into smaller ones. Select your text file with backlinks and choose how many lines per file it should contain. From my point of view, it’s very effective to split your link file into groups of 1000 links per file. It’s very comfortable and gives you the chance to manage your link analysis tasks.
ScrapeBox Meta Scraper
ScrapeBox allows you to scrape titles and descriptions from your harvested list. To do that, choose the Grab/Check option then, from the drop-down menu, “Grab meta info from harvested URLs”:
Here, you can take a look at some example results:
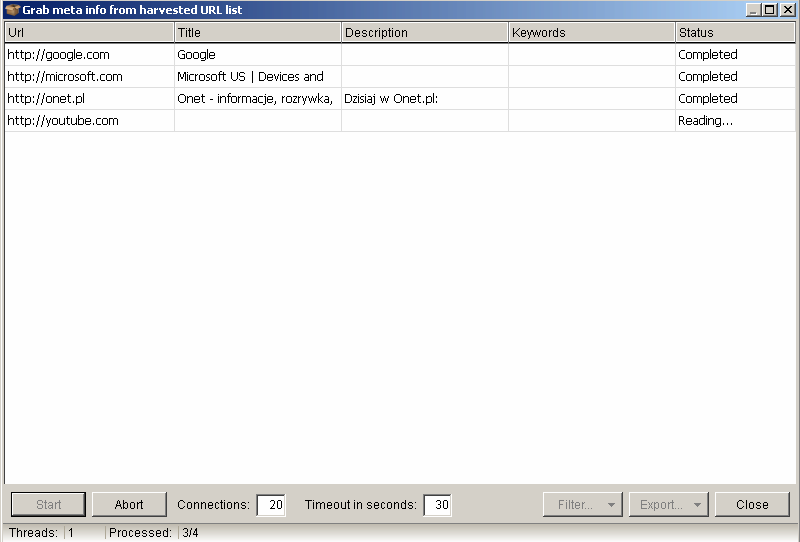
You can export this data to a CSV file and use it to check how many pages use an exact match keyword in the title or optimize it some other way (i.e., do the keywords look natural to Google and not Made For SEO?).
Check if links are dead or alive with ScrapeBox
If you want to be pretty sure that every single intern/external link is alive you can use the “ScrapeBox Alive Checker” addon. First – if you haven’t done this yet – install the Alive Checker addon.
Later, to use it, head to the Addons list and select ScrapeBox Alive Check.
f you were previously harvesting URLs – simply load them from Harvester. If not, you can load them from the text file.
Now, let’s begin with Options:
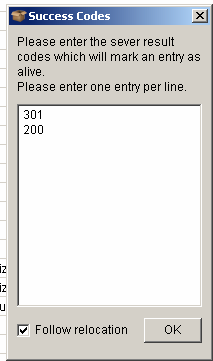
Also, remember to have the checkbox for “Follow relocation” checked.
The results can be seen here:
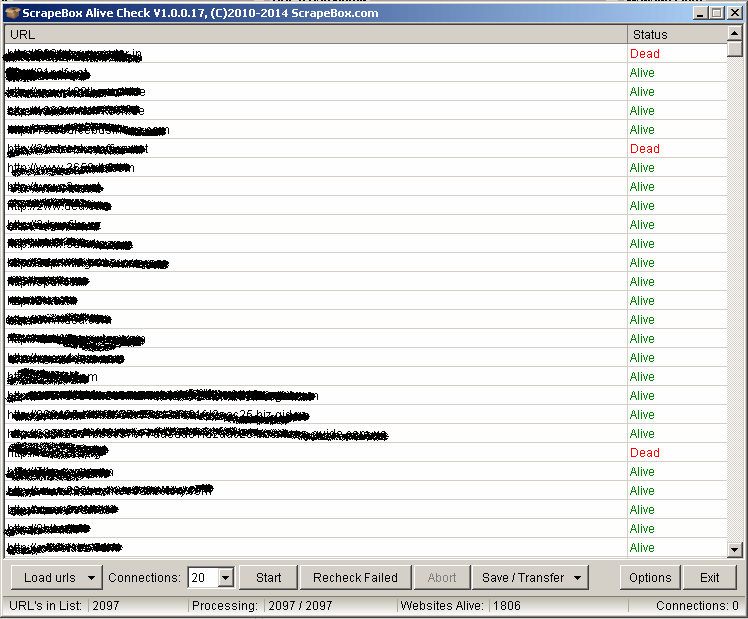
If a link returns HTTP status code different than 301 or 200 it means “Dead” for ScrapeBox.
Check which internal links are not indexed yet
So if you are working on some big onsite changes connected with the total amount of internal pages you will probably want to be pretty sure that Google re-indexes everything. To ensure that everything is as it should be, you can use Screaming Frog, SEO Spider, and ScrapeBox.
So start crawling your page in Screaming Frog, using the very basic setup in the crawler setting menu:
f you are a crawling huge domain – you can use a Deep Crawl tool instead of the Screaming Frog SEO Spider.
Later, when your crawl is done, save the results in the .csv file, open it, and copy it to Clipboard or export it to a .txt file . Import it with one click in ScrapeBox:
When your import is done, simply hit the Check Indexed button and select the Google Indexed option.
Remember to set up the Random Delay option for indexing and checking and the total amount of connections based on your internet connection. Mostly, I use 25 connection and Random Delay between each query sent by ScrapeBox to be sure that my IP/Proxy addresses won’t be blocked by Google.
After that, you will get a pop up with information about how many links are indexed or not, and there will be an extra column added to your URLs harvested box with information about whether they are Indexed or not:

You can export unindexed URLs for further investigation.
Get more backlinks straight from Google using ScrapeBox
“Some people create free templates for WordPress and share them with others to both help people have nicely designed blogs and obtain free dofollow links from a lot of different TLDs.”
Sometimes it’s not enough to download backlink data from Google Webmaster Tools or some other software made for that (although Bartosz found a real nice “glitch” in Webmaster Tools to get more links).
In this case – especially when you are fighting a manual penalty for your site and Google has refused to lift it – go deep into these links and find a pattern that is the same for every single one.
Don’t let a Google penalty ruin your online presence. Take advantage of our Google penalty recovery services to get your website back on track and regain your rankings.
For example – if you are using automatic link building services with spun content, sometimes you can find a sentence or string that is not spun. You can use it as a footprint, harvest results from Google, and check if your previous disavow file contained those links or not.
Take advantage of link risk management to reevaluate your backlink strategy.Need help with disavowing spammy backlinks?
And another example – some people create free templates for WordPress and share them with others to both help people have nicely designed blogs and obtain free dofollow links from a lot of different TLDs. Here is an example:
“Responsive Theme powered by WordPress” site:.com
This returns every single .com domain using the kind of theme from Cyberchimps. If you will combine it with the keywords you were linking to your site, you will probably get a very big, nice, WordPress blog list. You can combine it with keywords you want to target to get more related and 100% accurate results.
Check external links on your link lists
After you have done your first scrape for custom-made footprint it’s good to know what is the quality of links you have found. And once again – ScrapeBox and its amazing list of Addons will help you!
“Outbound Link Checker” is an addon that will check links line by line and list both internal and external links. Because addon works fine supports multithread technology you can check thousands of links at the same time.
To use “Outbound Link Checker” go to your Addons list and select Outbound Link Checker:
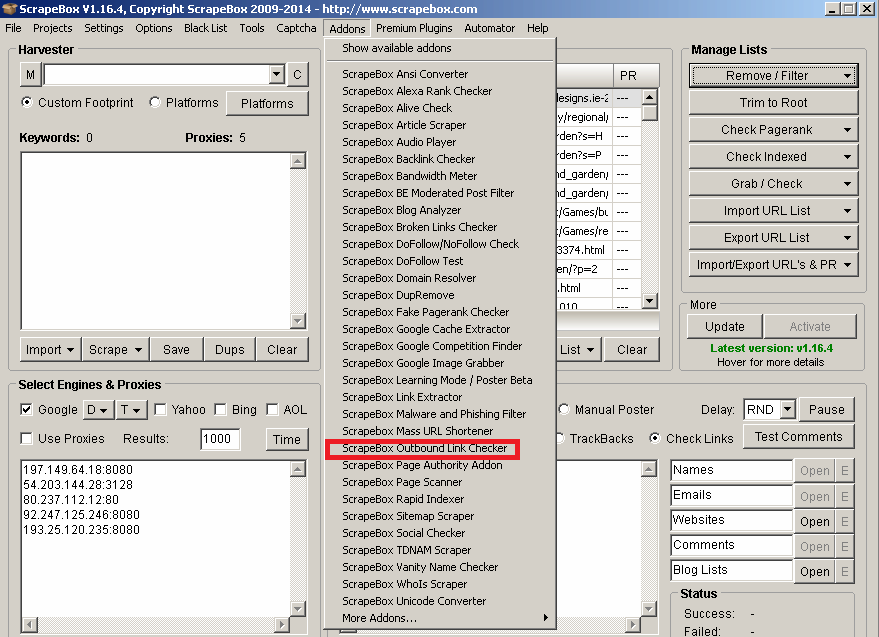
Next, choose to load a URL list from ScrapeBox or from an external file.
After that, you will see something like this:
The magic starts now – simply press the “Start” button.
Voila!
Results?
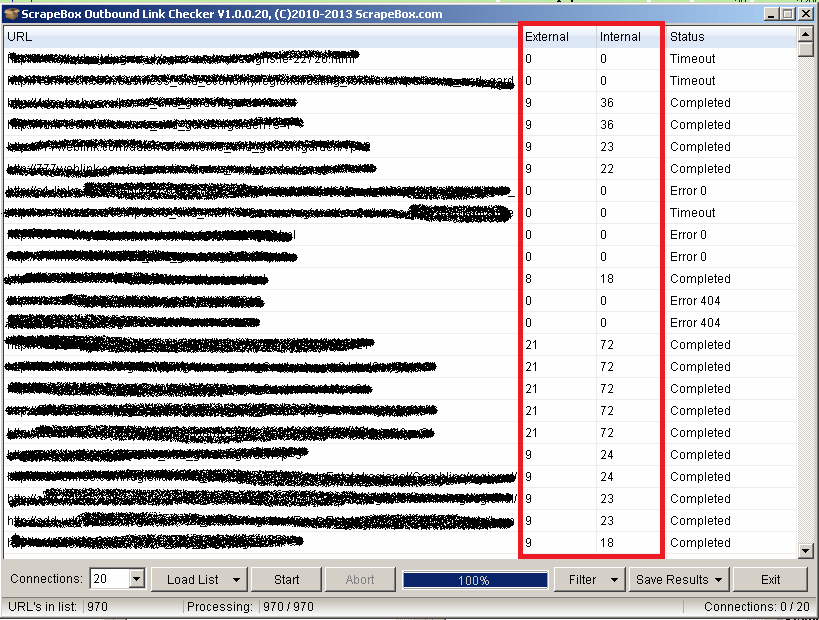
Now you can filter the results if they contain more than X outgoing links. Later, you can also check the authority of those links and how valuable they are.
Short Summary
As you can see – ScrapeBox in the Penguin era is still a powerful tool that will speed up your daily SEO tasks if used properly. Even if you do not want to post comments or links manually, it can still help you find links where you can get both traffic and customers.
Contact us if you want to see how a technical SEO agency, which is both White Hat and creative, works!